Machine learning đang thay đổi cách thế giới xử lý dữ liệu và ra quyết định. Từ việc gợi ý phim trên Netflix đến xe tự lái, công nghệ này đã len lỏi vào mọi ngóc ngách cuộc sống. Nhưng bạn có thực sự hiểu machine learning hoạt động như thế nào?
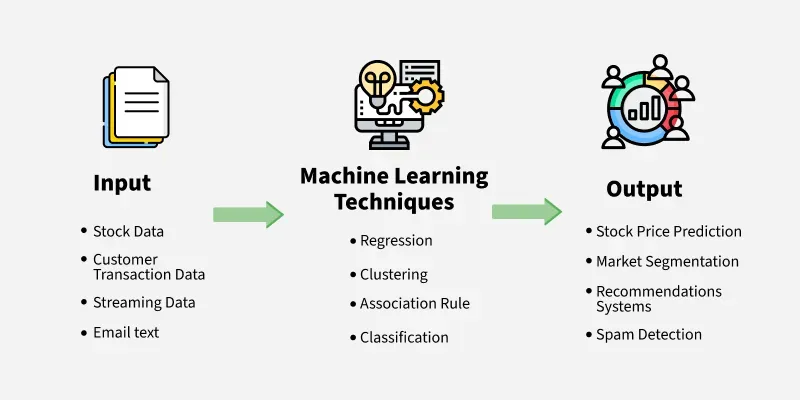
Nhiều người vẫn chưa hiểu rõ machine learning là gì và cách nó vận hành. Họ nghe thuật ngữ này xuất hiện khắp nơi nhưng không nắm được bản chất. Điều này dẫn đến những hiểu lầm về khả năng và giới hạn của công nghệ.
Bài viết này sẽ giải thích định nghĩa, cách hoạt động, loại thuật toán, quy trình triển khai, ứng dụng thực tế cùng lợi ích và thách thức. Tôi sẽ chia sẻ kiến thức từ kinh nghiệm thực tế, không chỉ lý thuyết suông.
Chúng ta sẽ lần lượt khám phá từng khía cạnh quan trọng để bạn hiểu rõ tổng quan về machine learning. Từ khái niệm cơ bản đến ứng dụng trong kinh doanh, tôi sẽ hướng dẫn bạn từng bước một cách dễ hiểu nhất.
Machine learning là gì?
Định nghĩa machine learning
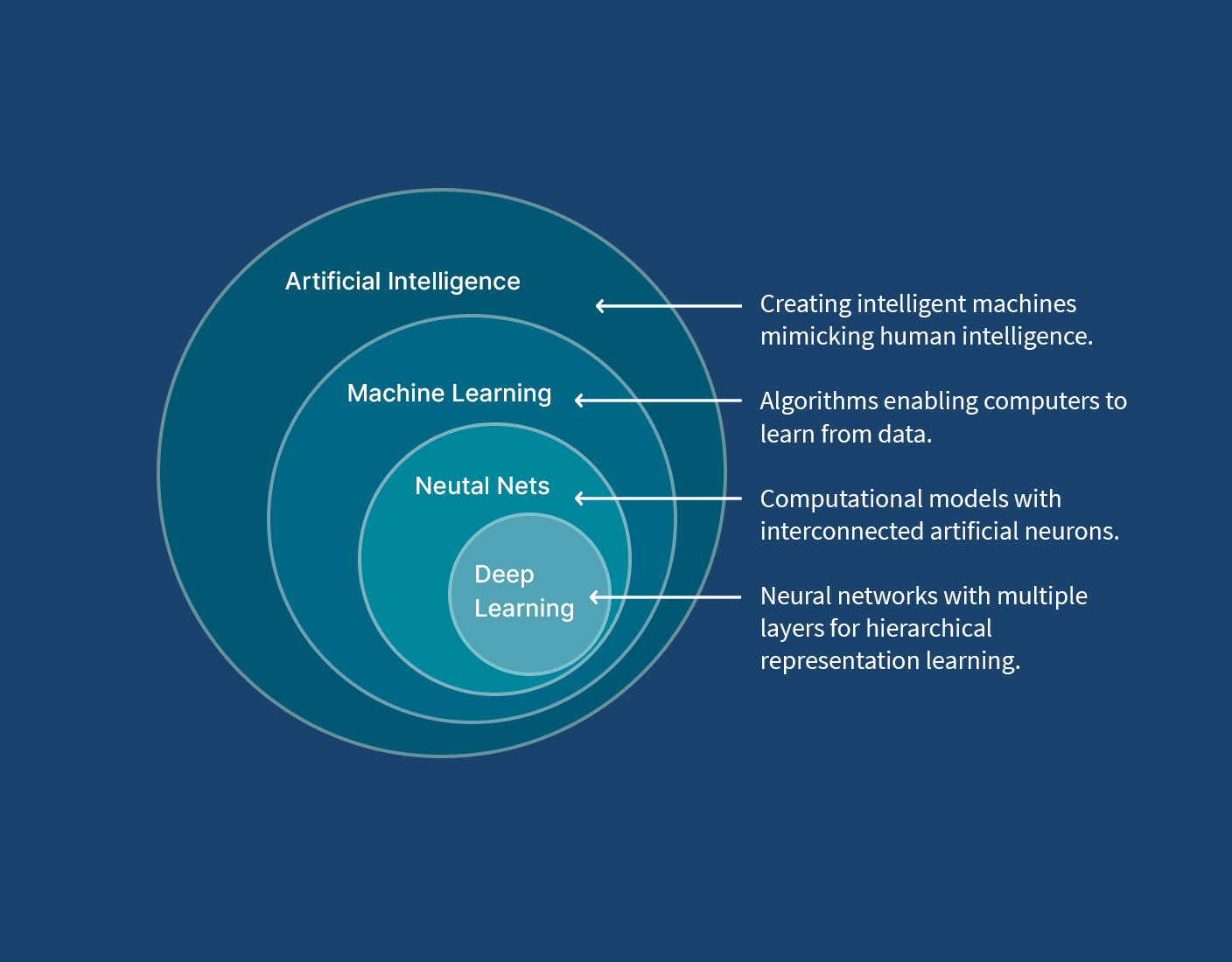
Machine learning, hay học máy, là một nhánh của trí tuệ nhân tạo cho phép máy tính học từ dữ liệu mà không cần lập trình cụ thể cho từng tác vụ. Thay vì viết code cho mọi tình huống, chúng ta cung cấp dữ liệu để máy tự tìm ra quy luật. Xem thêm về ngành khoa học máy tính để hiểu rõ hơn nền tảng của machine learning.
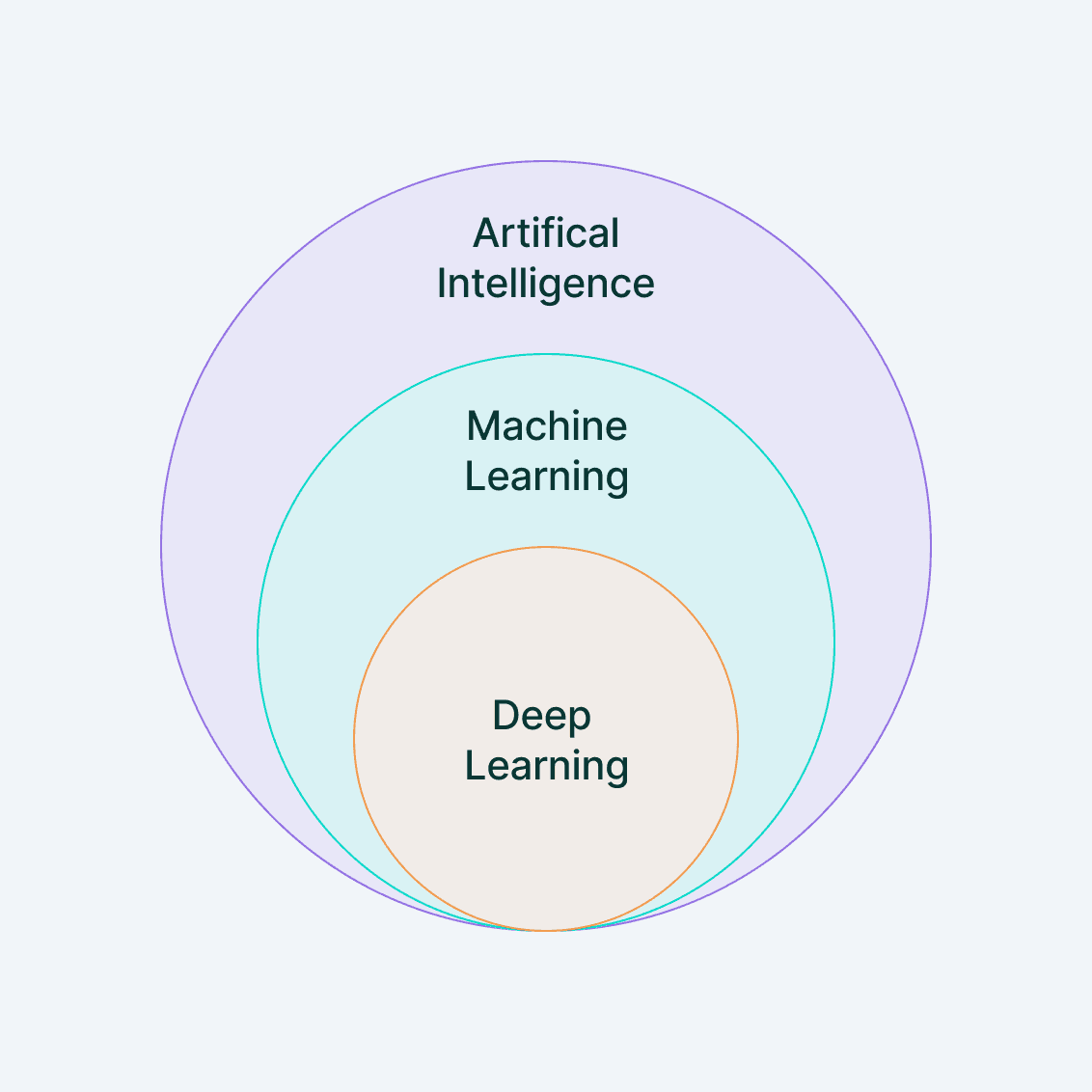
Khác với lập trình truyền thống, machine learning không yêu cầu bạn viết từng bước logic. Ví dụ, để nhận diện mèo trong ảnh, lập trình truyền thống cần mô tả chi tiết: “Nếu có tai nhọn, râu dài, mắt tròn thì là mèo.” Machine learning chỉ cần xem hàng nghìn ảnh mèo và tự học cách phân biệt.
Điểm mạnh của machine learning nằm ở khả năng xử lý dữ liệu phức tạp. Máy tính có thể phát hiện những mẫu (pattern) mà con người khó nhận ra. Điều này đặc biệt hữu ích khi làm việc với Big Data.
Tuy nhiên, machine learning không phải là ma thuật. Nó cần dữ liệu chất lượng, thời gian huấn luyện và hiểu biết chuyên môn để triển khai hiệu quả. Nhiều dự án thất bại vì kỳ vọng quá cao hoặc thiếu chuẩn bị kỹ lưỡng.
Cách thức hoạt động của machine learning
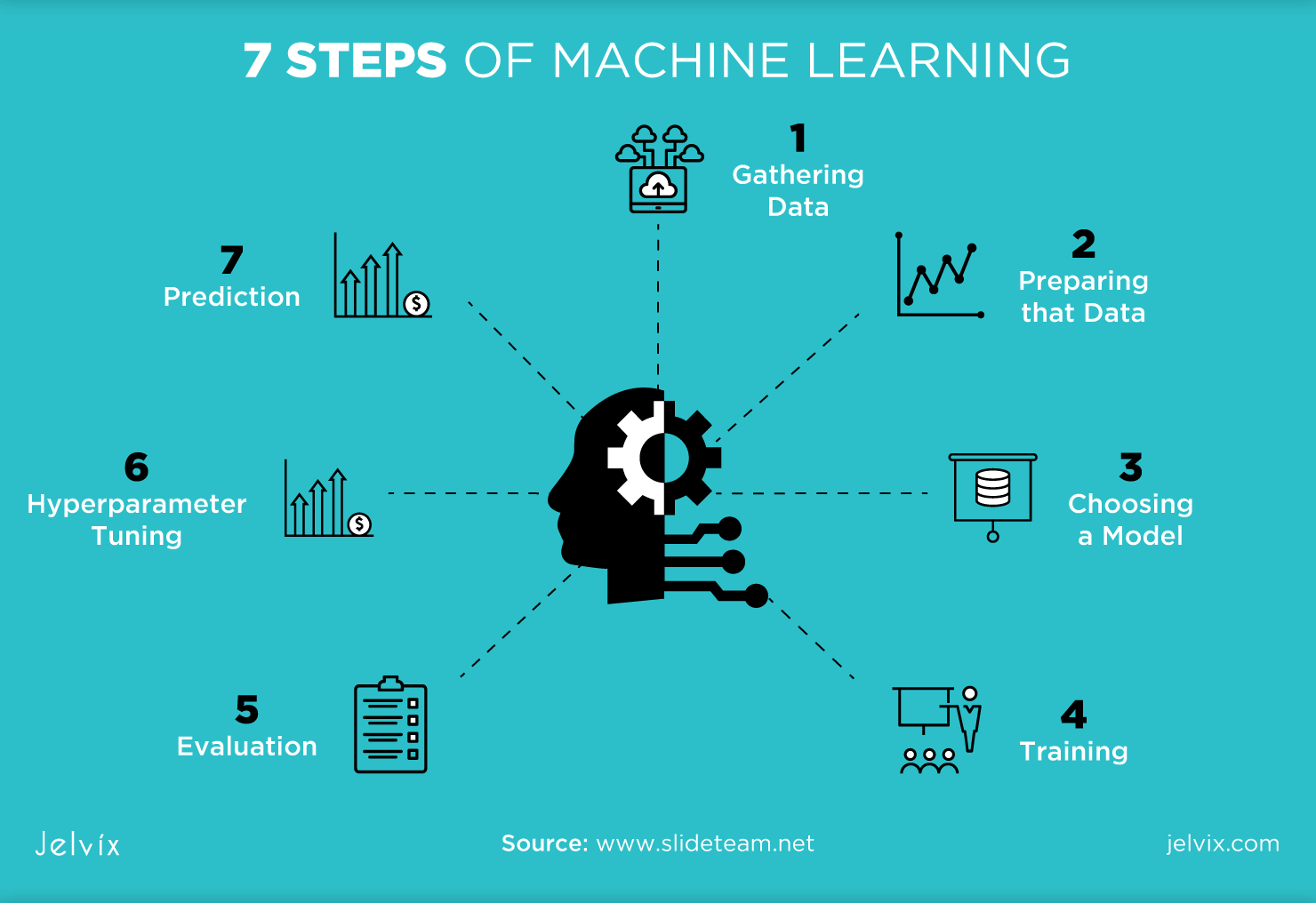
Quá trình học từ dữ liệu của machine learning diễn ra theo ba giai đoạn chính. Đầu tiên là thu thập và chuẩn bị dữ liệu. Dữ liệu phải đại diện, đa dạng và đủ lớn để mô hình học được các quy luật tổng quát.
Giai đoạn thứ hai là huấn luyện mô hình. Máy tính sẽ tìm kiếm các mẫu ẩn trong dữ liệu thông qua thuật toán. Quá trình này giống như việc một đứa trẻ học nhận biết động vật qua nhiều hình ảnh khác nhau.
Mô hình dự đoán và tối ưu là kết quả cuối cùng. Khi đã học xong, mô hình có thể đưa ra dự đoán cho dữ liệu mới chưa từng thấy. Độ chính xác phụ thuộc vào chất lượng dữ liệu huấn luyện và sự phù hợp của thuật toán.
Điều quan trọng là mô hình cần được kiểm tra và điều chỉnh liên tục. Thế giới thực luôn thay đổi, nên mô hình machine learning cũng cần cập nhật để duy trì hiệu quả. Đây là một quy trình tuần hoàn, không phải làm một lần xong việc. Để biết thêm về các công cụ AI hỗ trợ quản lý và vận hành mô hình, bạn có thể tham khảo bài viết liên quan.
Các loại thuật toán machine learning phổ biến
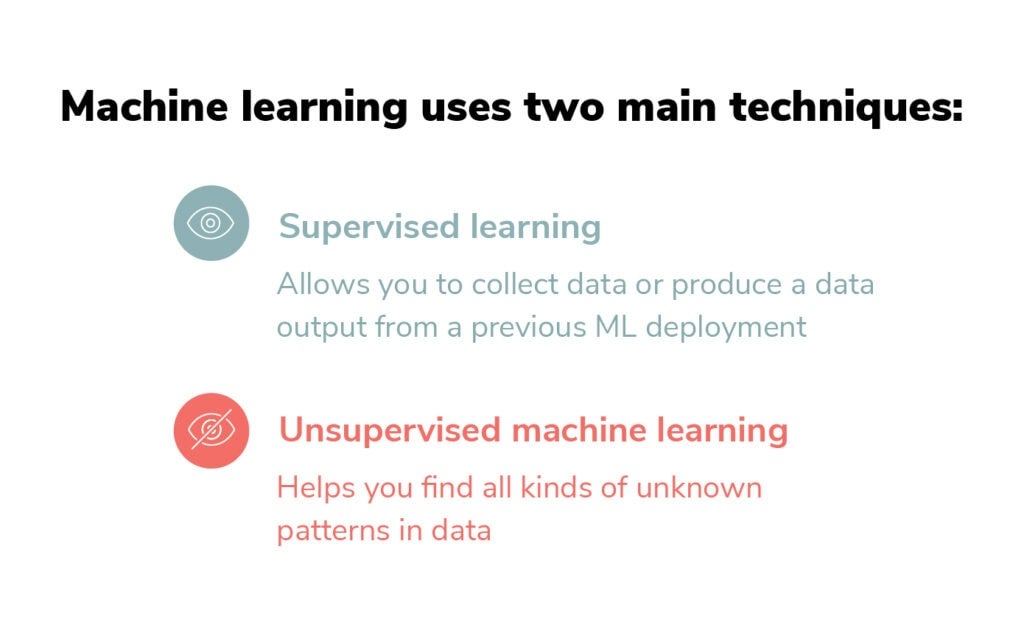
Thuật toán học có giám sát (Supervised Learning)
Học có giám sát là loại thuật toán phổ biến nhất trong machine learning. Nó hoạt động như việc có một giáo viên chỉ bảo: bạn cung cấp cả dữ liệu đầu vào và kết quả mong muốn để máy học cách ánh xạ.

Ví dụ thực tế dễ hiểu là dự đoán giá nhà. Bạn cung cấp thông tin về diện tích, vị trí, số phòng cùng với giá thực tế của hàng nghìn căn nhà. Mô hình sẽ học mối quan hệ giữa các yếu tố này và giá cả để dự đoán giá nhà mới.
Phân loại email spam là ứng dụng khác của học có giám sát. Hệ thống học từ hàng triệu email đã được gắn nhãn “spam” hoặc “không spam”. Khi email mới đến, nó có thể tự động phân loại dựa trên nội dung và đặc điểm đã học.
Trong y tế, học có giám sát giúp chẩn đoán bệnh từ ảnh X-quang. Bằng cách học từ hàng ngàn ảnh có kết quả chẩn đoán từ bác sĩ, máy tính có thể hỗ trợ phát hiện bệnh với độ chính xác cao, đặc biệt hữu ích ở vùng thiếu bác sĩ chuyên khoa.
Bạn có thể tham khảo thêm về Chatbot – một ứng dụng trong lĩnh vực xử lý dữ liệu có giám sát và tương tác tự động.
Thuật toán học không giám sát (Unsupervised Learning) và học tăng cường (Reinforcement Learning)
Học không giám sát như việc để máy tự khám phá mà không có ai chỉ bảo. Bạn chỉ cung cấp dữ liệu mà không có nhãn kết quả. Máy phải tự tìm ra các nhóm, mẫu hoặc cấu trúc ẩn trong dữ liệu.
.png?width=1200&height=627&name=Machine%20learning%20(1).png)
Ví dụ điển hình là phân nhóm khách hàng. Công ty có dữ liệu về hành vi mua sắm nhưng không biết khách hàng thuộc nhóm nào. Machine learning sẽ tự động chia khách hàng thành các nhóm dựa trên pattern mua sắm, giúp công ty hiểu rõ từng phân khúc.
Học tăng cường hoạt động như việc huấn luyện thú cưng. Máy học thông qua thử-sai, nhận phần thưởng khi làm đúng và hình phạt khi sai. Không cần dữ liệu huấn luyện trước, mà học trực tiếp từ tương tác với môi trường.
Game là lĩnh vực ứng dụng mạnh của học tăng cường. AlphaGo đánh bại kỳ thủ cờ vây thế giới bằng cách chơi hàng triệu ván cờ với chính mình. Xe tự lái cũng sử dụng học tăng cường để quyết định rẽ trái, rẽ phải hay dừng lại trong từng tình huống cụ thể.
Xem thêm về AI Agent, một công nghệ liên quan sử dụng nhiều kỹ thuật học tăng cường trong tự động hóa và tương tác môi trường.
Quy trình triển khai machine learning trong thực tế
Thu thập và xử lý dữ liệu
Thu thập dữ liệu chất lượng là bước quan trọng nhất trong machine learning. Dữ liệu kém sẽ cho ra mô hình kém, dù bạn có dùng thuật toán tiên tiến nhất. Quy tắc “rác vào, rác ra” luôn đúng trong lĩnh vực này.
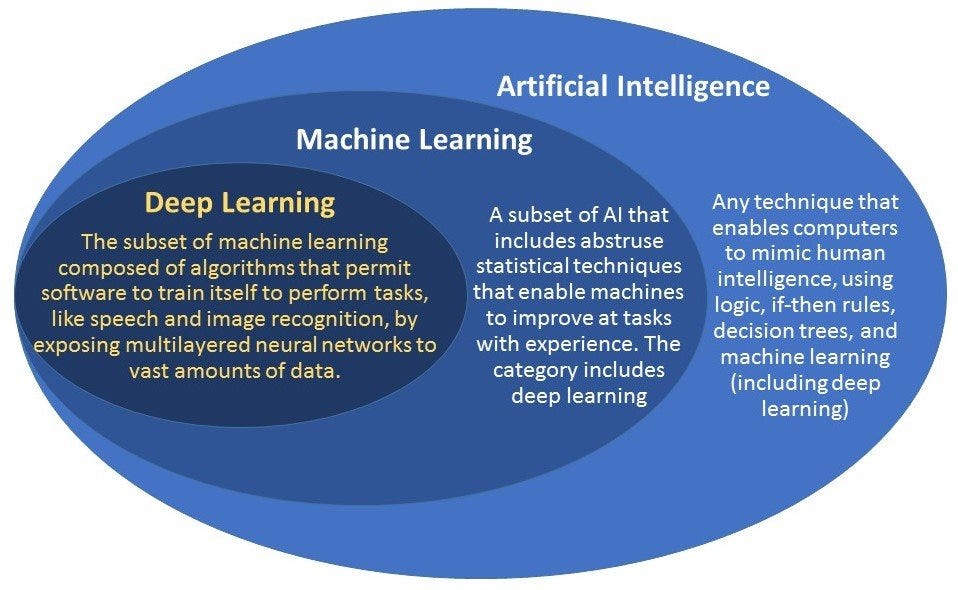
Dữ liệu cần đại diện cho vấn đề thực tế bạn muốn giải quyết. Nếu xây dựng mô hình dự đoán hành vi khách hàng Việt Nam mà chỉ có dữ liệu từ khách hàng Mỹ, kết quả sẽ không chính xác do khác biệt văn hóa và thói quen tiêu dùng.
Số lượng dữ liệu cũng rất quan trọng. Một quy tắc đơn giản là cần ít nhất 100 mẫu dữ liệu cho mỗi tính năng (feature) trong mô hình. Ví dụ, nếu dự đoán giá nhà dựa trên 10 yếu tố, bạn cần ít nhất 1000 mẫu dữ liệu nhà để có kết quả đáng tin cậy.
Làm sạch dữ liệu là bước không thể bỏ qua. Dữ liệu thực tế thường chứa lỗi, thiếu sót hoặc không nhất quán. Bạn cần xử lý các giá trị bất thường, điền vào chỗ trống và chuẩn hóa định dạng. Công việc này có thể chiếm tới 80% thời gian của dự án machine learning.
Để hiểu sâu hơn về vai trò của Data Analyst trong thu thập và xử lý dữ liệu, bạn có thể tham khảo bài viết chi tiết.
Xây dựng mô hình và đánh giá hiệu quả
Sau khi có dữ liệu sạch, bước tiếp theo là chia dữ liệu thành ba phần: huấn luyện (70%), xác thực (15%) và kiểm tra (15%). Đây là cách đảm bảo mô hình không chỉ học thuộc lòng dữ liệu mà thực sự hiểu được quy luật tổng quát.

Quá trình huấn luyện là lúc mô hình học từ dữ liệu huấn luyện. Máy tính sẽ điều chỉnh các tham số nội bộ để tối thiểu hóa sai số. Giống như việc học lái xe, ban đầu sẽ vụng về nhưng dần dần thành thạo qua nhiều lần luyện tập.
Đánh giá hiệu quả mô hình không chỉ xem độ chính xác. Bạn cần xem xét nhiều chỉ số khác như precision, recall, và F1-score. Ví dụ, mô hình phát hiện ung thư có thể có độ chính xác 95% nhưng bỏ sót 50% ca bệnh thực tế – điều này rất nguy hiểm.
Cross-validation là kỹ thuật quan trọng để đánh giá độ ổn định của mô hình. Thay vì chia dữ liệu một lần, bạn chia nhiều lần khác nhau và tính trung bình kết quả. Mô hình tốt phải có hiệu suất ổn định trên nhiều cách chia dữ liệu khác nhau.
Triển khai và bảo trì mô hình
Triển khai mô hình vào production là một thách thức lớn. Mô hình hoạt động tốt trong môi trường thử nghiệm chưa chắc đã ổn định khi phục vụ hàng nghìn người dùng thực tế. Bạn cần chuẩn bị hạ tầng kỹ thuật đủ mạnh và có kế hoạch dự phòng.
Theo dõi hiệu suất mô hình là việc bắt buộc sau khi triển khai. Dữ liệu thực tế luôn thay đổi theo thời gian, khiến mô hình có thể bị “drift” – giảm độ chính xác dần. Hệ thống monitoring phải cảnh báo khi hiệu suất giảm dưới ngưỡng cho phép.
Cập nhật mô hình định kỳ là chiến lược dài hạn. Một số mô hình cần cập nhật hàng ngày (như dự đoán giá cổ phiếu), một số chỉ cần vài tháng một lần (như phân loại email spam). Tần suất cập nhật phụ thuộc vào tốc độ thay đổi của dữ liệu trong lĩnh vực bạn làm việc.
Version control cho mô hình machine learning cũng quan trọng như quản lý code. Bạn cần lưu trữ các phiên bản khác nhau của mô hình, dữ liệu huấn luyện và có khả năng rollback khi phiên bản mới gây ra vấn đề. Nhiều công ty đã học được bài học đắt giá khi không quản lý version đúng cách.
Bạn có thể đọc thêm về SaaS và điện toán đám mây để hiểu về hạ tầng công nghệ hỗ trợ triển khai và vận hành hệ thống machine learning quy mô lớn.
Ứng dụng của machine learning trong công nghệ thông tin và kinh doanh
Ứng dụng trong công nghệ thông tin
Nhận diện giọng nói đã trở thành tính năng quen thuộc trên smartphone và thiết bị thông minh. Từ Siri của Apple đến Google Assistant, machine learning giúp máy tính hiểu được lời nói của con người với độ chính xác ngày càng cao, thậm chí trong môi trường ồn ào.

Xử lý ngôn ngữ tự nhiên (NLP) cho phép máy tính đọc hiểu văn bản như con người. Google Translate có thể dịch giữa hơn 100 ngôn ngữ nhờ machine learning. Chatbot hỗ trợ khách hàng cũng sử dụng NLP để hiểu câu hỏi và đưa ra câu trả lời phù hợp.
An ninh mạng là lĩnh vực ứng dụng machine learning rất hiệu quả. Hệ thống có thể phát hiện các cuộc tấn công bất thường bằng cách học từ pattern của traffic mạng bình thường. Khi có hoạt động khả nghi, hệ thống sẽ cảnh báo hoặc tự động chặn.
Computer vision giúp máy tính “nhìn” và hiểu hình ảnh. Từ tự động tag bạn bè trên Facebook đến xe tự lái nhận biết biển báo giao thông, công nghệ này đang thay đổi cách chúng ta tương tác với thế giới thị giác. Y tế cũng sử dụng computer vision để chẩn đoán bệnh từ ảnh X-quang và MRI.
Dành cho những ai muốn hiểu rõ thêm về ChatGPT và Generative AI, hai công nghệ tiên tiến dựa trên machine learning rất phổ biến hiện nay.
Ứng dụng trong kinh doanh
Dự đoán hành vi khách hàng là ứng dụng mạnh mẽ của machine learning trong kinh doanh. Amazon sử dụng thuật toán để gợi ý sản phẩm dựa trên lịch sử mua hàng và hành vi duyệt web. Netflix cũng tương tự khi gợi ý phim phù hợp với sở thích người xem.
Marketing cá nhân hóa trở nên hiệu quả hơn nhờ machine learning. Thay vì gửi cùng một quảng cáo cho tất cả khách hàng, công ty có thể tùy chỉnh nội dung, thời điểm và kênh truyền thông phù hợp với từng người. Điều này tăng tỷ lệ chuyển đổi và giảm chi phí marketing.
Quản lý chuỗi cung ứng được tối ưu hóa thông qua dự báo nhu cầu chính xác. Walmart sử dụng machine learning để dự đoán sản phẩm nào sẽ bán chạy trong mùa nghỉ lễ, giúp họ chuẩn bị hàng hóa kịp thời và tránh tình trạng thiếu hàng hoặc tồn kho.
Phát hiện gian lận trong ngân hàng và thương mại điện tử là ứng dụng quan trọng khác. Hệ thống có thể nhận biết giao dịch bất thường dựa trên pattern chi tiêu của khách hàng. Khi có giao dịch khả nghi, ngân hàng sẽ tạm khóa thẻ và liên hệ xác nhận với khách hàng.
Lợi ích và thách thức khi sử dụng machine learning
Lợi ích nổi bật
Tăng tốc quá trình ra quyết định là lợi ích rõ rệt nhất của machine learning. Công việc cần con người mất hàng giờ để phân tích, máy tính có thể hoàn thành trong vài giây. Ví dụ, phân tích hàng nghìn CV để tìm ứng viên phù hợp, machine learning có thể làm tức thì thay vì HR mất cả tuần.

Tự động hóa các tác vụ lặp đi lặp lại giải phóng nhân viên khỏi công việc nhàm chán. Thay vì nhập liệu thủ công, hệ thống có thể tự động trích xuất thông tin từ hóa đơn, hợp đồng và xử lý. Điều này không chỉ tiết kiệm thời gian mà còn giảm sai sót do con người.
Phát hiện mẫu phức tạp mà con người khó nhận ra là điểm mạnh độc đáo của machine learning. Trong y tế, AI có thể phát hiện dấu hiệu ung thư sớm từ hình ảnh mà bác sĩ có thể bỏ sót. Trong tài chính, nó có thể tìm ra mối tương quan ẩn giữa nhiều yếu tố ảnh hưởng đến giá cổ phiếu.
Khả năng mở rộng (scalability) là lợi thế lớn khi làm việc với big data. Một khi mô hình đã được huấn luyện, nó có thể xử lý hàng triệu giao dịch mà không cần tăng nhân lực. Điều này đặc biệt có giá trị cho các công ty công nghệ phục vụ hàng triệu người dùng.
Thách thức chính
Vấn đề dữ liệu là thách thức lớn nhất trong machine learning. Dữ liệu có thể thiếu, không chính xác, hoặc mang tính thiên lệch. Nhiều dự án thất bại vì đầu tư quá nhiều vào thuật toán mà quên mất chất lượng dữ liệu. “Garbage in, garbage out” – quy luật này không bao giờ sai.
Chi phí tính toán có thể rất cao, especially đối với các mô hình phức tạp như deep learning. Training một mô hình AI tiên tiến có thể tốn hàng nghìn đôla tiền điện và phần cứng. Nhiều startup phải hạn chế tham vọng vì không đủ ngân sách cho infrastructure.
Độ tin cậy và giải thích mô hình là vấn đề nan giải. Nhiều thuật toán machine learning hoạt động như “black box” – cho kết quả nhưng không giải thích tại sao. Trong y tế hay tài chính, việc không hiểu lý do đưa ra quyết định có thể gây ra hậu quả nghiêm trọng.
Vấn đề ethical và bias cũng cần được cân nhắc kỹ lưỡng. Mô hình có thể vô tình phân biệt đối xử dựa trên giới tính, chủng tộc nếu dữ liệu huấn luyện có thiên lệch. Amazon từng phải hủy bỏ hệ thống tuyển dụng AI vì nó thiên vị nam giới so với nữ giới.
Xử lý sự cố và khắc phục vấn đề thường gặp
Vấn đề dữ liệu không đủ hoặc không chính xác
Nhận biết dữ liệu không đủ thường dễ dàng qua hiệu suất kém của mô hình. Khi mô hình cho kết quả không ổn định hoặc độ chính xác thấp, đầu tiên hãy kiểm tra xem có đủ dữ liệu không. Một dấu hiệu khác là mô hình hoạt động tốt trên dữ liệu huấn luyện nhưng kém trên dữ liệu thực.
Khắc phục thiếu dữ liệu có nhiều cách tiếp cận. Data augmentation tạo ra dữ liệu mới từ dữ liệu có sẵn bằng cách xoay, lật, thay đổi màu sắc ảnh. Transfer learning sử dụng mô hình đã được huấn luyện trên dataset lớn rồi tinh chỉnh cho bài toán cụ thể.
Dữ liệu không chính xác khó phát hiện hơn nhưng gây hại lớn. Outliers (giá trị bất thường) có thể làm sai lệch cả mô hình. Bạn cần vẽ biểu đồ phân phối dữ liệu và loại bỏ những giá trị quá xa so với trung bình.
Validation bằng chuyên gia domain là cách tốt nhất đảm bảo tính chính xác. Ví dụu, nếu làm về y tế, hãy nhờ bác sĩ xem lại labeled data. Nếu làm về tài chính, hãy hỏi ý kiến chuyên viên phân tích. Investment vào việc này sẽ tiết kiệm rất nhiều thời gian sau này.
Overfitting và underfitting trong mô hình
Overfitting xảy ra khi mô hình học thuộc lòng dữ liệu huấn luyện thay vì hiểu quy luật chung. Dấu hiệu là mô hình có độ chính xác rất cao trên training data nhưng kém trên validation data. Giống như học sinh chỉ biết làm bài tập cũ mà không làm được đề mới.

Giải pháp cho overfitting bao gồm regularization, early stopping và dropout. Regularization thêm penalty cho mô hình phức tạp, buộc nó phải đơn giản hóa. Early stopping dừng training khi validation error bắt đầu tăng. Dropout randomly tắt một số neuron trong training để tránh mô hình quá phụ thuộc vào feature cụ thể.
Underfitting ngược lại – mô hình quá đơn giản không học được pattern trong dữ liệu. Cả training và validation accuracy đều thấp. Giải pháp là tăng complexity của mô hình, thêm features, hoặc giảm regularization.
Cân bằng giữa overfitting và underfitting là nghệ thuật trong machine learning. Cross-validation giúp tìm ra sweet spot này. Bạn cũng có thể vẽ learning curve để visualize quá trình học của mô hình và điều chỉnh accordingly.
Các phương pháp tốt nhất
Đảm bảo dữ liệu đầu vào chất lượng cao là nền tảng thành công. Đầu tư thời gian vào data cleaning và exploration sẽ mang lại hiệu quả cao hơn việc thử nhiều thuật toán fancy. Hãy hiểu rõ dữ liệu trước khi đưa vào mô hình.
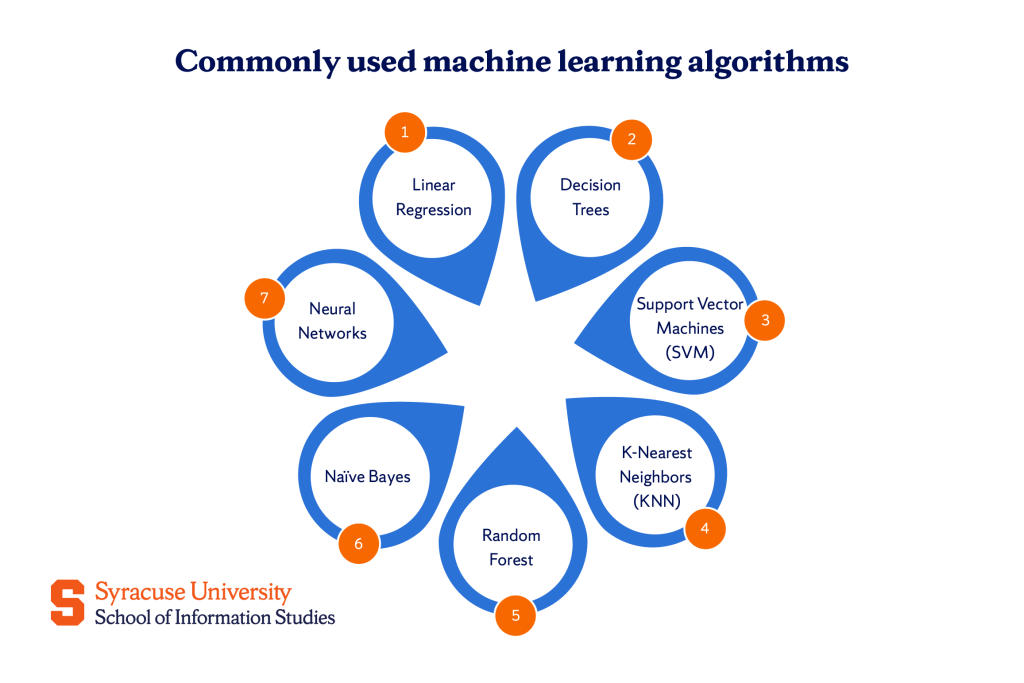
Lựa chọn thuật toán phù hợp với mục tiêu cụ thể, không theo trend. Linear regression có thể cho kết quả tốt hơn neural network với dataset nhỏ. Random forest thường là lựa chọn an toàn cho người bắt đầu vì ít tham số cần tune và khả năng generalize tốt.
Không phụ thuộc hoàn toàn vào mô hình mà cần kiểm tra và hiệu chỉnh thường xuyên. Set up monitoring system để track model performance theo thời gian. Có kế hoạch rollback khi mô hình mới gây ra vấn đề.
Tránh thu thập dữ liệu nhạy cảm không cần thiết để bảo vệ quyền riêng tư. Tuân thủ các quy định về bảo mật dữ liệu như GDPR. Anonymize dữ liệu cá nhân và chỉ thu thập minimum viable data để giải quyết bài toán.
Documentation và version control là must-have cho dự án machine learning. Ghi chép lại hyperparameters, data preprocessing steps, và model performance. Tương lai bạn sẽ cảm ơn bản thân hiện tại vì điều này.
Tổng kết
Machine learning là công cụ mạnh mẽ với nhiều ứng dụng thực tế nhưng đòi hỏi quy trình chuẩn và hiểu biết kỹ thuật. Từ healthcare đến e-commerce, từ finance đến entertainment, machine learning đang reshape nhiều ngành công nghiệp. Tuy nhiên, success không đến từ việc áp dụng thuật toán phức tạp nhất mà từ việc hiểu rõ bài toán, dữ liệu và quy trình triển khai. Hãy bắt đầu tìm hiểu và áp dụng machine learning để nâng cao hiệu quả công việc của bạn bằng cách tham khảo các khóa học, công cụ và tài liệu để áp dụng machine learning một cách bài bản.

