Bạn đã bao giờ truy cập một website quan trọng và nhận được thông báo lỗi “không thể kết nối”? Cảm giác thật khó chịu phải không? Đối với doanh nghiệp, tình trạng này không chỉ gây khó chịu cho người dùng mà còn là một cơn ác mộng thực sự. Mỗi phút hệ thống ngừng hoạt động (downtime) có thể dẫn đến thất thoát doanh thu, suy giảm uy tín thương hiệu và làm mất lòng tin của khách hàng. Đây chính là vấn đề phổ biến mà mọi tổ chức từ nhỏ đến lớn đều phải đối mặt trong kỷ nguyên số.
Để giải quyết thách thức này, khái niệm “High Availability là gì” hay “Tính sẵn sàng cao” đã ra đời. Đây không chỉ là một thuật ngữ công nghệ, mà là một chiến lược toàn diện giúp đảm bảo hệ thống của bạn hoạt động gần như liên tục, 24/7. High Availability (HA) là giải pháp giúp ngăn chặn downtime, tối đa hóa hiệu suất và mang lại trải nghiệm liền mạch cho người dùng cuối. Trong bài viết này, chúng ta sẽ cùng nhau khám phá từ định nghĩa cơ bản, các kỹ thuật triển khai, ứng dụng thực tế cho đến những ví dụ điển hình về High Availability.
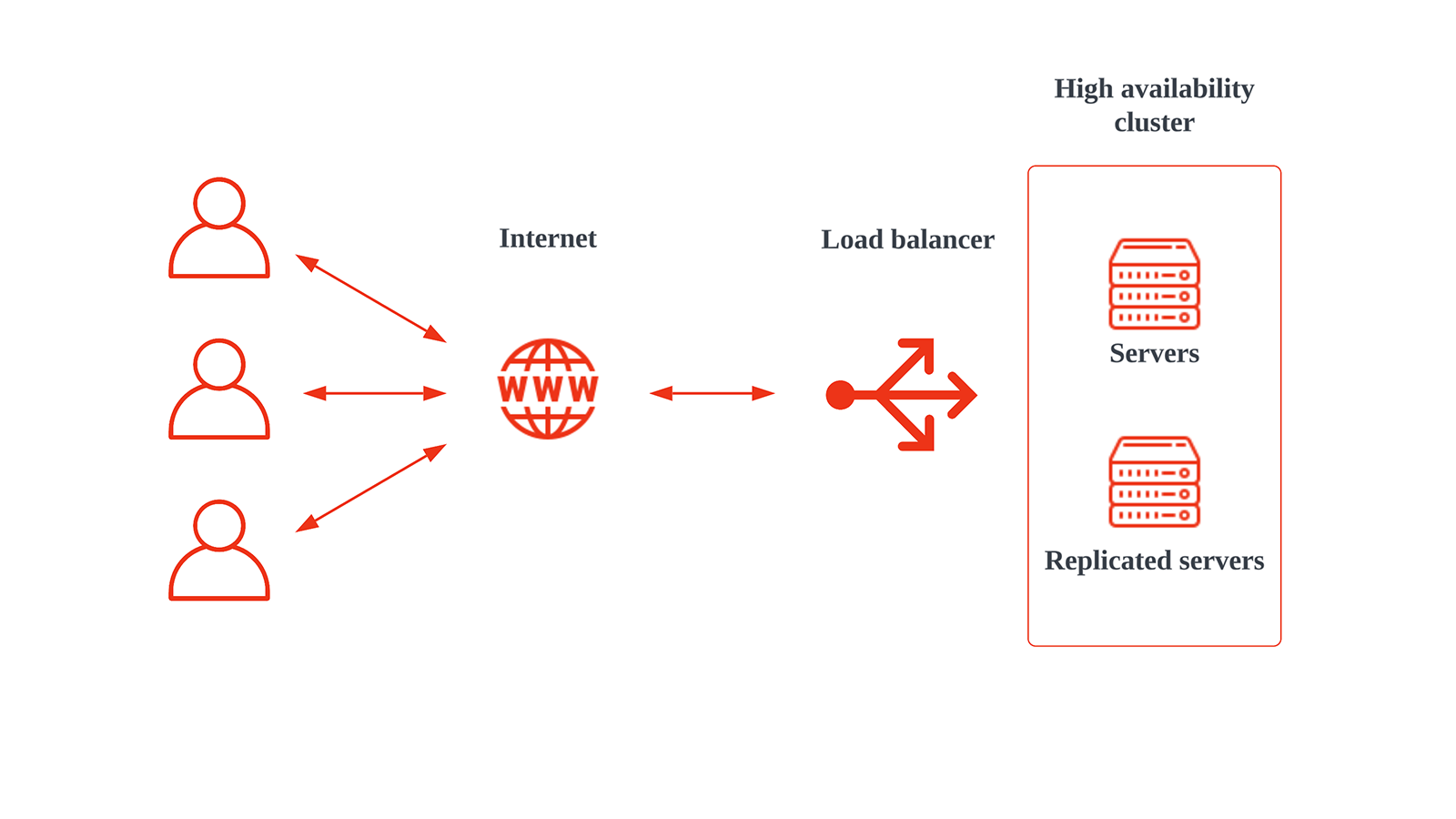
Định nghĩa High Availability là gì
Khái niệm cơ bản về High Availability
Vậy chính xác thì High Availability là gì? High Availability (viết tắt là HA) là một nguyên tắc thiết kế hệ thống và cũng là một thước đo hiệu suất trong công nghệ thông tin. Mục tiêu của HA là đảm bảo một hệ thống hoặc thành phần của nó hoạt động liên tục trong một khoảng thời gian dài, với tỷ lệ gián đoạn ở mức tối thiểu. Một hệ thống được coi là có tính sẵn sàng cao khi nó có khả năng tự động phục hồi sau sự cố mà không cần sự can thiệp của con người.
Độ sẵn sàng của một hệ thống thường được đo bằng phần trăm thời gian hoạt động (uptime là gì) trong một năm. Chắc hẳn bạn đã từng nghe về các con số “9” như 99.9% (three-nines) hay 99.999% (five-nines). Các con số này đại diện cho cam kết về thời gian uptime. Ví dụ, một hệ thống có độ sẵn sàng 99.9% sẽ có thời gian downtime tối đa khoảng 8.77 giờ mỗi năm. Trong khi đó, hệ thống đạt 99.999% chỉ ngừng hoạt động tối đa 5.26 phút mỗi năm. Để đạt được những con số ấn tượng này, hệ thống phải được xây dựng dựa trên các nguyên tắc dự phòng, giám sát và tự động hóa.

Ý nghĩa và tầm quan trọng của High Availability
Tại sao việc đảm bảo hệ thống hoạt động liên tục lại quan trọng đến vậy? Trong thế giới kết nối ngày nay, sự gián đoạn dù chỉ trong vài phút cũng có thể gây ra những hậu quả nghiêm trọng. Đối với một trang web thương mại điện tử, downtime đồng nghĩa với việc mất đơn hàng và doanh thu trực tiếp. Khách hàng không thể mua sắm, và họ có thể sẽ tìm đến đối thủ cạnh tranh của bạn.
Ảnh hưởng của downtime không chỉ dừng lại ở mặt tài chính. Nó còn làm tổn hại nghiêm trọng đến uy tín thương hiệu mà bạn đã dày công xây dựng. Người dùng sẽ mất niềm tin vào dịch vụ của bạn nếu họ thường xuyên gặp phải sự cố khi truy cập. Đối với các ứng dụng nội bộ của doanh nghiệp như CRM hay ERP, downtime làm đình trệ hoạt động, giảm năng suất của nhân viên và ảnh hưởng đến các quy trình kinh doanh cốt lõi. Vì vậy, đầu tư vào High Availability không phải là một chi phí, mà là một khoản đầu tư chiến lược để bảo vệ hoạt động kinh doanh và duy trì lợi thế cạnh tranh.
Các kỹ thuật và phương pháp xây dựng hệ thống High Availability
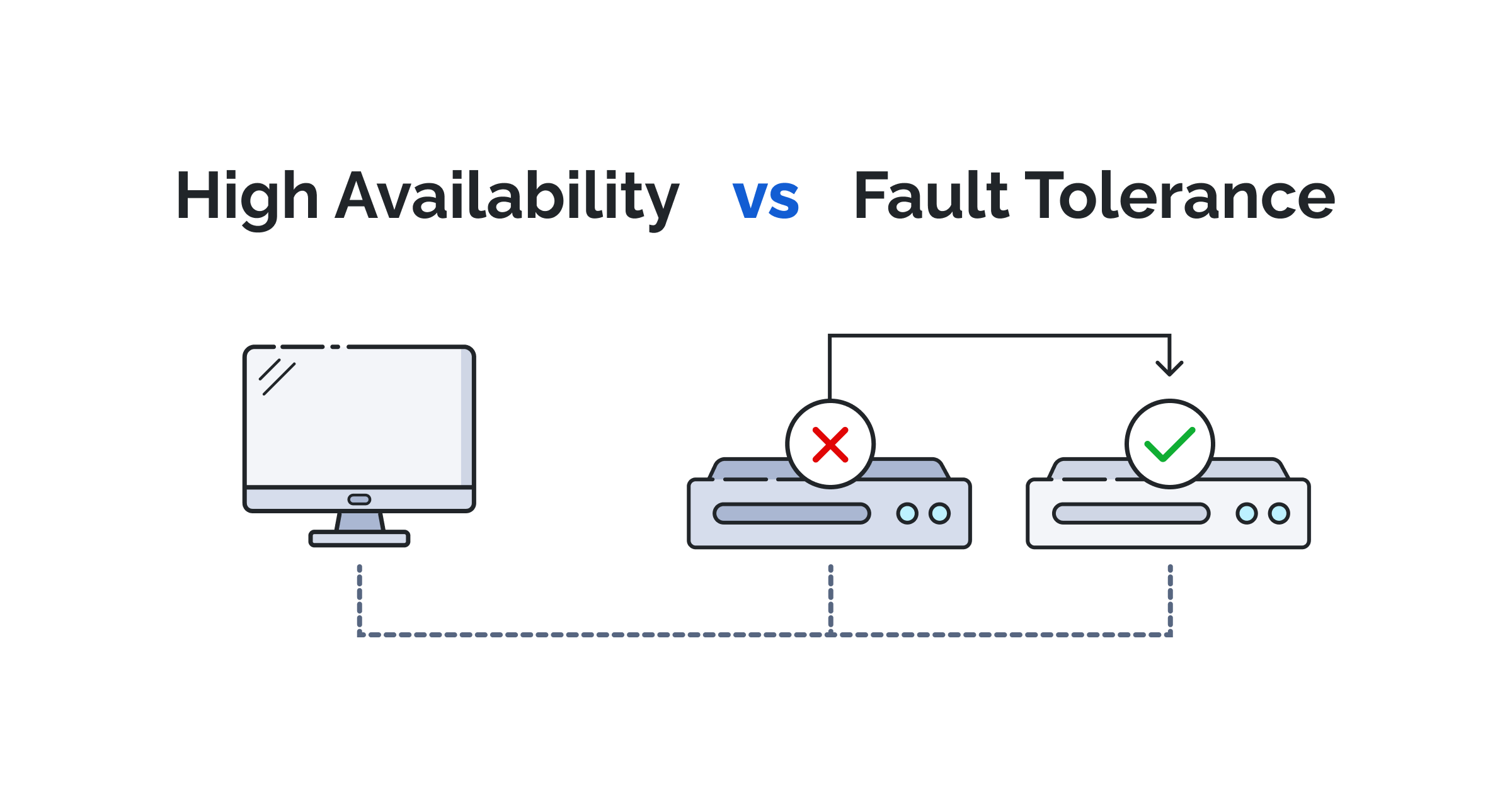
Để một hệ thống có thể hoạt động bền bỉ và liên tục, chúng ta cần áp dụng các kỹ thuật và phương pháp được thiết kế đặc biệt. Cốt lõi của High Availability nằm ở việc loại bỏ các “điểm lỗi duy nhất” (Single Point of Failure – SPOF). Đây là những thành phần mà nếu chúng gặp sự cố, toàn bộ hệ thống sẽ sụp đổ.
Kiến trúc dự phòng và sao lưu
Nguyên tắc cơ bản nhất của HA là dự phòng (Redundancy). Ý tưởng rất đơn giản: nếu một thành phần có nguy cơ bị lỗi, hãy tạo ra một hoặc nhiều bản sao dự phòng cho nó. Các kỹ thuật phổ biến bao gồm:
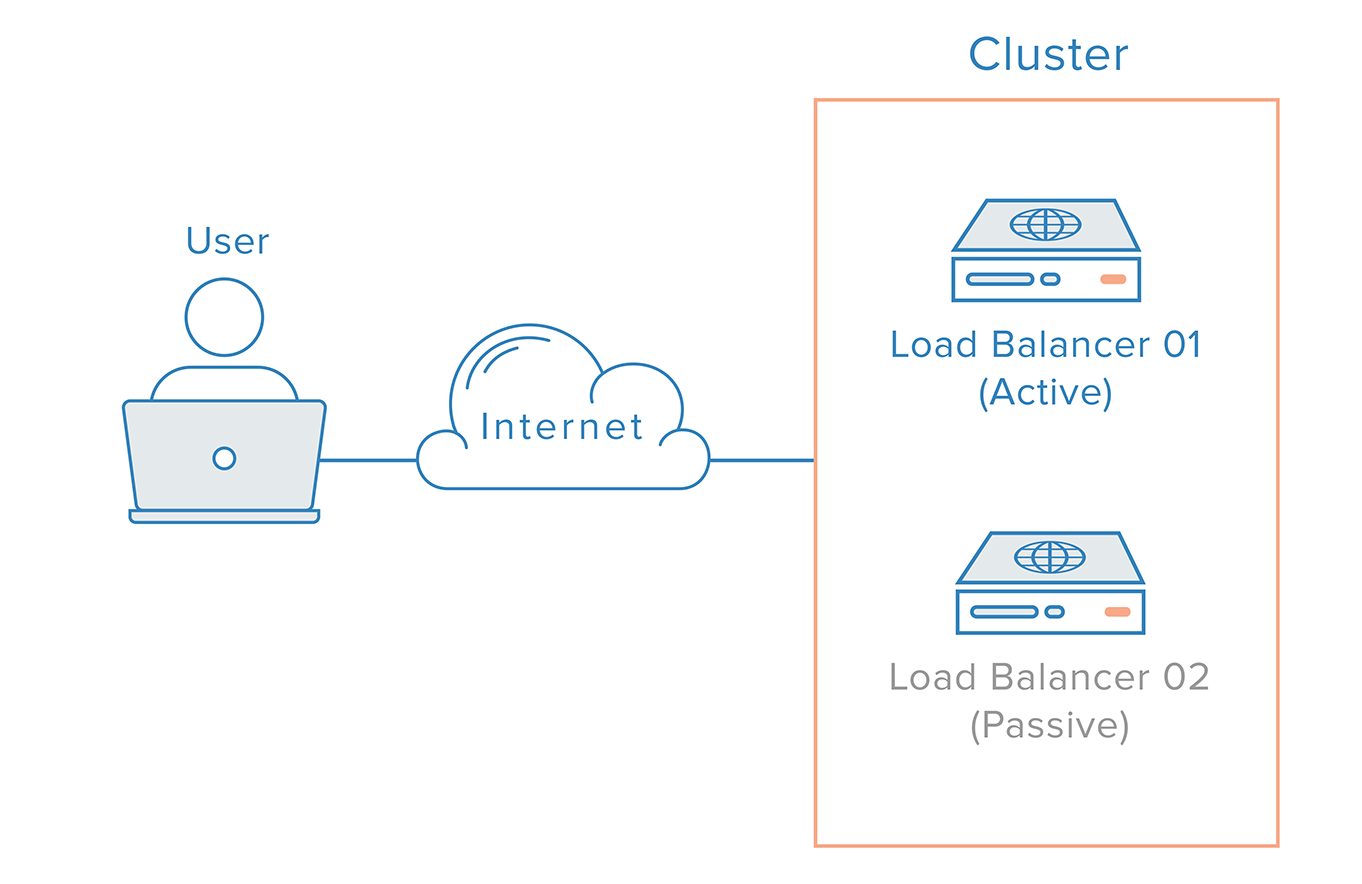
- Load Balancing (Cân bằng tải): Thay vì chỉ dùng một máy chủ web, bạn sử dụng một cụm (cluster) nhiều máy chủ. Bộ cân bằng tải sẽ đứng trước cụm máy chủ này, phân phối các yêu cầu từ người dùng đến từng máy chủ một cách hợp lý. Nếu một máy chủ bị lỗi, bộ cân bằng tải sẽ tự động ngưng gửi traffic đến nó và chuyển hướng sang các máy chủ còn lại, đảm bảo dịch vụ không bị gián đoạn.

- Failover Clustering (Cụm chuyển đổi dự phòng): Kiến trúc này thường bao gồm hai hoặc nhiều máy chủ được kết nối với nhau. Một máy chủ hoạt động chính (active), trong khi các máy chủ còn lại ở chế độ chờ (passive). Chúng liên tục “theo dõi” sức khỏe của nhau. Nếu máy chủ chính gặp sự cố, một trong các máy chủ dự phòng sẽ tự động tiếp quản vai trò, duy trì hoạt động của ứng dụng.
- Data Replication (Nhân bản dữ liệu): Đối với các hệ thống cơ sở dữ liệu, việc dự phòng máy chủ là chưa đủ. Dữ liệu cũng cần được nhân bản. Replication là quá trình sao chép dữ liệu từ một cơ sở dữ liệu chính (master) sang một hoặc nhiều cơ sở dữ liệu phụ (slave) theo thời gian thực. Điều này đảm bảo rằng nếu máy chủ chính bị lỗi, dữ liệu vẫn an toàn và có thể truy cập được từ các máy chủ phụ.
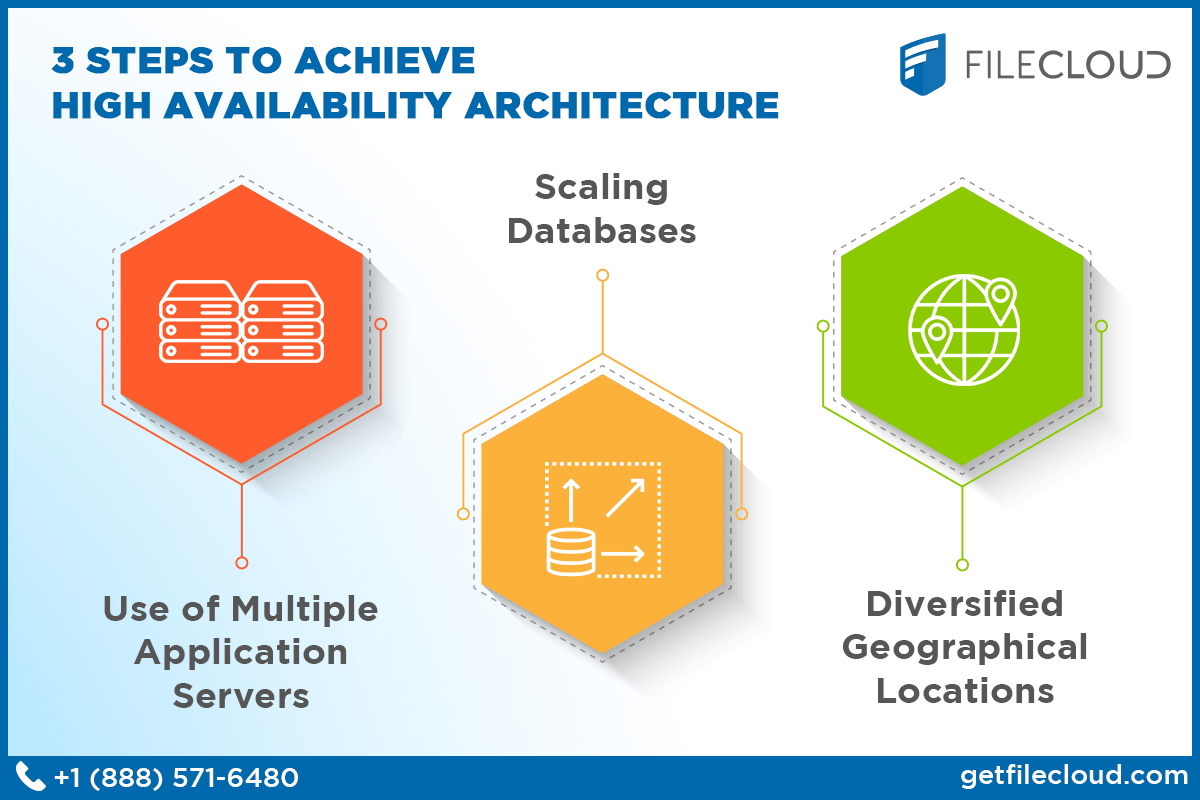
Giám sát và tự động phục hồi (Monitoring & Failover)
Việc có các thành phần dự phòng sẽ trở nên vô nghĩa nếu hệ thống không biết khi nào cần sử dụng chúng. Đây là lúc vai trò của giám sát và tự động phục hồi phát huy tác dụng.
Hệ thống giám sát (Monitoring) hoạt động như một người lính canh gác 24/7. Nó liên tục kiểm tra “sức khỏe” của mọi thành phần trong hệ thống, từ CPU, RAM, ổ cứng của máy chủ cho đến trạng thái của ứng dụng và kết nối mạng. Các công cụ giám sát sẽ thu thập dữ liệu và so sánh với các ngưỡng được thiết lập sẵn.
Khi hệ thống giám sát phát hiện một sự cố, chẳng hạn như một máy chủ không phản hồi, nó sẽ ngay lập tức kích hoạt cơ chế tự động phục hồi (Failover). Quá trình này sẽ tự động chuyển hướng lưu lượng truy cập hoặc kích hoạt máy chủ dự phòng để thay thế thành phần bị lỗi. Toàn bộ quá trình diễn ra chỉ trong vài giây hoặc thậm chí mili giây, giúp người dùng cuối gần như không cảm nhận được sự gián đoạn.
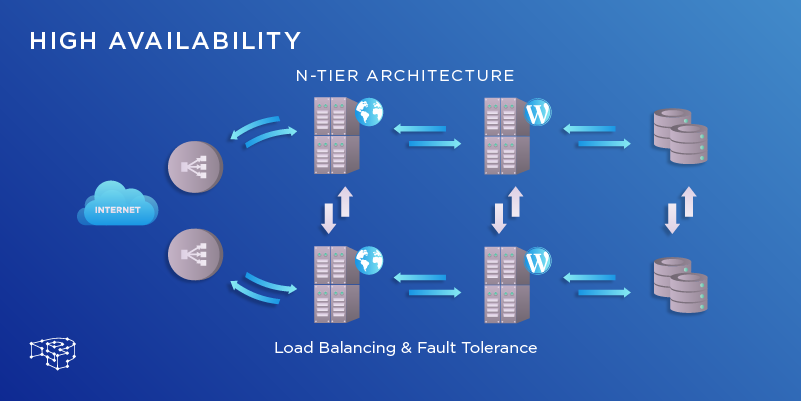
Cách đảm bảo hệ thống hoạt động liên tục và không gián đoạn
Xây dựng một hệ thống High Availability không chỉ là việc mua sắm thêm thiết bị. Nó đòi hỏi một chiến lược rõ ràng và quy trình vận hành chặt chẽ để đảm bảo hệ thống luôn sẵn sàng trong mọi tình huống.
Thiết lập hệ thống dự phòng và cân bằng tải
Bước đầu tiên là phân tích kỹ lưỡng hệ thống của bạn để xác định các điểm lỗi duy nhất (SPOF). Đó có thể là máy chủ web, máy chủ cơ sở dữ liệu, router, switch, hoặc thậm chí là một ứng dụng quan trọng. Sau khi xác định được các SPOF, bạn cần lựa chọn phương án kỹ thuật dự phòng phù hợp.
Với một website có lưu lượng truy cập trung bình, bạn có thể bắt đầu với một cụm 2 máy chủ web và một bộ cân bằng tải. Đối với các hệ thống lớn hơn, có thể cần đến nhiều máy chủ được phân bổ ở các trung tâm dữ liệu (data center) khác nhau về mặt địa lý. Tương tự, với cơ sở dữ liệu, bạn có thể chọn giữa mô hình master-slave replication đơn giản hoặc một cụm database cluster phức tạp hơn tùy thuộc vào yêu cầu về hiệu suất và tính nhất quán của dữ liệu. Việc lựa chọn đúng kỹ thuật sẽ giúp bạn cân bằng giữa chi phí đầu tư và mức độ sẵn sàng mong muốn.
Bảo trì định kỳ và nâng cấp không gây gián đoạn
Một trong những nguyên nhân phổ biến gây ra downtime chính là quá trình bảo trì và nâng cấp hệ thống. Làm thế nào để cập nhật phần mềm, vá lỗi bảo mật mà không phải tạm ngưng dịch vụ? Đây là lúc các chiến lược nâng cấp thông minh phát huy tác dụng.
Một chiến lược phổ biến là “Rolling Update” (Cập nhật cuốn chiếu). Trong một cụm máy chủ, thay vì nâng cấp tất cả cùng lúc, bạn sẽ nâng cấp từng máy chủ một. Máy chủ đang được nâng cấp sẽ tạm thời được đưa ra khỏi cụm, và bộ cân bằng tải sẽ không gửi traffic đến nó. Sau khi nâng cấp xong và kiểm tra hoạt động ổn định, nó sẽ được đưa trở lại cụm, và quá trình tiếp tục với máy chủ tiếp theo. Bằng cách này, toàn bộ hệ thống vẫn hoạt động bình thường trong suốt quá trình nâng cấp, đảm bảo tính liên tục cho dịch vụ.
Ứng dụng của High Availability trong quản trị máy chủ và dịch vụ mạng
High Availability không phải là một khái niệm xa vời, nó được ứng dụng rộng rãi trong hầu hết các dịch vụ công nghệ mà chúng ta sử dụng hàng ngày. Từ việc quản lý máy chủ, lưu trữ dữ liệu cho đến các ứng dụng doanh nghiệp quan trọng.
High Availability trong quản trị server và lưu trữ dữ liệu
Trong lĩnh vực quản trị máy chủ, HA là yếu tố cốt lõi. Các nhà cung cấp dịch vụ Cloud Hosting và VPS uy tín đều xây dựng nền tảng của họ dựa trên kiến trúc HA. Họ sử dụng các công nghệ ảo hóa là gì kết hợp với hệ thống lưu trữ phân tán (distributed storage) như Ceph. Nếu một máy chủ vật lý (hypervisor là gì) gặp sự cố, các máy chủ ảo (VPS) đang chạy trên đó sẽ được tự động di chuyển và khởi động lại trên một máy chủ vật lý khác trong cụm. Quá trình này diễn ra rất nhanh chóng, giúp giảm thiểu tối đa thời gian downtime cho khách hàng.
Đối với lưu trữ dữ liệu, các hệ thống SAN (Storage Area Network) và NAS (Network Attached Storage) hiện đại thường được thiết kế với các thành phần dự phòng như controller kép, nguồn điện kép và sử dụng các cấp độ RAID là gì (như RAID 1, RAID 5, RAID 6, RAID 10) để bảo vệ dữ liệu khỏi lỗi ổ cứng. Điều này đảm bảo rằng dữ liệu của bạn luôn an toàn và có thể truy cập được.
High Availability trong dịch vụ mạng và ứng dụng doanh nghiệp
Bạn có thắc mắc tại sao các dịch vụ email như Gmail hay các trang web lớn như Google, Facebook gần như không bao giờ “sập”? Câu trả lời chính là High Availability. Họ vận hành hàng nghìn máy chủ tại nhiều trung tâm dữ liệu trên khắp thế giới.
- Hệ thống Email: Máy chủ email thường được cấu hình theo cụm HA. Nếu một máy chủ lỗi, máy chủ khác sẽ tiếp quản để đảm bảo bạn không bỏ lỡ bất kỳ email quan trọng nào.
- Hệ thống Web: Như đã đề cập, các trang web lớn sử dụng hệ thống cân bằng tải phức tạp để phân phối traffic đến hàng trăm, hàng nghìn máy chủ web. Họ còn sử dụng Mạng phân phối nội dung (CDN) để lưu trữ bản sao nội dung tĩnh ở gần người dùng, vừa tăng tốc độ tải trang vừa giảm tải cho máy chủ chính.
- Hệ thống Database: Các hệ thống giao dịch trực tuyến (ngân hàng, thương mại điện tử) yêu cầu cơ sở dữ liệu phải luôn sẵn sàng. Họ sử dụng các cụm cơ sở dữ liệu (Database Cluster) với cơ chế nhân bản đồng bộ (synchronous replication) để đảm bảo dữ liệu luôn nhất quán và không bị mất mát khi có sự cố.
Các ví dụ thực tế về hệ thống High Availability
Lý thuyết sẽ dễ hiểu hơn khi đi kèm với các ví dụ thực tế. Hãy cùng xem cách các doanh nghiệp và dịch vụ lớn áp dụng High Availability để duy trì hoạt động kinh doanh của mình.
Ví dụ hệ thống cluster và load balancing trong doanh nghiệp
Hãy tưởng tượng một trang web bán vé máy bay lớn. Vào các đợt khuyến mãi, lượng truy cập có thể tăng đột biến gấp hàng chục, thậm chí hàng trăm lần so với ngày thường. Nếu chỉ sử dụng một máy chủ duy nhất, chắc chắn nó sẽ bị quá tải và sập ngay lập tức, gây thiệt hại lớn về doanh thu và hình ảnh.
Để giải quyết vấn đề này, doanh nghiệp sẽ triển khai một cụm máy chủ web (web server cluster) gồm nhiều server có cấu hình tương tự nhau. Phía trước cụm này là một hoặc nhiều bộ cân bằng tải (load balancer). Khi người dùng truy cập, yêu cầu sẽ được chuyển đến bộ cân bằng tải. Thiết bị này sẽ phân phối yêu cầu đến các máy chủ trong cụm theo một thuật toán nhất định (ví dụ: Round Robin – xoay vòng). Nhờ đó, tải được san sẻ đều, không có máy chủ nào bị quá tải. Nếu một trong các máy chủ web gặp sự cố, bộ cân bằng tải sẽ phát hiện và ngưng gửi yêu cầu đến nó, đảm bảo trải nghiệm của người dùng không bị ảnh hưởng.
Trường hợp sử dụng High Availability trong các dịch vụ Cloud phổ biến
Các nhà cung cấp đám mây hàng đầu như Amazon Web Services (AWS), Google Cloud Platform (GCP) và Microsoft Azure đã biến High Availability thành một dịch vụ mà người dùng có thể dễ dàng tiếp cận.
Một ví dụ điển hình là khái niệm “Availability Zones” (AZ) của AWS. Mỗi AZ là một hoặc nhiều trung tâm dữ liệu riêng biệt trong cùng một khu vực địa lý, có nguồn điện, hệ thống làm mát và mạng lưới độc lập. Bằng cách triển khai ứng dụng của mình trên nhiều AZ, bạn có thể đảm bảo rằng nếu có sự cố xảy ra ở một AZ (ví dụ: mất điện, thiên tai), ứng dụng của bạn vẫn hoạt động bình thường trên các AZ còn lại. Kết hợp với các dịch vụ như Auto Scaling (tự động tăng/giảm số lượng máy chủ theo tải) và Elastic Load Balancing (cân bằng tải linh hoạt), việc xây dựng một kiến trúc HA mạnh mẽ trên nền tảng đám mây trở nên đơn giản và hiệu quả hơn bao giờ hết.

Common Issues/Troubleshooting
Mặc dù đã triển khai High Availability, không có hệ thống nào là hoàn hảo 100%. Đôi khi, sự cố vẫn có thể xảy ra. Hiểu rõ các vấn đề phổ biến và cách khắc phục sẽ giúp bạn vận hành hệ thống HA hiệu quả hơn.
Nguyên nhân phổ biến dẫn đến downtime dù đã triển khai HA
Bạn có thể ngạc nhiên khi biết rằng ngay cả với kiến trúc dự phòng, hệ thống vẫn có thể bị downtime. Dưới đây là một vài nguyên nhân phổ biến:
- Bỏ sót điểm lỗi duy nhất (SPOF): Đôi khi chúng ta quá tập trung vào việc dự phòng cho máy chủ mà quên mất các thành phần khác. Chính bộ cân bằng tải, router, switch mạng hay thậm chí là hệ thống lưu trữ cũng có thể trở thành SPOF nếu không được thiết kế dự phòng.
- Lỗi cấu hình: Cấu hình sai các tham số của cụm (cluster) hoặc bộ cân bằng tải là một nguyên nhân rất phổ biến. Ví dụ, thiết lập sai thời gian “timeout” có thể khiến hệ thống failover quá sớm hoặc quá muộn.
- Hiện tượng “Split-Brain”: Trong một cụm failover, “split-brain” xảy ra khi các nút trong cụm mất kết nối với nhau nhưng vẫn hoạt động độc lập. Điều này dẫn đến tình trạng cả hai nút đều nghĩ rằng mình là nút chính (active), gây ra xung đột và hỏng hóc dữ liệu.
- Lỗi phần mềm: Một bản cập nhật phần mềm bị lỗi có thể ảnh hưởng đến tất cả các nút trong cụm cùng một lúc, khiến toàn bộ hệ thống dự phòng trở nên vô dụng.
Cách xử lý sự cố tự động failover không hoạt động hiệu quả
Khi bạn phát hiện cơ chế tự động chuyển đổi dự phòng (failover) không hoạt động như mong đợi, đừng hoảng sợ. Hãy thực hiện các bước sau để chẩn đoán và xử lý:
- Kiểm tra log hệ thống: Đây là bước đầu tiên và quan trọng nhất. Log của hệ thống cluster, cân bằng tải và các ứng dụng liên quan sẽ cho bạn biết chính xác điều gì đã xảy ra tại thời điểm sự cố.
- Kiểm tra kết nối mạng: Đảm bảo rằng các kết nối mạng giữa các nút trong cụm và giữa các nút với hệ thống lưu trữ vẫn thông suốt. Đặc biệt chú ý đến kết nối “heartbeat” – đường mạng riêng dùng để các nút “theo dõi” sức khỏe của nhau.
- Kiểm tra dịch vụ giám sát: Xác minh rằng các dịch vụ chịu trách nhiệm giám sát và kích hoạt failover đang hoạt động bình thường. Đôi khi chính các dịch vụ này bị treo hoặc gặp lỗi.
- Thực hiện failover thủ công: Trong một khoảng thời gian bảo trì, hãy thử kích hoạt quá trình failover bằng tay để kiểm tra xem nó có hoạt động đúng quy trình hay không. Điều này giúp phát hiện các vấn đề tiềm ẩn trước khi sự cố thực sự xảy ra.
Best Practices
Để triển khai và duy trì một hệ thống High Availability thành công, việc tuân thủ các nguyên tắc và kinh nghiệm tốt nhất (Best Practices) là vô cùng quan trọng. Dưới đây là những lời khuyên cốt lõi bạn nên ghi nhớ.
- Luôn có kế hoạch sao lưu đầy đủ và kiểm tra định kỳ: HA giúp hệ thống hoạt động liên tục, nhưng nó không thay thế được việc sao lưu (backup) là gì. Hãy đảm bảo bạn có một chiến lược backup toàn diện cho dữ liệu và cấu hình hệ thống. Quan trọng hơn, hãy định kỳ kiểm tra, khôi phục thử các bản backup để chắc chắn rằng chúng hoạt động khi cần.
- Triển khai hệ thống giám sát toàn diện và cảnh báo sớm: Đừng chỉ giám sát trạng thái uptime/downtime. Hãy giám sát sâu hơn các chỉ số hiệu suất như CPU, RAM, độ trễ mạng, số lượng kết nối… Cài đặt hệ thống cảnh báo sớm qua email, SMS hoặc các ứng dụng chat để đội ngũ quản trị có thể phát hiện và xử lý vấn đề trước khi nó ảnh hưởng đến người dùng.
- Không lạm dụng quá nhiều tầng dự phòng làm phức tạp hệ thống: Mặc dù dự phòng là tốt, nhưng việc thêm quá nhiều lớp dự phòng không cần thiết có thể làm hệ thống trở nên cực kỳ phức tạp, khó quản lý và gỡ rối. Hãy giữ cho kiến trúc của bạn đơn giản và hiệu quả nhất có thể.
- Thường xuyên cập nhật kiến thức và nâng cấp thiết bị, phần mềm: Công nghệ thay đổi liên tục. Hãy dành thời gian để cập nhật các kiến thức mới về HA, các kỹ thuật mới và các lỗ hổng bảo mật. Lên kế hoạch nâng cấp phần cứng và phần mềm định kỳ để đảm bảo hệ thống luôn hoạt động ở hiệu suất cao nhất và được bảo vệ tốt nhất.

Kết luận
Qua bài viết này, chúng ta đã cùng nhau đi sâu vào thế giới của High Availability là gì. Từ định nghĩa “High Availability là gì”, tầm quan trọng không thể phủ nhận của nó đối với sự sống còn của doanh nghiệp, cho đến việc khám phá các kỹ thuật cốt lõi như cân bằng tải, failover cluster và nhân bản dữ liệu. HA không chỉ là một giải pháp công nghệ, mà là một chiến lược thiết yếu giúp đảm bảo hệ thống của bạn luôn vững vàng trước những sự cố bất ngờ.
Việc đầu tư vào một kiến trúc có tính sẵn sàng cao giúp tối ưu hóa vận hành, bảo vệ doanh thu, củng cố uy tín thương hiệu và mang lại trải nghiệm tốt nhất cho người dùng. Mặc dù quá trình triển khai có thể phức tạp và tốn kém ban đầu, nhưng lợi ích lâu dài mà nó mang lại là vô giá.
Bước tiếp theo dành cho bạn là gì? Hãy bắt đầu bằng việc đánh giá lại hệ thống hiện tại của mình để xác định những điểm yếu và nhu cầu về tính sẵn sàng. Từ đó, bạn có thể nghiên cứu và lựa chọn giải pháp phù hợp với quy mô và ngân sách của mình. Đừng ngần ngại bắt đầu từ những bước nhỏ, như triển khai cân bằng tải cho máy chủ web, và dần dần xây dựng một hệ thống hoàn chỉnh hơn. Chúc bạn thành công trên hành trình chinh phục uptime 99.999%

