Giới thiệu về Regular Expression trong Python
Bạn đã từng gặp khó khăn khi tìm kiếm hoặc xử lý mẫu văn bản phức tạp chưa? Chắc hẳn nhiều lập trình viên đã từng đau đầu với việc tìm kiếm email hợp lệ trong hàng ngàn dòng dữ liệu, hoặc phải xử lý định dạng số điện thoại không đồng nhất. Đó chính là lúc Regular Expression (biểu thức chính quy) tỏ ra vô cùng hữu ích.
Biểu thức chính quy, hay còn gọi là regex, là một công cụ mạnh mẽ giúp bạn xử lý và tìm kiếm dữ liệu một cách hiệu quả trong Python. Nó như một “siêu công cụ” cho phép bạn tìm kiếm, khớp mẫu, và thay thế văn bản theo những quy tắc phức tạp chỉ bằng vài dòng lệnh.
Bài viết này sẽ hướng dẫn bạn từ cơ bản đến nâng cao cách sử dụng regex cùng module re trong Python. Chúng ta sẽ khám phá từng khía cạnh quan trọng, từ việc hiểu tổng quan về module re, nắm vững cú pháp cơ bản, cho đến việc áp dụng vào các bài toán thực tế. Hãy cùng tôi bắt đầu hành trình chinh phục công cụ mạnh mẽ này nhé!
Tổng quan về module re trong Python
Cách cài đặt và import module re
Một trong những điều tuyệt vời nhất về module re là bạn không cần phải cài đặt gì thêm cả. Module re là thư viện tích hợp sẵn trong Python, có nghĩa là bạn chỉ cần import là có thể sử dụng ngay lập tức.

Cú pháp đơn giản như sau:
import re
Chỉ cần một dòng lệnh đơn giản như vậy, bạn đã có thể truy cập vào toàn bộ sức mạnh của Regular Expression trong Python rồi. Điều này giúp bạn tiết kiệm thời gian và không phải lo lắng về việc quản lý package bổ sung.
Các hàm quan trọng của module re
Module re cung cấp nhiều hàm hữu ích, nhưng có 4 hàm chính mà bạn sẽ sử dụng thường xuyên nhất:
Hàm match() – Kiểm tra xem chuỗi có bắt đầu phù hợp với mẫu không. Hàm này chỉ tìm kiếm từ đầu chuỗi, giống như việc bạn kiểm tra xem một câu có bắt đầu bằng từ nào đó hay không.
Hàm search() – Tìm kiếm lần xuất hiện đầu tiên của mẫu trong toàn bộ chuỗi. Khác với match(), hàm này sẽ quét qua toàn bộ văn bản để tìm ra kết quả đầu tiên.
Hàm findall() – Trả về danh sách tất cả kết quả khớp với mẫu. Đây là hàm rất hữu ích khi bạn muốn thu thập toàn bộ dữ liệu phù hợp trong một văn bản.
Hàm sub() – Thay thế tất cả chuỗi con khớp với mẫu bằng chuỗi mới. Hàm này giống như chức năng “Find and Replace” trong các trình soạn thảo văn bản.

Cú pháp cơ bản của Regular Expression
Các ký tự thường và ký tự đặc biệt
Regular Expression hoạt động dựa trên hai loại ký tự chính: ký tự bình thường và ký tự đặc biệt.
Ký tự bình thường bao gồm chữ cái (a-z, A-Z), số (0-9), và các dấu câu thông thường. Chúng sẽ khớp chính xác với ký tự tương ứng trong chuỗi văn bản.
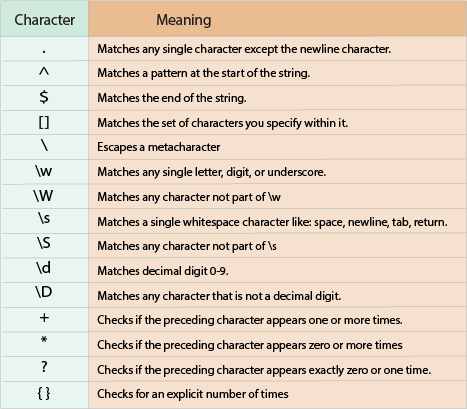
Ký tự đặc biệt là những ký tự có ý nghĩa đặc biệt trong regex: . ^ $ * + ? { } [ ] \ | ( ). Mỗi ký tự này đều có chức năng riêng biệt:
- Dấu chấm
.khớp với bất kỳ ký tự nào (trừ xuống dòng) - Dấu mũ
^đánh dấu đầu chuỗi - Dấu đô la
$đánh dấu cuối chuỗi - Dấu sao
*có nghĩa là “không hoặc nhiều lần” - Dấu cộng
+có nghĩa là “một hoặc nhiều lần” - Dấu hỏi
?có nghĩa là “không hoặc một lần”
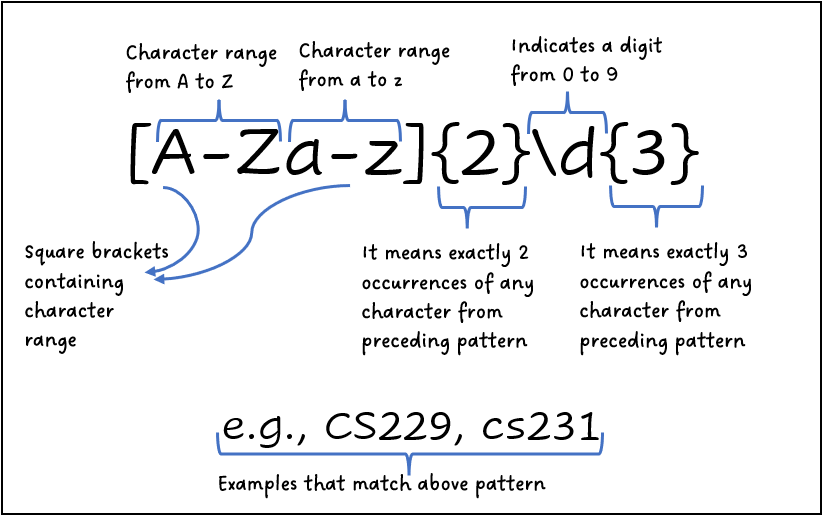
Nhóm, lặp lại và phạm vi
Nhóm mẫu sử dụng dấu ngoặc tròn () để gom các phần tử lại với nhau. Ví dụ, (abc)+ sẽ khớp với “abc”, “abcabc”, “abcabcabc”…
Lặp lại có thể được điều khiển bằng nhiều cách:
*– không hoặc nhiều lần+– một hoặc nhiều lần?– không hoặc một lần{m,n}– từ m đến n lần{m}– chính xác m lần
Phạm vi ký tự sử dụng dấu ngoặc vuông []. Ví dụ:
[a-z]khớp với bất kỳ chữ cái thường nào[0-9]khớp với bất kỳ chữ số nào[aeiou]khớp với các nguyên âm
Khai báo Raw String trong Python và tại sao nên dùng
Khi làm việc với Regular Expression trong Python, bạn sẽ thường xuyên gặp phải các ký tự đặc biệt như dấu gạch chéo ngược \. Điều này có thể gây ra sự nhầm lẫn vì Python cũng sử dụng \ như một ký tự thoát (escape character).
Raw String là giải pháp tuyệt vời cho vấn đề này. Bằng cách thêm tiền tố r trước chuỗi, bạn báo cho Python biết rằng hãy coi đây là một chuỗi thô, không cần xử lý các ký tự thoát:
# Không dùng raw string - khó đọc và dễ lỗi
pattern = "\\d{3}-\\d{3}-\\d{4}"
# Dùng raw string - rõ ràng và dễ hiểu
pattern = r"\d{3}-\d{3}-\d{4}"
Lợi ích của Raw String:
- Giúp tránh phải escape nhiều dấu
\trong regex - Làm cho mã nguồn dễ đọc và dễ hiểu hơn
- Giảm thiểu lỗi khi viết các pattern phức tạp
- Tương thích tốt với các công cụ test regex trực tuyến

Ví dụ minh họa từng hàm thông dụng
Ví dụ dùng match() và search()
Để hiểu rõ sự khác biệt giữa match() và search(), hãy cùng xem ví dụ cụ thể:
import re
text = "Email liên hệ: buimanhduc@gmail.com"
pattern = r"\w+@\w+\.\w+"
# Sử dụng match() - tìm từ đầu chuỗi
match_result = re.match(pattern, text)
print(f"Match result: {match_result}") # Kết quả: None
# Sử dụng search() - tìm trong toàn bộ chuỗi
search_result = re.search(pattern, text)
print(f"Search result: {search_result.group()}") # Kết quả: buimanhduc@gmail.com
Như bạn thấy, match() trả về None vì chuỗi không bắt đầu bằng email, trong khi search() tìm thấy email ở giữa chuỗi.
Ví dụ dùng findall() và sub()
import re
text = "Liên hệ: admin@buimanhduc.com hoặc support@buimanhduc.com"
pattern = r"\w+@\w+\.\w+"
# Sử dụng findall() - lấy tất cả email
all_emails = re.findall(pattern, text)
print(f"Tất cả email: {all_emails}")
# Kết quả: ['admin@buimanhduc.com', 'support@buimanhduc.com']
# Sử dụng sub() - thay thế email bằng [EMAIL_HIDDEN]
hidden_text = re.sub(pattern, "[EMAIL_HIDDEN]", text)
print(f"Văn bản sau khi ẩn email: {hidden_text}")
# Kết quả: Liên hệ: [EMAIL_HIDDEN] hoặc [EMAIL_HIDDEN]

Ứng dụng thực tế của regex trong Python
Regular Expression có vô số ứng dụng thực tế trong lập trình Python. Dưới đây là một số trường hợp phổ biến:
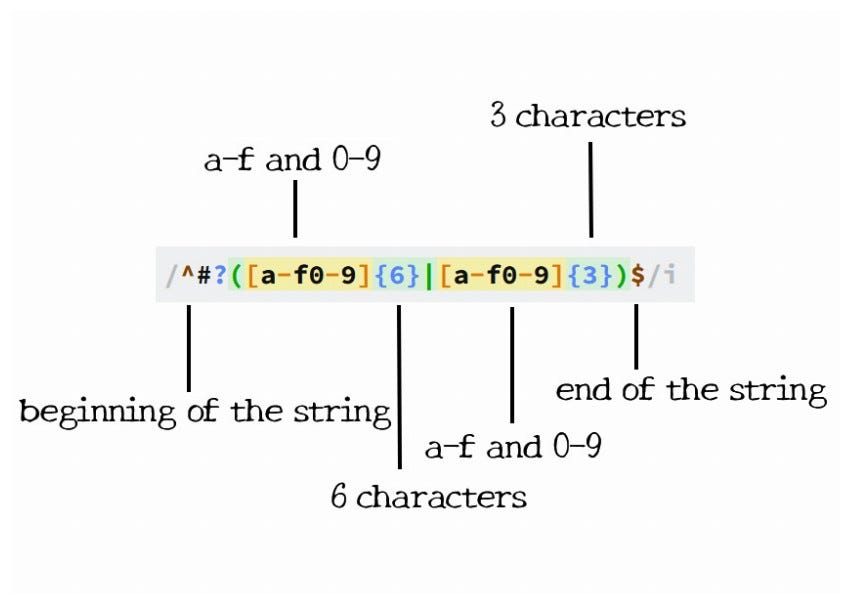
Tìm và xác thực email: Regex giúp bạn tìm kiếm và xác thực định dạng email một cách nhanh chóng:
email_pattern = r"^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$"
Xác thực đầu vào với lệnh if trong Python giúp bạn kết hợp với regex để kiểm tra email chính xác hơn.
Xử lý số điện thoại: Có thể xử lý nhiều định dạng số điện thoại khác nhau:
phone_pattern = r"(\+84|0)[0-9]{9,10}"
Chi tiết hơn về kiểu dữ liệu trong Python sẽ hỗ trợ bạn khi xử lý và chuẩn hóa số điện thoại đầu vào.
Tìm kiếm URL: Phát hiện và trích xuất link từ văn bản:
url_pattern = r"https?://[^\s]+"
Hàm trong Python rất hữu ích để bạn viết các hàm kiểm tra và xử lý URL linh hoạt.
Kiểm tra định dạng dữ liệu đầu vào: Xác thực mật khẩu mạnh, mã số thuế, số CCCD…
Xử lý và làm sạch dữ liệu: Loại bỏ ký tự đặc biệt, chuẩn hóa định dạng văn bản.
Các vấn đề thường gặp và cách khắc phục
Lỗi escape character do không dùng raw string
Một trong những lỗi phổ biến nhất khi bắt đầu học regex là việc không sử dụng raw string. Điều này dẫn đến việc phải escape nhiều dấu \, làm cho code khó đọc và dễ sai:
# Sai - không dùng raw string
pattern = "\\d{3}\\-\\d{3}\\-\\d{4}"
# Đúng - dùng raw string
pattern = r"\d{3}-\d{3}-\d{4}"
Giải pháp: Luôn sử dụng raw string khi viết regex pattern để tránh những lỗi không đáng có.
Sai lệch kết quả do không hiểu đúng hàm match() vs search()
Nhiều người mới học thường nhầm lẫn giữa hai hàm này:
match()chỉ kiểm tra từ đầu chuỗisearch()tìm kiếm ở bất kỳ vị trí nào trong chuỗi
Lời khuyên: Sử dụng search() trong hầu hết các trường hợp, chỉ dùng match() khi bạn thực sự cần kiểm tra từ đầu chuỗi.

Các best practices khi làm việc với regex trong Python
Để sử dụng Regular Expression hiệu quả và tránh các lỗi không đáng có, hãy tuân thủ những nguyên tắc sau:
- Luôn sử dụng raw string: Đây là quy tắc vàng khi viết regex pattern. Raw string giúp bạn tránh được nhiều lỗi liên quan đến escape character.
- Test regex trên công cụ trực tuyến: Trước khi áp dụng vào code, hãy test pattern trên các trang web như regex101.com hoặc regexr.com để đảm bảo hoạt động chính xác.
- Không viết regex quá phức tạp: Ưu tiên tính đọc được và khả năng bảo trì. Regex quá phức tạp sẽ khó debug và khó hiểu cho người khác.
- Sử dụng
re.compile()để tối ưu hiệu năng: Nếu bạn sử dụng cùng một pattern nhiều lần, hãy compile nó trước:
compiled_pattern = re.compile(r"\d{3}-\d{3}-\d{4}")
result = compiled_pattern.search(text)
Vòng lặp trong Python giúp bạn kết hợp regex trong các thao tác lặp xử lý dữ liệu hiệu quả hơn.
- Đọc kỹ tài liệu chính thức: Module
recủa Python có tài liệu rất chi tiết. Hãy dành thời gian đọc để hiểu sâu hơn về các tính năng nâng cao.
Sử dụng comment trong regex phức tạp: Python hỗ trợ verbose mode cho phép bạn thêm comment vào regex:
pattern = re.compile(r"""
\d{3} # 3 chữ số đầu
- # dấu gạch ngang
\d{3} # 3 chữ số tiếp theo
- # dấu gạch ngang
\d{4} # 4 chữ số cuối
""", re.VERBOSE)
Kết luận
Regular Expression thực sự là một công cụ mạnh mẽ và không thể thiếu trong việc xử lý dữ liệu văn bản trong Python. Qua bài viết này, chúng ta đã cùng nhau khám phá từ những khái niệm cơ bản nhất như cú pháp regex, cách sử dụng module re, cho đến những ứng dụng thực tế và các best practices quan trọng.
Việc nắm chắc cú pháp và các hàm cơ bản như match(), search(), findall(), và sub() sẽ giúp bạn áp dụng regex một cách hiệu quả vào các dự án thực tế. Đặc biệt, việc hiểu rõ sự khác biệt giữa các hàm này và biết cách sử dụng raw string sẽ giúp bạn tránh được nhiều lỗi phổ biến.
Regex không chỉ là một công cụ kỹ thuật mà còn là một “siêu năng lực” giúp bạn xử lý dữ liệu một cách thông minh và tiết kiệm thời gian. Từ việc xác thực input của người dùng, làm sạch dữ liệu, cho đến phân tích văn bản phức tạp – regex luôn là lựa chọn đáng tin cậy.
Hãy bắt đầu thực hành với những ví dụ đơn giản và từng bước mở rộng kiến thức của bạn. Đừng ngại thử nghiệm và tạo ra những pattern phức tạp hơn khi bạn đã tự tin với những kiến thức cơ bản. Hành trình học regex có thể khó khăn lúc đầu, nhưng một khi đã thành thạo, bạn sẽ không thể nào quên được sức mạnh tuyệt vời của nó.
Nếu bạn thấy bài viết này hữu ích, đừng quên chia sẻ để nhiều người khác cũng có thể học hỏi. Hãy tiếp tục theo dõi blog để cập nhật thêm nhiều kiến thức lập trình Python nâng cao khác từ Bùi Mạnh Đức!