Chắc hẳn bạn đã quá quen thuộc với Nagios, một công cụ giám sát hệ thống mạnh mẽ và đáng tin cậy. Tuy nhiên, khi quy mô hệ thống ngày càng mở rộng, việc quản lý hàng trăm, thậm chí hàng ngàn cảnh báo từ Nagios trở thành một thách thức không hề nhỏ. Bạn có thường xuyên cảm thấy bị “nhấn chìm” trong một biển thông báo, khó phân biệt đâu là vấn đề thực sự nghiêm trọng cần xử lý ngay lập tức? Đây chính là lúc Alerta xuất hiện như một giải pháp cứu cánh. Bằng cách tích hợp Nagios với Alerta, bạn có thể tập trung hóa, lọc nhiễu và quản lý cảnh báo một cách thông minh và hiệu quả hơn rất nhiều. Bài viết này sẽ là kim chỉ nam, hướng dẫn bạn chi tiết từng bước để cài đặt và tích hợp hai công cụ này trên CentOS 7, giúp bạn xây dựng một hệ thống giám sát chủ động và phản ứng nhanh nhạy hơn.
Giới thiệu về hệ thống cảnh báo Nagios và Alerta
Để xây dựng một hệ thống giám sát hoàn chỉnh, việc hiểu rõ vai trò và thế mạnh của từng công cụ là vô cùng quan trọng. Nagios và Alerta là một cặp đôi hoàn hảo, bù trừ những điểm yếu cho nhau để tạo ra một giải pháp quản lý cảnh báo toàn diện.
Nagios là gì và vai trò trong giám sát hệ thống
Nagios được xem là một trong những công cụ giám sát mã nguồn mở “lão làng” và phổ biến nhất trong thế giới quản trị hệ thống. Chức năng chính của nó là liên tục kiểm tra trạng thái của các máy chủ, dịch vụ, tài nguyên mạng như CPU, RAM, ổ đĩa, hay các dịch vụ web, email. Khi phát hiện một sự cố hoặc một chỉ số vượt ngưỡng cho phép, Nagios sẽ ngay lập tức gửi đi một thông báo cảnh báo.
Về bản chất, Nagios thực hiện rất tốt vai trò của một “người lính gác” mẫn cán, không bao giờ bỏ sót bất kỳ dấu hiệu bất thường nào. Tuy nhiên, hạn chế của nó cũng chính từ sự mẫn cán này. Trong một hệ thống lớn, Nagios có thể tạo ra một lượng cảnh báo khổng lồ, gây ra tình trạng “nhiễu thông tin”. Các cảnh báo thường riêng lẻ, thiếu sự liên kết, khiến đội ngũ quản trị khó lòng nhìn thấy bức tranh toàn cảnh và xác định đâu là nguyên nhân gốc rễ của sự cố.
Alerta và lợi ích khi tích hợp với Nagios
Alerta không phải là một công cụ giám sát, mà là một nền tảng tập trung và xử lý cảnh báo. Hãy tưởng tượng Alerta như một “trung tâm chỉ huy”, nơi tất cả thông tin từ những “người lính gác” (như Nagios, Zabbix, Prometheus…) được gửi về. Tại đây, Alerta sẽ xử lý, tổng hợp và hiển thị chúng một cách trực quan.
Lợi ích khi tích hợp Alerta với Nagios là vô cùng rõ rệt:
- Hợp nhất cảnh báo: Tất cả cảnh báo từ Nagios (và nhiều nguồn khác) sẽ được gom về một nơi duy nhất, giúp bạn có cái nhìn tổng thể.
- Giảm nhiễu hiệu quả: Alerta có khả năng tự động loại bỏ các cảnh báo trùng lặp (deduplication) hoặc nhóm các cảnh báo liên quan đến cùng một sự cố, giúp bạn tập trung vào những gì quan trọng nhất.
- Phản hồi nhanh hơn: Giao diện của Alerta cho phép bạn dễ dàng xem, xác nhận (acknowledge), phân công và đóng các cảnh báo.
- Quản lý trực quan: Dashboard của Alerta cung cấp biểu đồ, bộ lọc mạnh mẽ, giúp bạn dễ dàng theo dõi và phân tích tình hình hệ thống theo thời gian thực.

Các bước cài đặt Alerta trên CentOS 7
Để tích hợp thành công, bước đầu tiên và quan trọng nhất là cài đặt Alerta server trên hệ điều hành CentOS 7. Quá trình này đòi hỏi sự chuẩn bị kỹ lưỡng về môi trường và thực hiện chính xác các câu lệnh.
Chuẩn bị môi trường và yêu cầu hệ thống
Trước khi bắt đầu cài đặt, hãy đảm bảo hệ thống của bạn đáp ứng các yêu cầu cơ bản. Alerta cần một môi trường chạy ổn định để có thể xử lý cảnh báo liên tục.
Các thành phần cần thiết bao gồm:
- Hệ điều hành: CentOS 7 đã được cài đặt và cấu hình mạng cơ bản.
- Quyền truy cập: Bạn cần có quyền
root hoặc quyền sudo để thực hiện các lệnh cài đặt.
- Python và pip: Alerta được xây dựng trên nền tảng Python, do đó bạn cần cài đặt Python (phiên bản 2.7 hoặc 3.6+) và trình quản lý gói
pip.
- Database: Alerta cần một cơ sở dữ liệu để lưu trữ cảnh báo. MongoDB là lựa chọn phổ biến và được khuyến nghị.
Đầu tiên, hãy cập nhật hệ thống của bạn lên phiên bản mới nhất để đảm bảo tính ổn định và bảo mật:
sudo yum update -y
Tiếp theo, cài đặt các gói phụ thuộc cần thiết, bao gồm cả Python và pip:
sudo yum install -y epel-release
sudo yum install -y python3 python3-pip mongodb-server mongodb
Hướng dẫn chi tiết cài đặt Alerta
Sau khi môi trường đã sẵn sàng, chúng ta sẽ tiến hành cài đặt Alerta server và cấu hình cơ sở dữ liệu MongoDB.
1. Cài đặt Alerta Server:
Sử dụng pip để cài đặt Alerta server và các plugin cần thiết. Plugin mongodb là bắt buộc nếu bạn sử dụng MongoDB làm database.
sudo pip3 install alerta-server[mongodb]
2. Cấu hình và khởi động MongoDB:
Alerta cần MongoDB để hoạt động. Hãy khởi động dịch vụ MongoDB và cho phép nó tự khởi động cùng hệ thống.
sudo systemctl start mongod
sudo systemctl enable mongod
3. Tạo file cấu hình cho Alerta:
Tạo một file cấu hình đơn giản cho Alerta server. File này sẽ cho Alerta biết cách kết nối với MongoDB.
sudo nano /etc/alertad.conf
Thêm nội dung sau vào file:
[DEFAULT]
SECRET_KEY = 'p_!secret_key_for_alerta_!q'
DATABASE_URL = 'mongodb://localhost:27017/alerta'
Hãy thay đổi SECRET_KEY thành một chuỗi ngẫu nhiên và phức tạp của riêng bạn để tăng cường bảo mật.
4. Khởi động và kiểm tra trạng thái Alerta:
Cuối cùng, khởi động dịch vụ Alerta server.
sudo alertad run
Để dịch vụ chạy nền, bạn nên tạo một file service systemd. Tuy nhiên, để kiểm tra nhanh, lệnh trên là đủ. Mở một terminal khác và dùng curl để kiểm tra xem API của Alerta đã hoạt động chưa:
curl http://localhost:8080/api/heartbeat
Nếu bạn nhận lại một phản hồi JSON có chứa “status”: “ok”, xin chúc mừng, bạn đã cài đặt thành công Alerta server!
Cấu hình Nagios gửi cảnh báo đến Alerta
Khi Alerta server đã sẵn sàng, bước tiếp theo là “dạy” cho Nagios cách gửi thông tin cảnh báo đến trung tâm chỉ huy mới này. Việc này được thực hiện thông qua việc thiết lập một kịch bản thông báo (notification script) tùy chỉnh.
Thiết lập Nagios notification command
Chúng ta sẽ tạo một script đơn giản, có thể bằng Python hoặc Bash, để lấy thông tin từ Nagios và gửi nó đến API của Alerta dưới định dạng JSON mà Alerta có thể hiểu được.
1. Tạo Script gửi cảnh báo:
Đầu tiên, hãy cài đặt client của Alerta trên máy chủ Nagios.
sudo pip3 install alerta
Bây giờ, tạo một script có tên là alerta-nagios.py trong thư mục plugin của Nagios (thường là /usr/local/nagios/libexec/).
sudo nano /usr/local/nagios/libexec/alerta-nagios.py
Dán nội dung sau vào file:
#!/usr/bin/env python3
import os
import sys
from alerta import Client
alerta = Client(endpoint='http://your-alerta-server:8080/api')
event = os.environ.get('NAGIOS_SERVICEDISPLAYNAME') or os.environ.get('NAGIOS_HOSTDISPLAYNAME')
resource = os.environ.get('NAGIOS_HOSTNAME')
severity = os.environ.get('NAGIOS_SERVICESTATE', 'unknown').lower()
if severity == 'ok' or severity == 'up':
severity = 'ok'
elif severity == 'warning':
severity = 'warning'
elif severity == 'critical' or severity == 'down':
severity = 'critical'
else:
severity = 'unknown'
group = os.environ.get('NAGIOS_HOSTGROUPNAME')
text = os.environ.get('NAGIOS_SERVICEOUTPUT') or os.environ.get('NAGIOS_HOSTOUTPUT')
try:
alerta.send_alert(
resource=resource,
event=event,
group=group,
severity=severity,
text=text,
environment='Production',
service=[os.environ.get('NAGIOS_SERVICEDESC', 'nagios')],
tags=[f"nagios_notificationtype={os.environ.get('NAGIOS_NOTIFICATIONTYPE')}"]
)
except Exception as e:
print(e)
sys.exit(1)
print('Alert sent to Alerta successfully.')
sys.exit(0)
Lưu ý: Thay http://your-alerta-server:8080/api bằng địa chỉ IP hoặc tên miền và cổng của Alerta server của bạn. Đừng quên cấp quyền thực thi cho script:
sudo chmod +x /usr/local/nagios/libexec/alerta-nagios.py
2. Cấu hình Nagios Command:
Bây giờ, bạn cần định nghĩa một command mới trong Nagios để gọi script này. Mở file commands.cfg của Nagios (thường ở /usr/local/nagios/etc/objects/commands.cfg) và thêm vào:
define command{
command_name notify-service-by-alerta
command_line /usr/bin/python3 /usr/local/nagios/libexec/alerta-nagios.py
}
define command{
command_name notify-host-by-alerta
command_line /usr/bin/python3 /usr/local/nagios/libexec/alerta-nagios.py
}
3. Cấu hình Contact và Service/Host:
Cuối cùng, chỉnh sửa file contacts.cfg để tạo một contact mới sử dụng command vừa tạo. Sau đó, gán contact này vào các host hoặc service mà bạn muốn gửi cảnh báo đến Alerta.

Kiểm tra kết nối và nhận cảnh báo trên Alerta
Sau khi đã hoàn tất cấu hình, hãy khởi động lại dịch vụ Nagios để áp dụng thay đổi.
sudo systemctl restart nagios
Để kiểm tra, bạn có thể chủ động tạo ra một cảnh báo, ví dụ như tạm dừng một dịch vụ đang được Nagios giám sát. Chờ một vài phút để Nagios phát hiện ra sự thay đổi trạng thái và gửi đi thông báo.
Bây giờ, hãy truy cập vào giao diện web của Alerta. Nếu mọi thứ được cấu hình chính xác, bạn sẽ thấy một cảnh báo mới xuất hiện trên dashboard. Cảnh báo sẽ chứa đầy đủ thông tin mà Nagios đã gửi qua như tên host, tên dịch vụ, trạng thái và thông điệp lỗi. Giao diện của Alerta rất trực quan, cho phép bạn lọc, tìm kiếm và xem chi tiết từng cảnh báo một cách dễ dàng. Đây là bằng chứng xác nhận rằng cầu nối giữa Nagios và Alerta đã được thiết lập thành công.
Kiểm tra và theo dõi hoạt động hệ thống cảnh báo tích hợp
Việc cài đặt và cấu hình thành công chỉ là bước khởi đầu. Để hệ thống cảnh báo tích hợp thực sự phát huy hiệu quả, bạn cần liên tục theo dõi, kiểm tra và tinh chỉnh nó cho phù hợp với môi trường hoạt động thực tế.
Giám sát luồng cảnh báo thực tế
Sau khi tích hợp, Alerta dashboard sẽ trở thành trung tâm điều khiển chính của bạn. Hãy dành thời gian quan sát luồng cảnh báo đổ về từ Nagios trong vài ngày. Bạn sẽ bắt đầu nhận thấy những quy luật nhất định. Ví dụ, một sự cố mạng có thể gây ra hàng loạt cảnh báo từ nhiều máy chủ khác nhau. Alerta sẽ giúp bạn dễ dàng nhận ra điều này bằng cách nhóm các cảnh báo có cùng tài nguyên hoặc thông điệp.
Hãy chú ý đến các cảnh báo bị trùng lặp (deduplicated). Cột “Count” trên dashboard Alerta cho bạn biết một cảnh báo đã xảy ra bao nhiêu lần. Một cảnh báo có “Count” cao có thể chỉ ra một vấn đề “chập chờn” (flapping) cần được ưu tiên điều tra. Bằng cách quan sát luồng cảnh báo thực tế, bạn sẽ có cơ sở dữ liệu để đưa ra các quyết định tối ưu hóa hệ thống ở bước tiếp theo.
Điều chỉnh cấu hình để tối ưu hoạt động
Dựa trên những quan sát từ thực tế, bạn có thể bắt đầu tinh chỉnh hệ thống để nó hoạt động thông minh hơn. Alerta cung cấp nhiều công cụ mạnh mẽ để bạn làm điều này.
- Thiết lập quy tắc (Rules): Bạn có thể tạo các quy tắc trong Alerta để tự động xử lý cảnh báo. Ví dụ, tự động đóng một cảnh báo “OK” khi Nagios báo dịch vụ đã phục hồi, hoặc tăng mức độ nghiêm trọng của một cảnh báo nếu nó lặp lại quá nhiều lần trong một khoảng thời gian ngắn.
- Nhóm cảnh báo (Grouping): Tinh chỉnh cách Alerta nhóm các cảnh báo. Bạn có thể nhóm theo ứng dụng, vị trí địa lý, hoặc bất kỳ tiêu chí nào phù hợp với logic vận hành của bạn.
- Phân quyền người dùng: Tạo các tài khoản người dùng khác nhau trên Alerta và gán quyền truy cập tương ứng. Ví dụ, team network chỉ có thể xem và xử lý các cảnh báo liên quan đến thiết bị mạng.
- Kiểm tra nhật ký: Thường xuyên kiểm tra nhật ký của cả Nagios và Alerta để phát hiện sớm các vấn đề như lỗi gửi nhận thông báo hoặc hiệu suất xử lý chậm. Việc này giúp đảm bảo hệ thống cảnh báo của bạn luôn hoạt động ổn định và đáng tin cậy.
Mẹo và lưu ý khi quản lý cảnh báo hiệu quả
Một hệ thống cảnh báo mạnh mẽ không chỉ nằm ở công cụ mà còn ở cách chúng ta vận hành nó. Dưới đây là một số mẹo và lưu ý quan trọng để bạn quản lý cảnh báo một cách hiệu quả, tránh tình trạng “mệt mỏi vì cảnh báo” (alert fatigue).
Tối ưu giảm thiểu cảnh báo giả và trùng lặp
Cảnh báo giả (false positives) là kẻ thù lớn nhất của đội ngũ vận hành. Khi nhận quá nhiều cảnh báo không có thật, họ sẽ dần mất đi sự tin tưởng và có xu hướng bỏ qua cả những cảnh báo quan trọng.
- Thiết lập đúng ngưỡng cảnh báo trong Nagios: Đừng đặt ngưỡng quá nhạy cảm. Hãy phân tích hiệu suất hệ thống trong điều kiện hoạt động bình thường để xác định các ngưỡng hợp lý cho CPU, RAM, disk… Ví dụ, thay vì cảnh báo khi CPU đạt 70%, bạn có thể đặt ngưỡng là “CPU trên 90% trong vòng 5 phút liên tục”. Xem thêm bài viết Hệ điều hành là gì để hiểu thêm về cách hệ điều hành quản lý tài nguyên như CPU, RAM trong các môi trường máy chủ.
- Sử dụng quy tắc lọc và tương quan trên Alerta: Hãy tận dụng sức mạnh của Alerta để xây dựng các quy tắc thông minh. Ví dụ, tạo một quy tắc “nếu cảnh báo về việc router chính bị down xuất hiện, hãy tự động ẩn (shelve) tất cả các cảnh báo từ server phía sau router đó trong 30 phút”. Điều này giúp bạn tập trung vào việc xử lý nguyên nhân gốc rễ thay vì bị phân tâm bởi các triệu chứng.
Quản lý cảnh báo với phản hồi nhanh và phối hợp nhóm
Một cảnh báo chỉ thực sự có giá trị khi nó được xử lý kịp thời. Việc xây dựng một quy trình phản hồi rõ ràng và hiệu quả là yếu tố then chốt.
- Sử dụng các tính năng của Alerta: Khi một cảnh báo mới xuất hiện, người đầu tiên thấy nó nên ngay lập tức “Xác nhận” (Acknowledge) để cả nhóm biết rằng đã có người tiếp nhận. Sử dụng tính năng ghi chú (notes) để cập nhật quá trình điều tra sự cố.
- Phân công rõ ràng: Nếu có thể, hãy phân công cảnh báo cho một cá nhân hoặc một nhóm cụ thể chịu trách nhiệm xử lý. Điều này tránh tình trạng “cha chung không ai khóc”.
- Đào tạo đội ngũ vận hành: Đảm bảo mọi thành viên trong nhóm đều hiểu rõ quy trình xử lý cảnh báo, biết cách sử dụng Alerta và hiểu ý nghĩa của các loại cảnh báo khác nhau. Việc đào tạo thường xuyên giúp nâng cao kỹ năng và tốc độ phản ứng của toàn đội.
Các vấn đề thường gặp và cách xử lý
Trong quá trình cài đặt và vận hành, bạn có thể gặp phải một số sự cố. Việc nhận biết nguyên nhân và biết cách khắc phục sẽ giúp bạn tiết kiệm rất nhiều thời gian và công sức.
Nagios không gửi được cảnh báo đến Alerta
Đây là vấn đề phổ biến nhất sau khi cấu hình. Nếu bạn không thấy cảnh báo từ Nagios trên dashboard Alerta, hãy kiểm tra các điểm sau:
- Kiểm tra kết nối mạng: Từ máy chủ Nagios, hãy thử dùng lệnh
ping hoặc curl đến địa chỉ API của Alerta server để đảm bảo kết nối mạng thông suốt. Hãy chắc chắn rằng không có tường lửa nào chặn kết nối trên cổng 8080 (hoặc cổng bạn đã cấu hình).
- Kiểm tra API Keys (nếu có): Nếu bạn đã bật xác thực trên Alerta, hãy đảm bảo API key trong script
alerta-nagios.py là chính xác và có đủ quyền để gửi cảnh báo.
- Xem lại script notification: Chạy thử script
alerta-nagios.py bằng tay từ dòng lệnh trên server Nagios.
NAGIOS_HOSTNAME=test-host NAGIOS_SERVICEDISPLAYNAME=test-service NAGIOS_SERVICESTATE=CRITICAL /usr/bin/python3 /usr/local/nagios/libexec/alerta-nagios.py
Quan sát kết quả trả về. Nếu có lỗi, thông báo lỗi sẽ cho bạn biết vấn đề nằm ở đâu.
- Kiểm tra quyền thực thi: Đảm bảo file script có quyền thực thi cho người dùng
nagios. Lệnh sudo chmod +x /usr/local/nagios/libexec/alerta-nagios.py sẽ giải quyết vấn đề này.
- Kiểm tra log của Nagios: File
nagios.log (thường ở /usr/local/nagios/var/nagios.log) sẽ ghi lại mọi hoạt động, bao gồm cả việc thực thi các lệnh notification và các lỗi phát sinh.
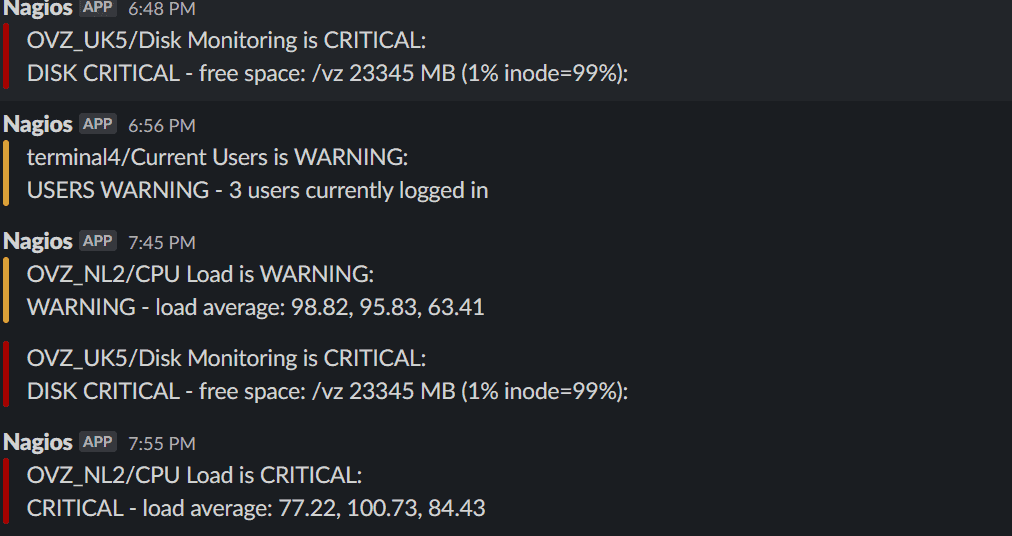
Alerta không hiển thị cảnh báo từ Nagios
Nếu bạn đã xác nhận Nagios gửi cảnh báo thành công nhưng Alerta vẫn không hiển thị, vấn đề có thể nằm ở phía Alerta server.
- Kiểm tra trạng thái dịch vụ Alerta: Đảm bảo rằng tiến trình
alertad đang chạy trên server Alerta. Sử dụng lệnh systemctl status alertad (nếu bạn đã tạo file service) hoặc ps aux | grep alertad để kiểm tra.
- Kiểm tra database: Alerta phụ thuộc vào cơ sở dữ liệu (MongoDB). Hãy chắc chắn rằng dịch vụ
mongod đang hoạt động ổn định. Nếu database gặp sự cố, Alerta sẽ không thể lưu và hiển thị cảnh báo mới.
- Xem log của Alerta: Kiểm tra file log của Alerta (vị trí file log phụ thuộc vào cách bạn chạy dịch vụ). Log sẽ cho bạn biết nếu có lỗi khi xử lý các yêu cầu API đến, ví dụ như lỗi kết nối database hay lỗi phân tích dữ liệu JSON.
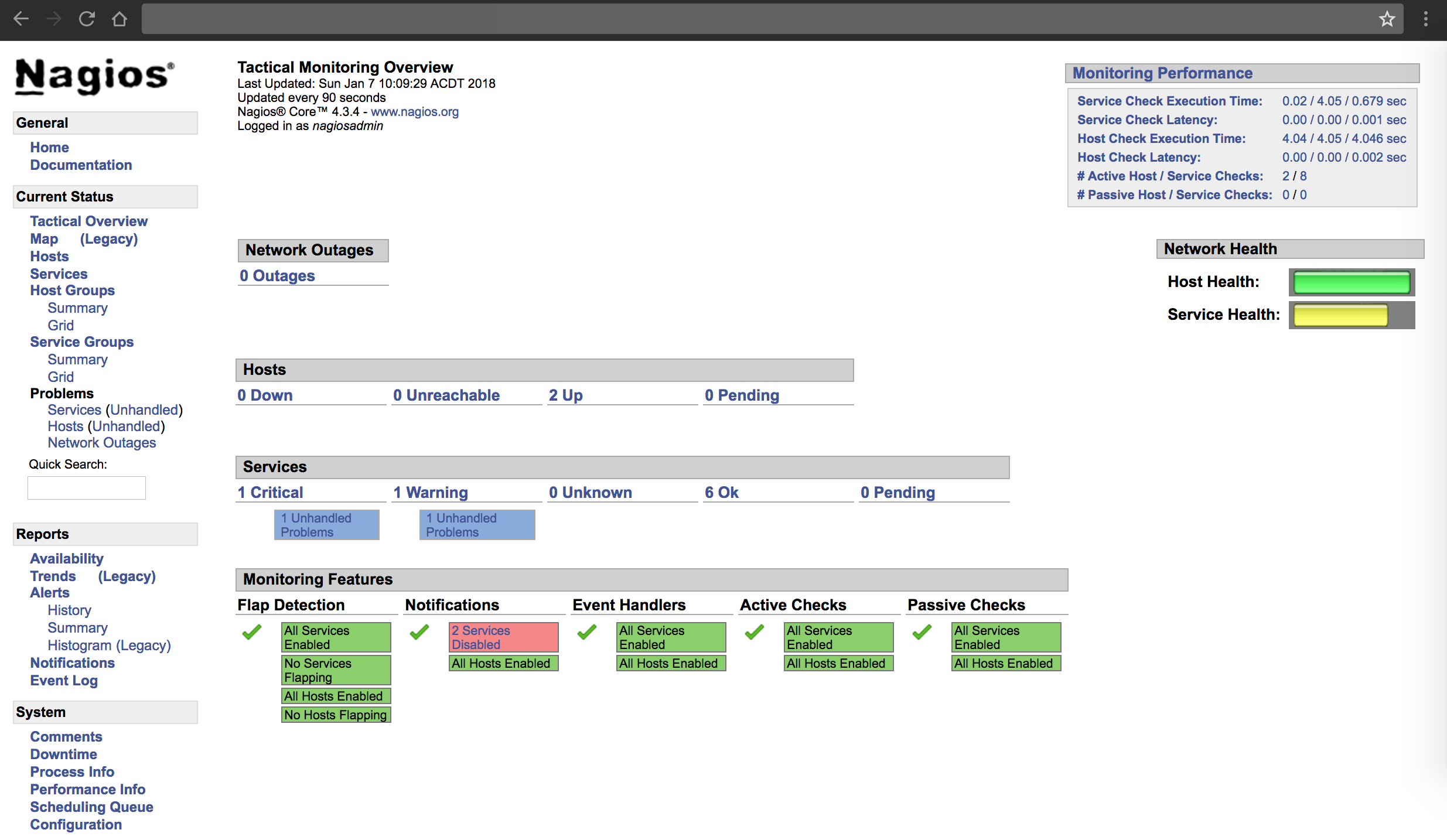
Những thực hành tốt nhất khi quản lý cảnh báo
Để duy trì một hệ thống giám sát và cảnh báo hiệu quả trong dài hạn, việc tuân thủ các thực hành tốt nhất là điều không thể thiếu. Đây là những nguyên tắc giúp hệ thống của bạn luôn mạnh mẽ, linh hoạt và đáng tin cậy.
- Luôn cập nhật phiên bản mới: Cả Nagios và Alerta đều là các dự án mã nguồn mở được phát triển tích cực. Việc thường xuyên cập nhật lên phiên bản mới nhất giúp bạn được hưởng lợi từ các tính năng mới, cải thiện hiệu suất và quan trọng nhất là các bản vá bảo mật.
- Định kỳ rà soát và tinh chỉnh ngưỡng cảnh báo: Môi trường IT không ngừng thay đổi. Một ngưỡng cảnh báo hợp lý của ngày hôm nay có thể trở nên lỗi thời vào tháng sau. Hãy lên lịch rà soát định kỳ (ví dụ, hàng quý) để đánh giá lại tất cả các ngưỡng cảnh báo và điều chỉnh chúng cho phù hợp với tình hình hoạt động hiện tại.
- Backup là gì: Tích hợp các kênh thông báo đa dạng: Alerta có khả năng tích hợp với rất nhiều dịch vụ bên thứ ba. Đừng chỉ dựa vào email. Hãy cấu hình Alerta để gửi các cảnh báo quan trọng đến các kênh giao tiếp tức thời như Slack, Microsoft Teams, hoặc thậm chí là gửi SMS/gọi điện thoại qua các dịch vụ như PagerDuty cho các sự cố cực kỳ nghiêm trọng.
- Không chủ quan bỏ qua cảnh báo nhỏ: Một cảnh báo “Warning” lặp đi lặp lại có thể là dấu hiệu sớm của một sự cố lớn sắp xảy ra. Hãy xây dựng văn hóa không bỏ qua bất kỳ cảnh báo nào, nhưng đồng thời phải biết cách ưu tiên xử lý dựa trên mức độ nghiêm trọng và tác động kinh doanh.
- Thường xuyên đào tạo và nâng cao kỹ năng cho đội ngũ: Công nghệ thay đổi, và đội ngũ của bạn cũng cần phát triển theo. Tổ chức các buổi đào tạo định kỳ về cách sử dụng Nagios, Alerta, các quy trình xử lý sự cố và các kỹ năng chẩn đoán lỗi mới. Một đội ngũ có kỹ năng tốt chính là tài sản quý giá nhất của hệ thống giám sát.

Kết luận
Việc tích hợp Nagios với Alerta trên CentOS 7 không chỉ là một nâng cấp kỹ thuật, mà là một sự thay đổi về tư duy trong việc quản lý và giám sát hệ thống. Thay vì bị động phản ứng với một loạt cảnh báo rời rạc từ Nagios, bạn giờ đây đã có một trung tâm chỉ huy thông minh – Alerta, giúp tập trung hóa, lọc nhiễu, và cung cấp cái nhìn toàn cảnh về sức khỏe của toàn bộ hạ tầng. Quy trình này giúp giảm thiểu đáng kể tình trạng “mệt mỏi vì cảnh báo”, tăng tốc độ phản hồi sự cố và cho phép đội ngũ của bạn tập trung vào những vấn đề thực sự quan trọng.
Bằng cách làm theo hướng dẫn chi tiết trong bài viết, từ việc chuẩn bị môi trường, cài đặt, cấu hình cho đến các mẹo vận hành hiệu quả, bạn hoàn toàn có thể tự mình xây dựng một hệ thống cảnh báo mạnh mẽ và chuyên nghiệp. Đừng ngần ngại bắt đầu triển khai ngay hôm nay để cải thiện khả năng giám sát và giảm thiểu rủi ro cho hệ thống của mình.
Bước tiếp theo cho bạn có thể là khám phá các plugin phong phú của Alerta để tích hợp thêm nhiều nguồn cảnh báo khác, xây dựng các kịch bản tự động hóa phản hồi, hoặc đào tạo sâu hơn cho đội ngũ về cách khai thác tối đa sức mạnh của bộ đôi Nagios và Alerta. Chúc bạn thành công!


