Trong kỷ nguyên số hóa, dữ liệu được tạo ra mỗi giây với tốc độ chóng mặt và ở nhiều định dạng khác nhau. Bạn có bao giờ tự hỏi làm thế nào các ứng dụng hiện đại có thể xử lý hàng terabyte dữ liệu người dùng, từ bài đăng mạng xã hội, lịch sử mua sắm đến dữ liệu từ các thiết bị IoT không? Đây là một thách thức lớn. Việc lựa chọn một hệ quản trị cơ sở dữ liệu (CSDL) phù hợp đã trở thành yếu tố sống còn quyết định sự thành công của một dự án công nghệ.
Vấn đề đặt ra là các hệ quản trị CSDL quan hệ truyền thống, như SQL, được thiết kế với cấu trúc bảng và dòng nghiêm ngặt. Chúng hoạt động rất tốt với dữ liệu có cấu trúc rõ ràng, nhưng lại gặp rất nhiều khó khăn khi phải xử lý dữ liệu phi cấu trúc hoặc bán cấu trúc. Việc mở rộng quy mô (scaling) trên các hệ thống này cũng thường phức tạp và tốn kém, không đáp ứng được nhu cầu linh hoạt của các ứng dụng web hiện đại. Bạn có thể tìm hiểu thêm về SQL là gì và MySQL là gì để nắm rõ hơn về cơ sở dữ liệu quan hệ truyền thống.
Để giải quyết bài toán này, MongoDB đã ra đời và nhanh chóng trở thành một trong những giải pháp hàng đầu trong thế giới NoSQL. Nó mang đến một cách tiếp cận hoàn toàn mới, linh hoạt và hiệu quả hơn cho việc lưu trữ và xử lý dữ liệu. MongoDB không chỉ giải quyết các điểm yếu của CSDL truyền thống mà còn mở ra nhiều cơ hội mới cho các nhà phát triển.
Bài viết này sẽ là kim chỉ nam giúp bạn hiểu rõ MongoDB là gì một cách toàn diện. Chúng ta sẽ cùng nhau khám phá định nghĩa, những đặc điểm nổi bật, cấu trúc dữ liệu đặc trưng, các tính năng cốt lõi và những ứng dụng thực tế của nó. Dù bạn là người mới bắt đầu hay đã có kinh nghiệm, Bùi Mạnh Đức tin rằng bạn sẽ tìm thấy những thông tin hữu ích và giá trị trong bài viết này.
MongoDB là gì và vai trò trong hệ quản trị cơ sở dữ liệu NoSQL
Để bắt đầu hành trình tìm hiểu, chúng ta cần nắm vững định nghĩa cốt lõi và vai trò của MongoDB trong bức tranh tổng thể của các hệ quản trị dữ liệu hiện nay.
Định nghĩa MongoDB
MongoDB là một hệ quản trị cơ sở dữ liệu mã nguồn mở, thuộc loại NoSQL (Not Only SQL). Thay vì lưu trữ dữ liệu trong các bảng và hàng như CSDL quan hệ (ví dụ: MySQL, PostgreSQL), MongoDB lưu trữ dữ liệu dưới dạng các tài liệu (documents) giống như JSON. Chính xác hơn, nó sử dụng định dạng BSON (Binary JSON), một phiên bản nhị phân của JSON giúp tối ưu hóa cho tốc độ và khả năng lưu trữ đa dạng kiểu dữ liệu hơn. Để hiểu sâu hơn về khái niệm NoSQL và vai trò của nó trong quản lý dữ liệu phi cấu trúc, bạn có thể tham khảo bài viết NoSQL là gì.
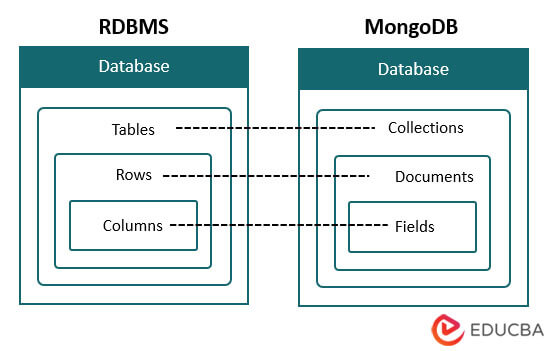
Hãy tưởng tượng CSDL quan hệ giống như một bảng tính Excel với các cột và hàng được xác định trước. Mọi dữ liệu bạn nhập vào phải tuân theo cấu trúc đó. Ngược lại, MongoDB giống như một chiếc tủ đựng hồ sơ. Mỗi ngăn kéo (collection) chứa các tập tài liệu (documents), và mỗi tài liệu có thể có cấu trúc riêng biệt. Điều này mang lại sự linh hoạt vượt trội, cho phép bạn lưu trữ những dữ liệu phức tạp một cách tự nhiên mà không cần định nghĩa cấu trúc từ trước.
Vai trò của MongoDB trong hệ quản trị dữ liệu hiện đại
Sự trỗi dậy của MongoDB gắn liền với sự bùng nổ của Big Data, ứng dụng web thời gian thực và kiến trúc microservices. Vai trò của nó trở nên cực kỳ quan trọng khi các hệ thống truyền thống bắt đầu bộc lộ những hạn chế.
So với các hệ CSDL quan hệ, MongoDB thể hiện ưu thế vượt trội trong việc quản lý dữ liệu phi cấu trúc và bán cấu trúc. Dữ liệu ngày nay không còn chỉ là những dòng text hay con số đơn giản. Nó có thể là một bài đăng mạng xã hội với bình luận, lượt thích, hình ảnh lồng nhau; một hồ sơ sản phẩm với nhiều thuộc tính tùy chọn; hay dữ liệu cảm biến từ hàng triệu thiết bị IoT. MongoDB cho phép lưu trữ toàn bộ các thông tin liên quan đến một đối tượng trong cùng một tài liệu, giúp việc truy xuất trở nên nhanh chóng và tự nhiên hơn rất nhiều.
Trong khi CSDL quan hệ yêu cầu bạn phải “chuẩn hóa” dữ liệu, chia nhỏ chúng ra nhiều bảng và dùng các phép nối (JOIN) phức tạp để lấy thông tin, MongoDB lại khuyến khích “phi chuẩn hóa”. Cách tiếp cận này giúp giảm thiểu các thao tác truy vấn phức tạp, từ đó cải thiện đáng kể hiệu năng cho các ứng dụng cần tốc độ phản hồi nhanh. Vì vậy, MongoDB không phải để thay thế hoàn toàn CSDL quan hệ, mà là một công cụ mạnh mẽ, bổ sung vào kho vũ khí của nhà phát triển, đặc biệt tối ưu cho các bài toán dữ liệu hiện đại.
Đặc điểm nổi bật của MongoDB so với hệ quản trị cơ sở dữ liệu truyền thống
Sự phổ biến của MongoDB không phải là ngẫu nhiên. Nó đến từ những đặc điểm thiết kế độc đáo, giải quyết trực tiếp các vấn đề mà CSDL truyền thống đang vật lộn. Hãy cùng xem xét hai yếu tố cốt lõi làm nên sự khác biệt này.
Cơ chế lưu trữ tài liệu (Document-oriented storage)
Đây là đặc điểm nền tảng và khác biệt nhất của MongoDB. Như đã đề cập, nó không dùng bảng và hàng. Thay vào đó, nó sử dụng một mô hình hướng tài liệu, nơi mỗi bản ghi là một “tài liệu” BSON.
Định dạng BSON (Binary JSON) là một phiên bản nhị phân, được tối ưu hóa của JSON. Nó hỗ trợ nhiều kiểu dữ liệu hơn JSON (ví dụ: datetime, binary data) và được thiết kế để quét và phân tích nhanh hơn. Mỗi tài liệu BSON là một cấu trúc dữ liệu bao gồm các cặp “trường” và “giá trị”, tương tự như các đối tượng trong lập trình. Ví dụ, thông tin một người dùng có thể được lưu trữ trong một tài liệu duy nhất như sau:
{
"_id": ObjectId("60c72b2f9b1d8eadfe03a4a0"),
"username": "buimanhduc",
"email": "contact@buimanhduc.com",
"joined_date": ISODate("2023-01-15T10:00:00Z"),
"interests": ["WordPress", "Hosting", "Digital Marketing"],
"address": {
"street": "123 ABC Street",
"city": "Hanoi"
}
}
Bạn có thấy không? Tất cả thông tin của người dùng, bao gồm cả một mảng sở thích và một đối tượng địa chỉ lồng nhau, đều nằm gọn trong một tài liệu. Cơ chế này cực kỳ linh hoạt. Nếu sau này bạn muốn thêm trường “số điện thoại” cho một số người dùng, bạn chỉ cần thêm vào các tài liệu đó mà không cần phải thay đổi cấu trúc của toàn bộ “bảng” như trong CSDL quan hệ. Sự linh hoạt này được gọi là “schema-less” hay “dynamic schema”, giúp các nhà phát triển dễ dàng thay đổi và phát triển ứng dụng một cách nhanh chóng.
Khả năng mở rộng và hiệu năng
Khi một ứng dụng phát triển, lượng dữ liệu và lưu lượng truy cập sẽ tăng vọt. Đây là lúc khả năng mở rộng trở thành yếu tố quyết định. CSDL truyền thống thường mở rộng theo chiều dọc (vertical scaling), tức là nâng cấp phần cứng của máy chủ hiện tại (thêm RAM, CPU). Cách này có giới hạn và rất tốn kém.
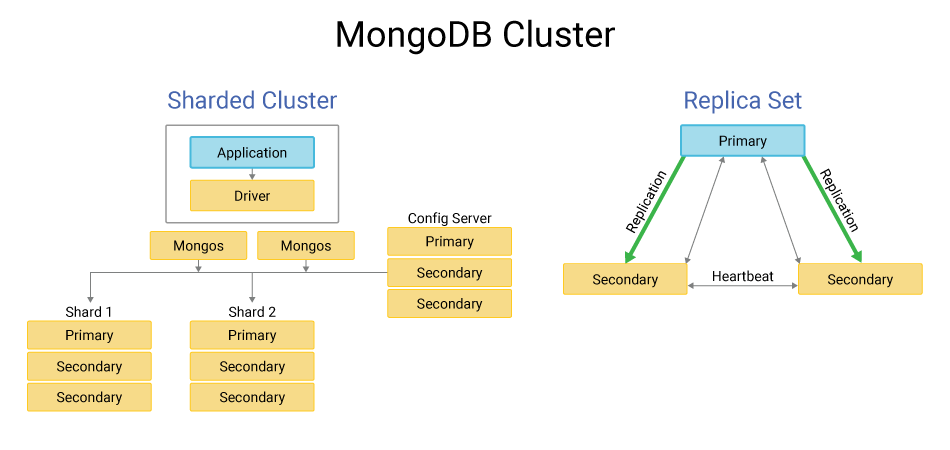
MongoDB được thiết kế để mở rộng theo chiều ngang (horizontal scaling), hay còn gọi là “sharding”. Sharding là quá trình phân chia dữ liệu trên nhiều máy chủ khác nhau. Hãy tưởng tượng bạn có một thư viện khổng lồ. Thay vì chỉ có một thủ thư (một máy chủ) phải xử lý tất cả yêu cầu, bạn chia sách ra nhiều khu vực (A-E, F-K,…) và thuê nhiều thủ thư, mỗi người phụ trách một khu vực. Khi có người tìm sách, họ sẽ được chỉ đến đúng thủ thư, giúp hệ thống xử lý được nhiều yêu cầu cùng lúc và nhanh hơn.

Cơ chế sharding này cho phép MongoDB xử lý các bộ dữ liệu khổng lồ và lưu lượng truy cập cực lớn một cách hiệu quả. Bạn có thể dễ dàng thêm các máy chủ mới vào cụm (cluster) để tăng khả năng lưu trữ và xử lý mà không làm gián đoạn hệ thống. Bên cạnh đó, MongoDB còn tối ưu hóa các thao tác truy vấn. Việc lưu trữ dữ liệu liên quan trong cùng một tài liệu giúp giảm nhu cầu về các phép JOIN đắt đỏ. Kết hợp với hệ thống đánh chỉ mục (indexing) mạnh mẽ, MongoDB có thể thực hiện các truy vấn phức tạp một cách nhanh chóng, rất phù hợp cho các ứng dụng yêu cầu hiệu năng cao. Bạn có thể tham khảo thêm về Redis để hiểu thêm về các công nghệ lưu trữ và xử lý dữ liệu hiệu năng cao.
Cấu trúc dữ liệu và cách lưu trữ phi cấu trúc trong MongoDB
Để làm việc hiệu quả với MongoDB, bạn cần hiểu rõ cách nó tổ chức và lưu trữ dữ liệu. Cấu trúc của nó hoàn toàn khác biệt so với mô hình bảng-hàng quen thuộc.
Tổng quan về dữ liệu phi cấu trúc và bán cấu trúc
Trước tiên, hãy làm rõ sự khác biệt giữa các loại dữ liệu.
- Dữ liệu có cấu trúc (Structured Data): Đây là loại dữ liệu có mô hình được định nghĩa trước, thường ở dạng bảng. Ví dụ điển hình là các bảng trong CSDL quan hệ như MySQL. Mọi hàng trong bảng phải tuân theo các cột đã được xác định. Dữ liệu này rất có tổ chức và dễ dàng cho máy tính xử lý.
- Dữ liệu phi cấu trúc (Unstructured Data): Loại dữ liệu này không có mô hình dữ liệu xác định trước. Ví dụ bao gồm các tệp văn bản, email, hình ảnh, video, âm thanh. Nó chiếm phần lớn dữ liệu trên thế giới và rất khó để các hệ thống truyền thống phân tích.
- Dữ liệu bán cấu trúc (Semi-structured Data): Đây là loại dữ liệu nằm giữa hai loại trên. Nó không tuân theo một cấu trúc cứng nhắc như bảng, nhưng lại chứa các thẻ hoặc dấu hiệu để phân tách các yếu tố. JSON và XML là những ví dụ kinh điển. Dữ liệu trong MongoDB chính là dữ liệu bán cấu trúc.
MongoDB được sinh ra để giải quyết bài toán của dữ liệu phi cấu trúc và bán cấu trúc, nơi mà sự linh hoạt quan trọng hơn sự cứng nhắc.

Cách MongoDB lưu trữ và truy xuất dữ liệu
MongoDB tổ chức dữ liệu theo một hệ thống phân cấp đơn giản và logic, giúp bạn dễ dàng hình dung.
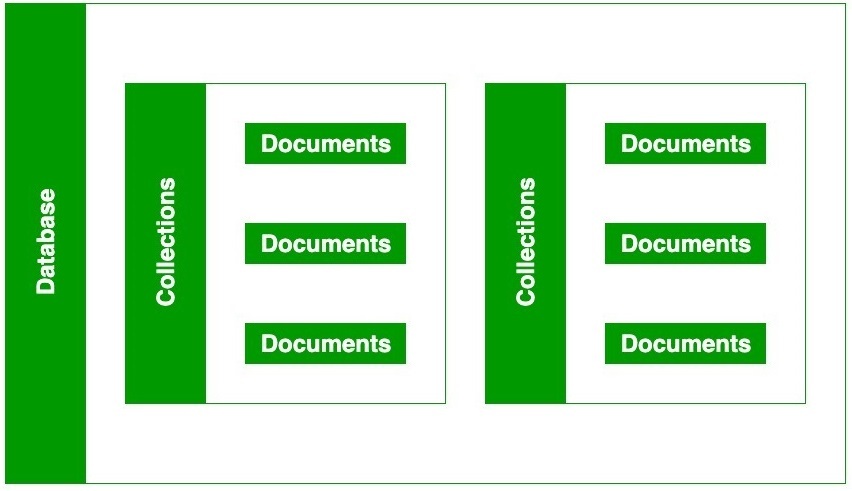
- Database (Cơ sở dữ liệu): Đây là đơn vị chứa cấp cao nhất, giống như một CSDL trong MySQL. Một máy chủ MongoDB có thể chứa nhiều database riêng biệt.
- Collection (Bộ sưu tập): Thay vì “bảng” (table), MongoDB sử dụng “collection”. Một collection là một nhóm các tài liệu (documents). Bạn có thể hình dung nó như một thư mục chứa các tệp tin. Ví dụ, bạn có thể có collection
users, products, orders. Điểm mấu chốt là các tài liệu trong cùng một collection không bắt buộc phải có cùng cấu trúc.
- Document (Tài liệu): Đây là đơn vị lưu trữ cơ bản nhất trong MongoDB, tương đương với một “hàng” (row) trong CSDL quan hệ. Mỗi document là một cấu trúc BSON chứa các cặp khóa-giá trị. Đây chính là nơi dữ liệu của bạn được lưu trữ.
Sự kỳ diệu nằm ở chỗ MongoDB có schema linh hoạt (dynamic schema). Điều này có nghĩa là bạn không cần phải định nghĩa cấu trúc của một collection trước khi chèn dữ liệu. Document đầu tiên bạn chèn vào có thể có 5 trường, document thứ hai có thể có 7 trường với các tên khác nhau. Hệ thống vẫn chấp nhận và hoạt động bình thường.
Ví dụ, trong collection products, một document cho “laptop” có thể có các trường như cpu, ram. Nhưng một document cho “áo thun” lại có các trường size, color. Tất cả đều có thể cùng tồn tại trong một collection. Sự linh hoạt này giúp quá trình phát triển ứng dụng nhanh hơn rất nhiều, vì bạn không cần phải thực hiện các thao tác di chuyển (migration) CSDL phức tạp mỗi khi mô hình dữ liệu thay đổi.
Khi truy xuất dữ liệu, bạn sử dụng các câu lệnh truy vấn (queries) để tìm các document khớp với điều kiện nhất định trong một collection. Các câu lệnh này cũng ở định dạng JSON, rất trực quan và dễ hiểu đối với các nhà phát triển quen thuộc với JavaScript. Nếu bạn muốn tìm hiểu cách làm việc với các ngôn ngữ lập trình phổ biến sử dụng MongoDB, có thể tham khảo thêm bài viết về Node.js là gì hoặc ORM là gì.
Các tính năng chính của MongoDB
Ngoài cấu trúc dữ liệu linh hoạt, MongoDB còn được trang bị nhiều tính năng mạnh mẽ, giúp nó trở thành một lựa chọn hấp dẫn cho các ứng dụng hiện đại.
Khả năng mở rộng linh hoạt
Chúng ta đã nói về sharding (mở rộng theo chiều ngang), nhưng đó chỉ là một phần của câu chuyện. Để đảm bảo hệ thống luôn sẵn sàng và an toàn dữ liệu, MongoDB còn tích hợp một tính năng cực kỳ quan trọng là Replication (Nhân bản).
Replication hoạt động bằng cách tạo ra và duy trì nhiều bản sao dữ liệu trên các máy chủ khác nhau. Nhóm các máy chủ này được gọi là Replica Set. Trong một replica set, sẽ có một máy chủ chính (Primary) xử lý tất cả các thao tác ghi dữ liệu. Các máy chủ còn lại là máy chủ phụ (Secondary) sẽ sao chép dữ liệu từ máy chủ chính.

Cơ chế này mang lại hai lợi ích lớn:
- Độ tin cậy và sẵn sàng cao (High Availability): Nếu máy chủ Primary gặp sự cố (ví dụ: mất điện, lỗi phần cứng), một trong các máy chủ Secondary sẽ tự động được bầu chọn lên làm Primary mới. Quá trình này diễn ra rất nhanh, giúp ứng dụng của bạn gần như không bị gián đoạn.
- Tăng khả năng đọc: Các thao tác đọc có thể được phân phối cho các máy chủ Secondary, giúp giảm tải cho máy chủ Primary và tăng thông lượng đọc của toàn hệ thống.
Kết hợp giữa Sharding và Replication, MongoDB cung cấp một giải pháp toàn diện cho việc mở rộng quy mô, đảm bảo hệ thống có thể phát triển mạnh mẽ mà vẫn duy trì được độ tin cậy và hiệu suất. Nếu bạn quan tâm đến công nghệ container và triển khai ứng dụng linh hoạt, có thể tham khảo thêm bài viết Docker là gì và Kubernetes là gì.
Hiệu năng cao và tích hợp với ứng dụng
Hiệu năng là yếu tố sống còn của mọi ứng dụng. MongoDB cung cấp nhiều công cụ để tối ưu hóa tốc độ truy vấn và xử lý dữ liệu.
- Indexing (Đánh chỉ mục): Tương tự như CSDL quan hệ, MongoDB hỗ trợ đánh chỉ mục trên bất kỳ trường nào trong một document, kể cả các trường lồng nhau hoặc trong mảng. Index hoạt động như mục lục của một cuốn sách, giúp CSDL tìm thấy dữ liệu nhanh hơn rất nhiều mà không cần phải quét toàn bộ collection. MongoDB hỗ trợ nhiều loại index khác nhau như single-field, compound, text, geospatial, đáp ứng các nhu cầu truy vấn đa dạng.
- Aggregation Framework (Khung tổng hợp): Đây là một công cụ cực kỳ mạnh mẽ để thực hiện các thao tác xử lý dữ liệu phức tạp. Thay vì kéo toàn bộ dữ liệu về phía ứng dụng để xử lý, bạn có thể xây dựng một “đường ống” (pipeline) gồm nhiều giai đoạn (stages) ngay trên CSDL. Mỗi giai đoạn sẽ thực hiện một thao tác như lọc, nhóm, tính toán, sắp xếp… và chuyển kết quả cho giai đoạn tiếp theo. Điều này giúp tối ưu hóa hiệu năng bằng cách xử lý dữ liệu ngay tại nơi nó được lưu trữ.

Ngoài ra, MongoDB còn có một hệ sinh thái hỗ trợ rộng lớn. Nó cung cấp các driver (trình điều khiển) chính thức cho hầu hết các ngôn ngữ lập trình phổ biến như JavaScript (Node.js), Python, Java, C#, Go, PHP… Điều này giúp các nhà phát triển dễ dàng tích hợp MongoDB vào ứng dụng của mình một cách tự nhiên và hiệu quả.
Ứng dụng thực tế và các trường hợp sử dụng phổ biến của MongoDB
Với những ưu điểm về tính linh hoạt, khả năng mở rộng và hiệu năng, MongoDB đã được tin dùng bởi hàng nghìn công ty trên toàn thế giới, từ các startup nhỏ đến những tập đoàn công nghệ khổng lồ.
Các ngành sử dụng MongoDB
MongoDB tỏa sáng trong các lĩnh vực yêu cầu xử lý dữ liệu lớn, đa dạng và thay đổi nhanh chóng. Dưới đây là một số ngành tiêu biểu:
- Thương mại điện tử (E-commerce): Các trang web như eBay sử dụng MongoDB để quản lý danh mục sản phẩm với hàng triệu mặt hàng có thuộc tính khác nhau, lưu trữ giỏ hàng, hồ sơ người dùng và lịch sử giao dịch. Sự linh hoạt của schema là lý tưởng cho việc này.
- Internet of Things (IoT): Các hệ thống IoT tạo ra một luồng dữ liệu khổng lồ từ hàng triệu cảm biến. MongoDB có khả năng ghi nhận (ingest) và xử lý dữ liệu này ở tốc độ cao, lý tưởng cho việc phân tích dữ liệu cảm biến theo thời gian thực.
- Big Data và Phân tích thời gian thực: MongoDB thường được sử dụng làm cơ sở dữ liệu hoạt động cho các ứng dụng Big Data. Khả năng mở rộng ngang và Aggregation Framework mạnh mẽ giúp nó có thể xử lý và phân tích các tập dữ liệu lớn ngay lập tức.
- Ứng dụng di động (Mobile Apps): Hầu hết các ứng dụng di động đều cần một backend linh hoạt để lưu trữ dữ liệu người dùng, nội dung, thông báo… Mô hình dữ liệu JSON-like của MongoDB tương thích hoàn hảo với các định dạng dữ liệu thường được sử dụng trong phát triển di động.
- Quản lý nội dung và danh mục: Các hệ thống quản lý nội dung (CMS), blog, hoặc các trang web tin tức như Forbes sử dụng MongoDB để lưu trữ bài viết, bình luận, thông tin tác giả và các dữ liệu đa phương tiện khác nhau.

Ví dụ thực tế triển khai MongoDB
Để thấy rõ hơn sức mạnh của MongoDB, hãy xem cách một số công ty lớn đã triển khai nó:
- Forbes: Tạp chí kinh doanh nổi tiếng này đã chuyển sang sử dụng MongoDB cho hệ thống quản lý nội dung của mình. Điều này giúp họ tăng tốc độ xuất bản, cá nhân hóa trải nghiệm người đọc và dễ dàng tích hợp các nội dung đa phương tiện.
- Toyota: Toyota Material Handling đã sử dụng MongoDB và các công nghệ IoT để xây dựng hệ thống quản lý xe nâng thông minh. Dữ liệu từ các cảm biến trên xe được thu thập và phân tích theo thời gian thực để tối ưu hóa hoạt động và bảo trì.
- Adobe: Gã khổng lồ phần mềm này sử dụng MongoDB cho nhiều dịch vụ của mình, bao gồm Adobe Experience Manager. Nó giúp quản lý một lượng lớn dữ liệu người dùng và tài sản kỹ thuật số một cách hiệu quả.
- SEGA: Công ty game nổi tiếng của Nhật Bản đã sử dụng MongoDB cho các tựa game di động của mình. Khả năng mở rộng linh hoạt giúp họ dễ dàng xử lý lượng người chơi tăng đột biến khi một trò chơi trở nên phổ biến.
Những ví dụ này cho thấy MongoDB không chỉ là một công nghệ trên lý thuyết mà đã chứng tỏ được giá trị thực tiễn trong các hệ thống đòi hỏi khắt khe nhất.
Các vấn đề thường gặp khi sử dụng MongoDB
Mặc dù MongoDB rất mạnh mẽ, nhưng không có công nghệ nào là hoàn hảo. Việc hiểu rõ những thách thức và vấn đề tiềm ẩn sẽ giúp bạn sử dụng nó một cách hiệu quả hơn và tránh được các sai lầm phổ biến.
Vấn đề về nhất quán dữ liệu
Đây là một trong những điểm gây tranh cãi nhiều nhất về các hệ thống NoSQL nói chung và MongoDB nói riêng. Để hiểu vấn đề này, chúng ta cần biết về Định lý CAP (CAP Theorem). Định lý này phát biểu rằng trong một hệ thống phân tán, không thể nào đảm bảo cùng lúc cả ba yếu tố sau:
- Consistency (Tính nhất quán): Mọi thao tác đọc đều trả về dữ liệu được ghi gần nhất.
- Availability (Tính sẵn sàng): Mọi yêu cầu đều nhận được phản hồi, không có lỗi.
- Partition Tolerance (Khả năng chịu lỗi phân mảnh): Hệ thống vẫn tiếp tục hoạt động ngay cả khi có sự cố mạng làm mất kết nối giữa các node.

Một hệ thống phân tán như MongoDB bắt buộc phải có Partition Tolerance. Do đó, nó phải đánh đổi giữa Consistency và Availability. Trong cấu hình mặc định, MongoDB ưu tiên Availability. Điều này có nghĩa là trong một khoảng thời gian rất ngắn sau khi ghi dữ liệu vào node Primary, các node Secondary có thể chưa kịp đồng bộ. Nếu bạn đọc dữ liệu từ một node Secondary ngay lúc đó, bạn có thể nhận được dữ liệu cũ (hiện tượng này gọi là eventual consistency – nhất quán cuối cùng).
Đối với nhiều ứng dụng như mạng xã hội hay blog, sự chậm trễ vài mili giây này không phải là vấn đề lớn. Tuy nhiên, với các hệ thống tài chính, ngân hàng yêu cầu tính nhất quán tuyệt đối, đây là một sự đánh đổi cần cân nhắc kỹ lưỡng. Dù vậy, MongoDB cũng cung cấp các tùy chọn cấu hình write concern và read concern để bạn có thể điều chỉnh mức độ nhất quán theo nhu cầu của ứng dụng, thậm chí đạt được mức nhất quán cao như CSDL quan hệ, nhưng sẽ phải hy sinh một phần hiệu năng hoặc tính sẵn sàng.
Quản lý hiệu năng và tối ưu truy vấn
Sự linh hoạt của schema trong MongoDB là một con dao hai lưỡi. Nếu không được quản lý cẩn thận, nó có thể dẫn đến các vấn đề về hiệu năng.
- Thiết kế schema không hiệu quả: Mặc dù không có schema cứng nhắc, bạn vẫn cần có một chiến lược thiết kế schema rõ ràng. Việc lạm dụng các tài liệu lồng nhau quá sâu hoặc các mảng quá lớn có thể làm tài liệu trở nên cồng kềnh, gây khó khăn cho việc truy vấn và cập nhật.
- Thiếu chỉ mục (index): Đây là lỗi phổ biến nhất. Khi dữ liệu còn ít, truy vấn có thể vẫn nhanh. Nhưng khi collection phát triển lên hàng triệu document, một truy vấn không sử dụng index sẽ phải quét toàn bộ collection, làm cho ứng dụng chậm đi đáng kể. Việc xác định và tạo các chỉ mục phù hợp là cực kỳ quan trọng.
- Truy vấn phức tạp: Mặc dù Aggregation Framework rất mạnh, việc xây dựng các pipeline quá phức tạp có thể tiêu tốn nhiều tài nguyên CPU và bộ nhớ của máy chủ. Cần phải tối ưu hóa các giai đoạn trong pipeline để đảm bảo hiệu suất.
Hiểu rõ những vấn đề này không phải để bạn sợ hãi MongoDB, mà để bạn có sự chuẩn bị và áp dụng các phương pháp tốt nhất, đảm bảo hệ thống của mình hoạt động ổn định và hiệu quả khi phát triển.
Best Practices khi làm việc với MongoDB
Để khai thác tối đa sức mạnh của MongoDB và tránh các cạm bẫy tiềm ẩn, việc tuân thủ các quy tắc và kinh nghiệm thực tiễn (best practices) là vô cùng cần thiết. Dưới đây là những lời khuyên quan trọng mà Bùi Mạnh Đức đã đúc kết được.
- Xây dựng schema phù hợp với nhu cầu truy vấn: Mặc dù schema linh hoạt, bạn nên thiết kế cấu trúc tài liệu dựa trên cách ứng dụng của bạn sẽ truy cập dữ liệu. Nếu bạn thường xuyên cần lấy thông tin A và B cùng lúc, hãy xem xét đặt chúng trong cùng một tài liệu. Nguyên tắc chung là “dữ liệu được truy cập cùng nhau nên được lưu trữ cùng nhau”.
- Tận dụng indexing một cách thông minh: Hãy phân tích các truy vấn thường xuyên nhất của bạn và tạo chỉ mục cho các trường được sử dụng trong bộ lọc, sắp xếp. Sử dụng chỉ mục phức hợp (compound index) cho các truy vấn lọc trên nhiều trường. Đừng tạo quá nhiều chỉ mục không cần thiết vì chúng cũng tốn dung lượng và làm chậm thao tác ghi.
- Chú ý sharding hợp lý khi mở rộng quy mô: Khi bạn quyết định sử dụng sharding, việc chọn “shard key” (khóa phân mảnh) là cực kỳ quan trọng. Một shard key tốt sẽ giúp phân phối dữ liệu và lưu lượng truy cập đều trên các shard. Một shard key tồi có thể dẫn đến tình trạng “hot shard”, nơi một shard phải chịu quá nhiều tải trong khi các shard khác lại nhàn rỗi.
- Không lạm dụng các phép nối từ phía ứng dụng: MongoDB không có các phép JOIN như CSDL quan hệ. Mặc dù bạn có thể thực hiện các thao tác tương tự bằng cách sử dụng toán tử
$lookup trong Aggregation Framework hoặc thực hiện nhiều truy vấn từ ứng dụng, hãy hạn chế việc này. Thiết kế schema phi chuẩn hóa thường là cách tiếp cận tốt hơn.
- Tận dụng Aggregation Pipeline: Đối với các tác vụ xử lý dữ liệu phức tạp, hãy ưu tiên sử dụng Aggregation Pipeline thay vì kéo một lượng lớn dữ liệu về client và xử lý ở đó. Điều này giúp giảm tải cho mạng và tận dụng sức mạnh xử lý của máy chủ CSDL.
- Đảm bảo backup và replication dữ liệu thường xuyên: Đừng bao giờ chủ quan với dữ liệu của bạn. Luôn thiết lập Replica Set để đảm bảo tính sẵn sàng cao. Đồng thời, hãy xây dựng một chiến lược sao lưu (backup) định kỳ và kiểm tra quy trình khôi phục (restore) để đảm bảo bạn có thể phục hồi dữ liệu khi có sự cố nghiêm trọng xảy ra.
Việc áp dụng những kinh nghiệm này sẽ giúp bạn xây dựng được các ứng dụng dựa trên MongoDB không chỉ linh hoạt, dễ phát triển mà còn mạnh mẽ, ổn định và có hiệu năng cao.
Kết luận
Qua một hành trình chi tiết, chúng ta đã cùng nhau khám phá MongoDB là gì, từ định nghĩa cơ bản, những đặc điểm cốt lõi cho đến các ứng dụng thực tiễn và kinh nghiệm làm việc hiệu quả. Có thể thấy, MongoDB không chỉ là một hệ quản trị cơ sở dữ liệu NoSQL thông thường. Nó đại diện cho một tư duy mới về cách lưu trữ và xử lý dữ liệu trong thế giới hiện đại – một thế giới nơi dữ liệu đa dạng, biến đổi không ngừng và có quy mô khổng lồ.
Vai trò quan trọng và những ưu điểm vượt trội của MongoDB là không thể phủ nhận. Với cơ chế lưu trữ hướng tài liệu linh hoạt, khả năng mở rộng theo chiều ngang gần như vô hạn thông qua sharding và replication, cùng với hiệu năng truy vấn ấn tượng, MongoDB đã chứng tỏ mình là một công cụ đắc lực cho các nhà phát triển. Nó giúp rút ngắn thời gian phát triển, dễ dàng thích ứng với các yêu cầu thay đổi và xây dựng được những hệ thống có khả năng chịu tải cực lớn.
Nếu bạn đang phát triển một ứng dụng web hiện đại, một hệ thống IoT, một nền tảng quản lý nội dung hay bất kỳ dự án nào liên quan đến Big Data, Bùi Mạnh Đức thực sự khuyến khích bạn hãy tìm hiểu sâu hơn và mạnh dạn thử nghiệm MongoDB. Trải nghiệm thực tế sẽ giúp bạn cảm nhận rõ nhất sự khác biệt và sức mạnh mà nó mang lại.
Để bắt đầu, bạn có thể tham khảo các tài liệu chính thức trên trang chủ của MongoDB, tham gia các khóa học trực tuyến hoặc trở thành một phần của cộng đồng MongoDB sôi nổi trên toàn thế giới. Đừng ngần ngại bắt đầu một dự án nhỏ, đó là cách học tốt nhất. Chúc bạn thành công trên con đường chinh phục công nghệ dữ liệu mới mẻ và đầy tiềm năng này

