Giới thiệu
Bạn đã từng tự hỏi cách xử lý dữ liệu XML trong Python như thế nào chưa? Trong thời đại số hóa hiện tại, XML (eXtensible Markup Language) vẫn đóng vai trò quan trọng trong việc lưu trữ và trao đổi dữ liệu giữa các hệ thống. Dù JSON ngày càng phổ biến, XML vẫn được sử dụng rộng rãi trong nhiều lĩnh vực như dịch vụ web, cài đặt ứng dụng, và trao đổi dữ liệu doanh nghiệp.

Python cung cấp nhiều thư viện mạnh mẽ để làm việc với XML, từ thư viện chuẩn ElementTree đến thư viện nâng cao lxml. Mỗi thư viện đều có ưu điểm riêng và phù hợp với các tình huống khác nhau. Bài viết này sẽ hướng dẫn bạn từng bước cách đọc, phân tích cú pháp, chỉnh sửa và trích xuất dữ liệu từ XML một cách hiệu quả.
Qua bài viết này, bạn sẽ nắm vững các kỹ thuật xử lý XML trong Python, từ những thao tác cơ bản nhất đến các kỹ thuật nâng cao như sử dụng XPath và XSLT. Chúng ta sẽ cùng khám phá qua các ví dụ thực tế, giúp bạn áp dụng ngay vào dự án của mình.
Các thư viện Python phổ biến để xử lý XML
xml.etree.ElementTree – Thư viện chuẩn, dễ dùng
ElementTree là thư viện XML được tích hợp sẵn trong Python, không cần cài đặt thêm. Đây là lựa chọn hoàn hảo cho người mới bắt đầu và các dự án đơn giản. Thư viện này có thiết kế nhẹ nhàng, dễ hiểu và cung cấp đầy đủ các chức năng cơ bản để xử lý XML.
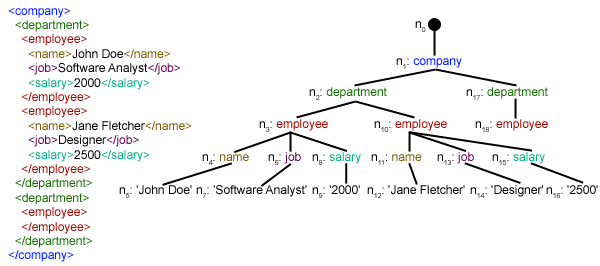
Ưu điểm chính của ElementTree bao gồm tính đơn giản trong cú pháp, tốc độ xử lý nhanh với file XML kích thước vừa phải, và tích hợp hoàn hảo với Python tiêu chuẩn. Bạn có thể dễ dàng đọc file XML, duyệt qua cây phần tử, lấy dữ liệu từ thẻ và thuộc tính. ElementTree sử dụng mô hình cây (tree model) để đại diện cho tài liệu XML, giúp việc truy cập và chỉnh sửa dữ liệu trở nên trực quan.
Các chức năng cốt lõi của ElementTree bao gồm parse() để phân tích cú pháp file XML, find() và findall() để tìm kiếm phần tử, và các phương thức để truy cập text và attributes. Thư viện này cũng hỗ trợ tạo mới và chỉnh sửa cấu trúc XML, rất hữu ích khi bạn cần tao tác dữ liệu động.
Để hiểu rõ hơn về các kiểu dữ liệu trong Python, vui lòng tham khảo bài viết Kiểu dữ liệu trong Python.
lxml – Nâng cao và mạnh mẽ hơn với XPath, XSLT
lxml là thư viện XML mạnh mẽ nhất cho Python, được xây dựng trên libxml2 và libxslt của C. Thư viện này cung cấp hiệu suất vượt trội và nhiều tính năng nâng cao mà ElementTree không có. lxml đặc biệt phù hợp khi bạn cần xử lý file XML lớn hoặc thực hiện các thao tác phức tạp.
Điểm mạnh nổi bật của lxml là hỗ trợ XPath – một ngôn ngữ truy vấn mạnh mẽ cho XML. Với XPath, bạn có thể tìm kiếm và lọc dữ liệu XML một cách linh hoạt, giống như SQL với cơ sở dữ liệu. lxml cũng hỗ trợ XSLT để chuyển đổi XML sang các định dạng khác như HTML, CSV hoặc XML khác.
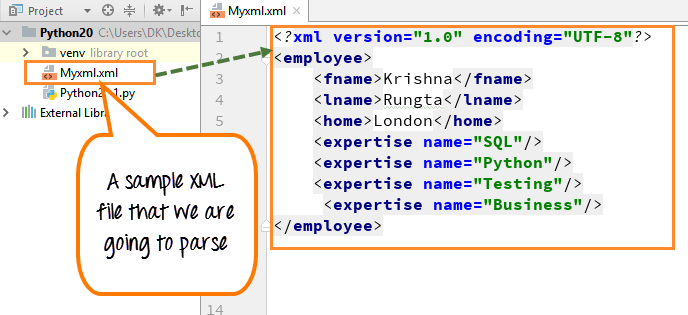
Thư viện này còn có khả năng kiểm tra tính hợp lệ của XML theo XML Schema hoặc DTD, giúp đảm bảo dữ liệu đúng chuẩn. lxml cũng xử lý encoding tốt hơn và có hiệu suất cao hơn khi làm việc với file XML có dung lượng lớn. Tuy nhiên, lxml yêu cầu cài đặt thêm và có thể phức tạp hơn đối với người mới.
Bạn có thể tìm hiểu thêm về cấu trúc phần tử HTML trong bài viết Phần tử HTML là gì? Cấu trúc, các loại phổ biến và ứng dụng trong xây dựng website chuẩn SEO, giúp hiểu cách trình bày tốt hơn khi làm việc với các định dạng HTML và XML.
So sánh nhanh các thư viện
| Tiêu chí |
ElementTree |
lxml |
| Cài đặt |
Tích hợp sẵn |
Cần cài đặt thêm |
| Hiệu suất |
Tốt với file nhỏ |
Xuất sắc với file lớn |
| XPath |
Không hỗ trợ |
Hỗ trợ đầy đủ |
| XSLT |
Không có |
Có |
| Kiểm tra tính hợp lệ |
Cơ bản |
Đầy đủ |
| Độ phức tạp |
Đơn giản |
Nâng cao |
Lựa chọn thư viện phụ thuộc vào yêu cầu cụ thể của dự án. ElementTree phù hợp với các tác vụ đơn giản, còn lxml là lựa chọn tốt nhất cho các ứng dụng phức tạp và chuyên nghiệp.
Hướng dẫn phân tích cú pháp và đọc XML bằng ElementTree
Đọc file và truy cập phần tử gốc
Bước đầu tiên khi làm việc với XML là học cách đọc file và truy cập vào cấu trúc dữ liệu. ElementTree cung cấp cách thức đơn giản và trực quan để thực hiện điều này.
import xml.etree.ElementTree as ET
# Đọc file XML
tree = ET.parse('data.xml')
root = tree.getroot()
print(f"Thẻ gốc: {root.tag}")
print(f"Thuộc tính: {root.attrib}")

Khi bạn gọi ET.parse(), Python sẽ đọc toàn bộ file XML và tạo ra một đối tượng ElementTree. Đối tượng root là điểm bắt đầu để truy cập tất cả dữ liệu trong tài liệu XML. Từ root, bạn có thể duyệt xuống các phần tử con và lấy dữ liệu cần thiết.
Nếu bạn có dữ liệu XML dưới dạng chuỗi thay vì file, có thể sử dụng ET.fromstring() để phân tích cú pháp trực tiếp. Điều này rất hữu ích khi nhận dữ liệu XML từ API hoặc web service.
Bạn có thể tìm hiểu thêm về cách sử dụng Ứng dụng của Python để xử lý dữ liệu từ API và các nguồn khác.
Trích xuất dữ liệu từ thẻ và thuộc tính
Sau khi có được đối tượng root, bạn có thể truy cập vào các phần tử con và lấy dữ liệu. ElementTree cung cấp nhiều phương thức để tìm kiếm và trích xuất thông tin.
# Tìm phần tử đầu tiên
first_child = root.find('customer')
if first_child is not None:
print(f"ID khách hàng: {first_child.get('id')}")
print(f"Tên: {first_child.find('name').text}")
# Tìm tất cả phần tử cùng loại
all_customers = root.findall('customer')
for customer in all_customers:
name = customer.find('name').text
email = customer.find('email').text
print(f"Khách hàng: {name}, Email: {email}")

Phương thức find() trả về phần tử đầu tiên khớp với tên thẻ, trong khi findall() trả về danh sách tất cả phần tử phù hợp. Thuộc tính text cho phép lấy nội dung văn bản bên trong thẻ, còn get() được dùng để lấy giá trị thuộc tính.
Khi làm việc với XML phức tạp có nhiều cấp độ lồng nhau, bạn có thể sử dụng đường dẫn (path) để truy cập trực tiếp đến phần tử mong muốn. Ví dụ: root.find(‘orders/order/items/item’) sẽ tìm phần tử item nằm sâu trong cấu trúc XML.
Trước khi thao tác phức tạp với dữ liệu, bạn nên nắm vững List trong Python để xử lý dữ liệu hiệu quả hơn.
Chỉnh sửa và ghi dữ liệu XML
Thêm, sửa, xóa phần tử và thuộc tính
ElementTree không chỉ cho phép đọc XML mà còn hỗ trợ chỉnh sửa dữ liệu một cách linh hoạt. Bạn có thể thêm phần tử mới, sửa đổi nội dung hiện có, hoặc xóa những phần không cần thiết.
# Thêm phần tử mới
new_customer = ET.SubElement(root, 'customer', id='003')
name_elem = ET.SubElement(new_customer, 'name')
name_elem.text = 'Nguyễn Văn C'
# Sửa đổi thuộc tính
existing_customer = root.find("customer[@id='001']")
if existing_customer is not None:
existing_customer.set('status', 'active')
# Thay đổi nội dung text
name_element = existing_customer.find('name')
name_element.text = 'Tên mới'
# Xóa phần tử
customer_to_remove = root.find("customer[@id='002']")
if customer_to_remove is not None:
root.remove(customer_to_remove)

Khi thêm phần tử mới, ET.SubElement() là cách thuận tiện nhất. Hàm này tạo phần tử con và tự động gắn vào phần tử cha. Bạn có thể chỉ định thuộc tính ngay trong lúc tạo hoặc thêm sau bằng set().
Việc xóa phần tử cần thận trọng vì nó sẽ xóa luôn cả các phần tử con bên trong. Luôn kiểm tra phần tử có tồn tại trước khi thực hiện thao tác xóa để tránh lỗi.
Ghi lại XML sau khi chỉnh sửa
Sau khi hoàn tất các thay đổi, bạn cần lưu lại file XML để các điều chỉnh có hiệu lực. ElementTree cung cấp phương thức write() để xuất dữ liệu ra file.
# Ghi file với encoding UTF-8
tree.write('updated_data.xml',
encoding='utf-8',
xml_declaration=True)
# Tạo XML string để xem trước
xml_string = ET.tostring(root,
encoding='unicode',
method='xml')
print(xml_string)
Tham số encoding rất quan trọng khi làm việc với dữ liệu tiếng Việt. UTF-8 là lựa chọn tốt nhất để đảm bảo hiển thị chính xác. xml_declaration=True sẽ thêm dòng khai báo XML vào đầu file.
Nếu bạn muốn định dạng XML đẹp hơn với indentation, có thể sử dụng thư viện xml.dom.minidom hoặc các công cụ bên ngoài. ElementTree mặc định không thêm khoảng trắng để tiết kiệm dung lượng file.
Xử lý XML nâng cao với lxml
Truy vấn XML bằng XPath
XPath là một trong những tính năng mạnh nhất của lxml, cho phép bạn truy vấn dữ liệu XML với cú pháp linh hoạt và chính xác. XPath hoạt động giống như SQL cho XML, giúp tìm kiếm phần tử dựa trên điều kiện phức tạp.
from lxml import etree
# Load XML với lxml
tree = etree.parse('data.xml')
# Các ví dụ XPath cơ bản
customers = tree.xpath('//customer')
active_customers = tree.xpath('//customer[@status="active"]')
customer_names = tree.xpath('//customer/name/text()')
# XPath nâng cao với điều kiện
high_value_orders = tree.xpath('//order[total > 1000000]')
recent_customers = tree.xpath('//customer[registration_date > "2023-01-01"]')
# Lấy phần tử theo vị trí
first_customer = tree.xpath('//customer[1]')[0]
last_order = tree.xpath('//order[last()]')[0]

XPath sử dụng cú pháp đường dẫn tương tự file system. Dấu “//” có nghĩa là tìm kiếm trong toàn bộ tài liệu, trong khi “/” chỉ tìm trong phần tử con trực tiếp. Các điều kiện được đặt trong dấu ngoặc vuông [], cho phép lọc dựa trên thuộc tính, giá trị, hoặc vị trí.
XPath cung cấp nhiều hàm hữu ích như contains(), starts-with(), count(), sum() để xử lý dữ liệu phức tạp. Bạn có thể kết hợp nhiều điều kiện với các toán tử logic and, or để tạo ra truy vấn mạnh mẽ.
Để xem thêm về vòng lặp trong Python, giúp xử lý mảng XML hiệu quả hơn, bạn có thể đọc thêm Vòng lặp trong Python và các bài viết liên quan như Vòng lặp for trong Python, Vòng lặp while trong Python.
Kiểm tra tính hợp lệ và chuyển đổi XML bằng XSLT
lxml hỗ trợ kiểm tra tính hợp lệ của XML theo các chuẩn như XML Schema và DTD. Điều này đảm bảo dữ liệu XML tuân theo cấu trúc và quy tắc định trước.
# Kiểm tra với XML Schema
from lxml import etree
# Load schema
with open('customer_schema.xsd', 'r') as schema_file:
schema_doc = etree.parse(schema_file)
schema = etree.XMLSchema(schema_doc)
# Kiểm tra tính hợp lệ
xml_doc = etree.parse('customer_data.xml')
is_valid = schema.validate(xml_doc)
if not is_valid:
print("Lỗi validation:")
for error in schema.error_log:
print(f"Dòng {error.line}: {error.message}")
XSLT (Extensible Stylesheet Language Transformations) cho phép chuyển đổi XML sang các định dạng khác. Đây là công cụ mạnh mẽ để biến đổi dữ liệu XML thành HTML, CSV, hoặc XML khác có cấu trúc khác.
# Chuyển đổi XML sang HTML bằng XSLT
xslt_doc = etree.parse('transform.xsl')
transform = etree.XSLT(xslt_doc)
xml_doc = etree.parse('data.xml')
result = transform(xml_doc)
# Lưu kết quả
with open('output.html', 'wb') as output_file:
output_file.write(etree.tostring(result, pretty_print=True))
XSLT đặc biệt hữu ích khi bạn cần tạo báo cáo HTML từ dữ liệu XML hoặc chuyển đổi định dạng dữ liệu giữa các hệ thống khác nhau.
Xử lý XML từ các nguồn khác nhau
Trong thực tế, dữ liệu XML không chỉ đến từ file mà còn từ nhiều nguồn khác như API, web service, hoặc cơ sở dữ liệu. Python cung cấp các cách linh hoạt để xử lý XML từ những nguồn này.
import requests
import xml.etree.ElementTree as ET
# Lấy XML từ API
response = requests.get('https://api.example.com/data.xml')
if response.status_code == 200:
root = ET.fromstring(response.content)
# Xử lý dữ liệu như bình thường
# Xử lý XML string từ database
xml_string = """
Laptop Dell
15000000
"""
root = ET.fromstring(xml_string)

Khi làm việc với XML từ web service, bạn cần chú ý đến encoding và xử lý lỗi mạng. Sử dụng try-except để bắt các ngoại lệ có thể xảy ra trong quá trình download hoặc phân tích cú pháp.
Với dữ liệu XML lớn từ streaming source, bạn có thể sử dụng iterparse() để xử lý từng phần thay vì load toàn bộ vào bộ nhớ. Điều này giúp tiết kiệm RAM và tăng hiệu suất xử lý.
Bạn có thể tham khảo thêm về Hàm trong Python để xây dựng các hàm hữu ích phục vụ xử lý XML.
Các lỗi thường gặp và cách khắc phục
Lỗi phân tích cú pháp (ParseError)
ParseError là lỗi phổ biến nhất khi làm việc với XML. Lỗi này xảy ra khi cấu trúc XML không hợp lệ hoặc có vấn đề về encoding.
import xml.etree.ElementTree as ET
try:
tree = ET.parse('data.xml')
except ET.ParseError as e:
print(f"Lỗi phân tích cú pháp: {e}")
print(f"Dòng {e.lineno}, cột {e.offset}")

Các nguyên nhân thường gây ParseError bao gồm: thẻ không được đóng đúng cách, ký tự đặc biệt không được escape, encoding không đúng, hoặc có ký tự không hợp lệ trong XML. Để khắc phục, hãy kiểm tra cẩn thận cấu trúc XML và đảm bảo encoding đúng.
Lỗi truy cập phần tử không tồn tại
Một lỗi khác thường gặp là cố gắng truy cập vào phần tử hoặc thuộc tính không tồn tại, dẫn đến AttributeError hoặc NoneType error.
# Cách xử lý an toàn
customer = root.find('customer')
if customer is not None:
name_elem = customer.find('name')
name = name_elem.text if name_elem is not None else 'Không có tên'
# Hoặc sử dụng get() với giá trị mặc định
email = customer.findtext('email', 'Không có email')
customer_id = customer.get('id', 'Không có ID')
Luôn kiểm tra phần tử có tồn tại trước khi truy cập properties. Sử dụng findtext() và get() với giá trị mặc định để tránh lỗi NoneType.
Các lưu ý và bí quyết khi làm việc với XML trong Python
Khi làm việc với XML trong Python, có một số bí quyết quan trọng giúp bạn tránh được những cạm bẫy phổ biến và tối ưu hiệu suất.

Đầu tiên, luôn kiểm tra encoding trước khi đọc và ghi file XML. Tiếng Việt có nhiều ký tự đặc biệt, nên UTF-8 là lựa chọn an toàn nhất. Khi ghi file, hãy chỉ định rõ encoding để tránh lỗi hiển thị.
Thứ hai, ưu tiên sử dụng lxml khi xử lý file XML lớn hoặc cần các tính năng nâng cao như XPath. ElementTree phù hợp với các tác vụ đơn giản, nhưng lxml có hiệu suất và tính năng vượt trội.
Thứ ba, không nên lạm dụng quá nhiều thao tác chỉnh sửa làm XML trở nên phức tạp. Hãy thiết kế cấu trúc XML hợp lý từ đầu và tránh tạo ra những cấu trúc sâu quá mức cần thiết.
Cuối cùng, luôn sử dụng try-except để quản lý lỗi. XML có thể đến từ nhiều nguồn khác nhau và không phải lúc nào cũng đảm bảo chất lượng. Xử lý ngoại lệ giúp ứng dụng của bạn ổn định và thân thiện với người dùng.
# Template xử lý XML an toàn
def process_xml_safely(xml_file):
try:
tree = ET.parse(xml_file)
root = tree.getroot()
# Xử lý dữ liệu
for item in root.findall('item'):
name = item.findtext('name', 'Unknown')
value = item.get('value', '0')
print(f"{name}: {value}")
except ET.ParseError as e:
print(f"Lỗi XML: {e}")
except FileNotFoundError:
print("Không tìm thấy file XML")
except Exception as e:
print(f"Lỗi không xác định: {e}")

Tham khảo thêm về Toán tử trong Python giúp tối ưu hóa các biểu thức điều kiện và xử lý logic trong quá trình làm việc với XML.
Kết luận
XML trong Python là một công cụ mạnh mẽ và linh hoạt để xử lý dữ liệu cấu trúc. Qua bài viết này, chúng ta đã khám phá từ những kiến thức cơ bản với ElementTree đến các kỹ thuật nâng cao với lxml. Mỗi thư viện đều có vị trí và ứng dụng riêng, tùy thuộc vào yêu cầu cụ thể của dự án.
ElementTree là lựa chọn tuyệt vời cho người mới bắt đầu và các tác vụ đơn giản. Với cú pháp dễ hiểu và tích hợp sẵn trong Python, bạn có thể nhanh chóng đọc, chỉnh sửa và lưu trữ dữ liệu XML. Trong khi đó, lxml mở ra những khả năng vô hạn với XPath, XSLT và kiểm tra tính hợp lệ, phù hợp với các ứng dụng chuyên nghiệp.
Điều quan trọng nhất khi làm việc với XML là hiểu rõ cấu trúc dữ liệu và chọn công cụ phù hợp. Hãy luôn xử lý lỗi một cách cẩn thận, kiểm tra encoding, và tối ưu hiệu suất khi cần thiết. Với những kiến thức đã chia sẻ, bạn có thể tự tin áp dụng XML vào các dự án thực tế một cách hiệu quả.

Hãy thử ngay các ví dụ trong bài để hiểu sâu hơn và rèn luyện kỹ năng. Đừng ngại thử nghiệm với những tình huống khác nhau – đó là cách tốt nhất để thành thật trong việc xử lý XML. Theo dõi BUIMANHDUC.COM để cập nhật thêm nhiều bài viết về Python và các kỹ thuật lập trình hữu ích khác.
Bạn có câu hỏi nào về xử lý XML trong Python không? Hãy chia sẻ trong phần bình luận để chúng ta cùng thảo luận và học hỏi nhé!
Chia sẻ Tài liệu học Python

