
Bài viết liên quan
Kiến thức SEO Tìm Hiểu Nhóm Từ Khóa và Lợi Ích Trong SEO
Kiến thức SEO Hướng Dẫn Xóa Schema Sai và Dư Thừa để Bảo Vệ SEO

Bạn đã bao giờ tự hỏi tại sao một số trang quan trọng trên website của mình lại “mất tích” khỏi kết quả tìm kiếm của Google chưa? Một trong những thủ phạm thầm lặng và nguy hiểm nhất có thể chính là lỗi “blocked by robots.txt”. Lỗi kỹ thuật này nghe có vẻ phức tạp, nhưng nó có thể ảnh hưởng nghiêm trọng đến thứ hạng và lượng truy cập tự nhiên mà bạn vất vả xây dựng. Khi Google Search Console thông báo lỗi này, điều đó có nghĩa là bạn đang vô tình chặn Googlebot lập chỉ mục các trang web của mình, khiến chúng trở nên vô hình với người dùng tìm kiếm. Bài viết này sẽ là kim chỉ nam, hướng dẫn bạn từng bước nhận diện, kiểm tra, và sửa lỗi một cách hiệu quả để website có thể trở lại cuộc đua thứ hạng.
Để hiểu rõ về lỗi này, chúng ta cần bắt đầu từ những khái niệm cơ bản nhất. Việc nắm vững bản chất vấn đề sẽ giúp bạn xử lý triệt để và tránh lặp lại sai lầm trong tương lai. Đây là một trong những yếu tố kỹ thuật nền tảng nhưng lại có sức ảnh hưởng vô cùng lớn đến hiệu quả SEO tổng thể của website.
Hãy tưởng tượng file robots.txt là gì giống như một người gác cổng cho website của bạn. Nhiệm vụ của nó là đưa ra chỉ dẫn cho các robot của công cụ tìm kiếm (như Googlebot) rằng chúng được phép hoặc không được phép truy cập vào những khu vực nào. Vai trò này cực kỳ quan trọng trong việc kiểm soát cách các bot thu thập dữ liệu trên trang của bạn. Lỗi “blocked by robots.txt” xảy ra khi người gác cổng này nhận được một chỉ thị sai, và kết quả là cấm Googlebot truy cập vào một hoặc nhiều trang mà lẽ ra cần được lập chỉ mục. Nói cách khác, bạn đang vô tình đóng cửa với Google, ngăn họ đọc và hiểu nội dung của bạn.
Tác động của lỗi này đến SEO là trực tiếp và rất tiêu cực. Khi một trang bị chặn bởi robots.txt, Googlebot sẽ không thể thu thập dữ liệu (crawl) và do đó không thể lập chỉ mục (index) trang đó. Một trang không được lập chỉ mục đồng nghĩa với việc nó sẽ không bao giờ có cơ hội xuất hiện trên kết quả tìm kiếm của Google, dù cho nội dung của bạn có chất lượng đến đâu hay được tối ưu tốt như thế nào.
Hậu quả kéo theo là một sự sụt giảm nghiêm trọng về lưu lượng truy cập tự nhiên (organic traffic). Những trang sản phẩm, bài viết blog, hay trang dịch vụ quan trọng nếu bị chặn sẽ mất đi toàn bộ tiềm năng thu hút khách hàng từ công cụ tìm kiếm. Về lâu dài, điều này không chỉ làm giảm traffic mà còn ảnh hưởng xấu đến uy tín và thứ hạng tổng thể của toàn bộ website trong mắt Google theo thuật toán Google.
Hiểu được nguyên nhân gốc rễ gây ra lỗi sẽ giúp bạn không chỉ khắc phục vấn đề hiện tại mà còn phòng ngừa nó trong tương lai. Thường thì lỗi này không xuất phát từ những vấn đề phức tạp, mà lại đến từ những sai sót nhỏ trong quá trình cấu hình hoặc cập nhật website.

Đây là nguyên nhân phổ biến nhất. Đôi khi, do vô tình hoặc thiếu kinh nghiệm, người quản trị website đã cấu hình file robots.txt quá chặt chẽ. Một lệnh Disallow đơn giản có thể gây ra hậu quả lớn nếu nó nhắm sai mục tiêu. Ví dụ, lệnh Disallow: /images/ sẽ chặn Googlebot truy cập vào thư mục hình ảnh, điều này có thể ảnh hưởng đến Google Images và cả việc hiển thị hình ảnh trong kết quả tìm kiếm thông thường.
Một sai lầm nghiêm trọng hơn là sử dụng lệnh Disallow: / trong file robots.txt. Lệnh này có nghĩa là “chặn tất cả mọi thứ”, và nó sẽ ngăn Googlebot truy cập vào toàn bộ website của bạn. Ngoài ra, các lỗi cú pháp, dù là nhỏ nhất, cũng có thể khiến các công cụ tìm kiếm hiểu sai chỉ thị của bạn, dẫn đến việc chặn nhầm các trang quan trọng.
Website không phải là một thực thể tĩnh; nó liên tục thay đổi và phát triển. Bạn có thể thêm các trang mới, tạo ra các danh mục sản phẩm mới, hoặc thậm chí là thay đổi hoàn toàn cấu trúc URL của trang. Vấn đề phát sinh khi file robots.txt của bạn không được cập nhật song song với những thay đổi này. Một cấu trúc website mới có thể vô tình nằm trong phạm vi của một lệnh Disallow đã tồn tại từ trước.
Ví dụ, bạn có một lệnh Disallow: /promo/ để chặn các trang khuyến mãi cũ. Sau đó, bạn tạo một thư mục mới là /promotion/ cho các chiến dịch quan trọng, nhưng lại quên kiểm tra và cập nhật file robots.txt. Nếu có một quy tắc chặn nào đó ảnh hưởng đến thư mục mới, các trang này sẽ không được Google lập chỉ mục. Sự thiếu đồng bộ giữa cấu trúc website hiện tại và file robots.txt cũ là một cái bẫy mà nhiều người thường mắc phải.
Khi đã xác định được các nguyên nhân tiềm tàng, bước tiếp theo là tiến hành kiểm tra và chỉnh sửa file robots.txt. May mắn là Google cung cấp các công cụ mạnh mẽ để giúp bạn thực hiện việc này một cách chính xác và an toàn. Việc kiểm tra kỹ lưỡng trước khi áp dụng thay đổi là chìa khóa để tránh gây ra những vấn đề lớn hơn.
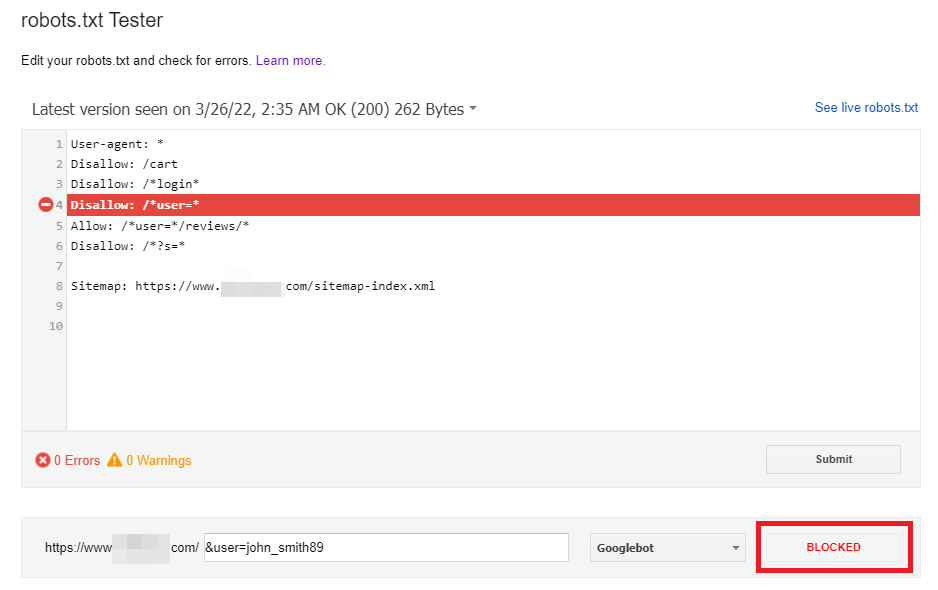
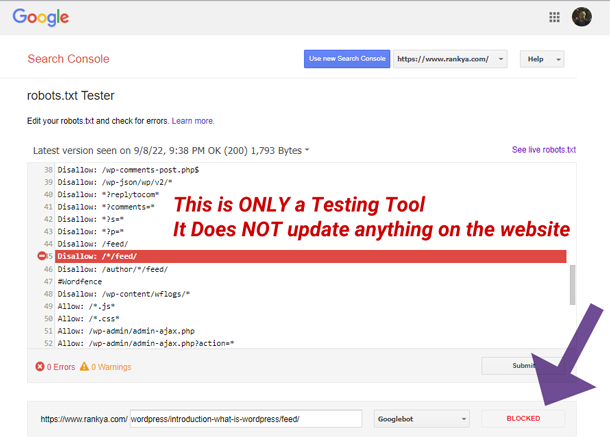
Công cụ đầu tiên và quan trọng nhất bạn nên sử dụng là trình kiểm tra robots.txt (robots.txt Tester) ngay trong Google Search Console. Công cụ này cho phép bạn xem phiên bản robots.txt mới nhất mà Google đã thu thập từ website của bạn. Quan trọng hơn, bạn có thể nhập vào một URL cụ thể để kiểm tra xem nó có đang bị chặn bởi quy tắc nào không.
Công cụ sẽ chỉ rõ dòng lệnh nào đang gây ra việc chặn, giúp bạn xác định chính xác vấn đề. Ngoài Google Search Console, cũng có nhiều công cụ seo của bên thứ ba cho phép bạn dán nội dung file robots.txt và kiểm tra các URL. Sử dụng các công cụ này giúp bạn “thử nghiệm” các thay đổi trước khi thực sự cập nhật file trên máy chủ, đảm bảo mọi thứ hoạt động như mong đợi.
Sau khi đã xác định được quy tắc gây lỗi, bạn cần chỉnh sửa file robots.txt. Một file robots.txt chuẩn thường bao gồm hai loại lệnh chính: User-agent và Disallow/Allow.
User-agent: *. Để áp dụng riêng cho Google, bạn dùng User-agent: Googlebot.Disallow: /wp-admin/ là một lệnh phổ biến để chặn bot truy cập vào khu vực quản trị của WordPress.Khi chỉnh sửa, hãy chắc chắn rằng bạn đã xác định đúng các trang cần cho phép và chặn. Cần chú ý đến cú pháp: không có khoảng trắng ở đầu dòng, và mỗi chỉ thị phải nằm trên một dòng riêng. Sự chính xác tuyệt đối là yêu cầu bắt buộc khi làm việc với file này. Để nghiên cứu sâu hơn về cách tối ưu nội dung, bạn có thể tham khảo bài Cách viết bài chuẩn SEO.
Bây giờ, hãy cùng đi vào quy trình chi tiết từng bước để sửa lỗi “blocked by robots.txt”. Quy trình này rất logic và dễ thực hiện, chỉ cần bạn làm theo một cách cẩn thận và tuần tự. Mục tiêu cuối cùng là gỡ bỏ rào cản, cho phép Googlebot truy cập và lập chỉ mục lại các trang quan trọng của bạn.
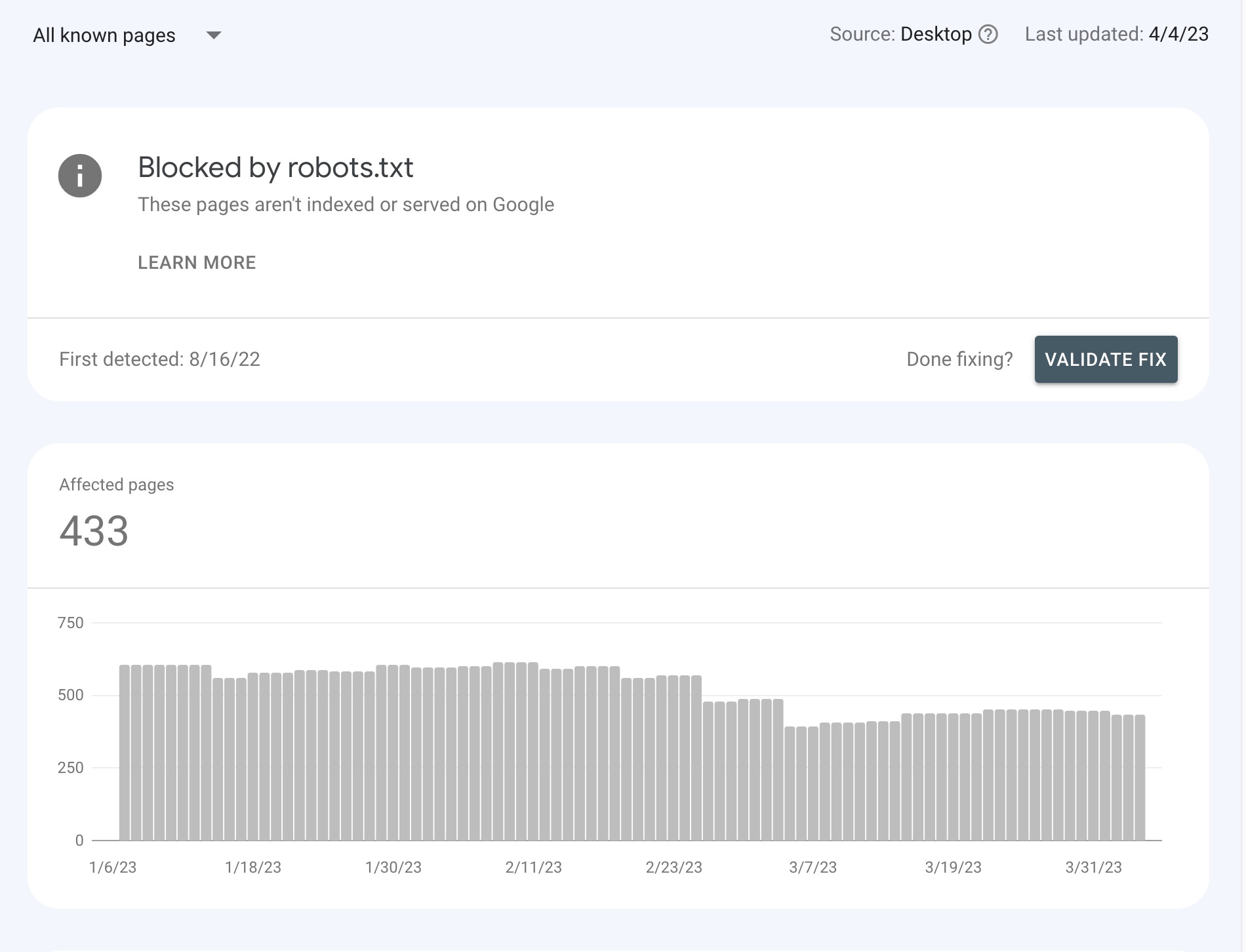
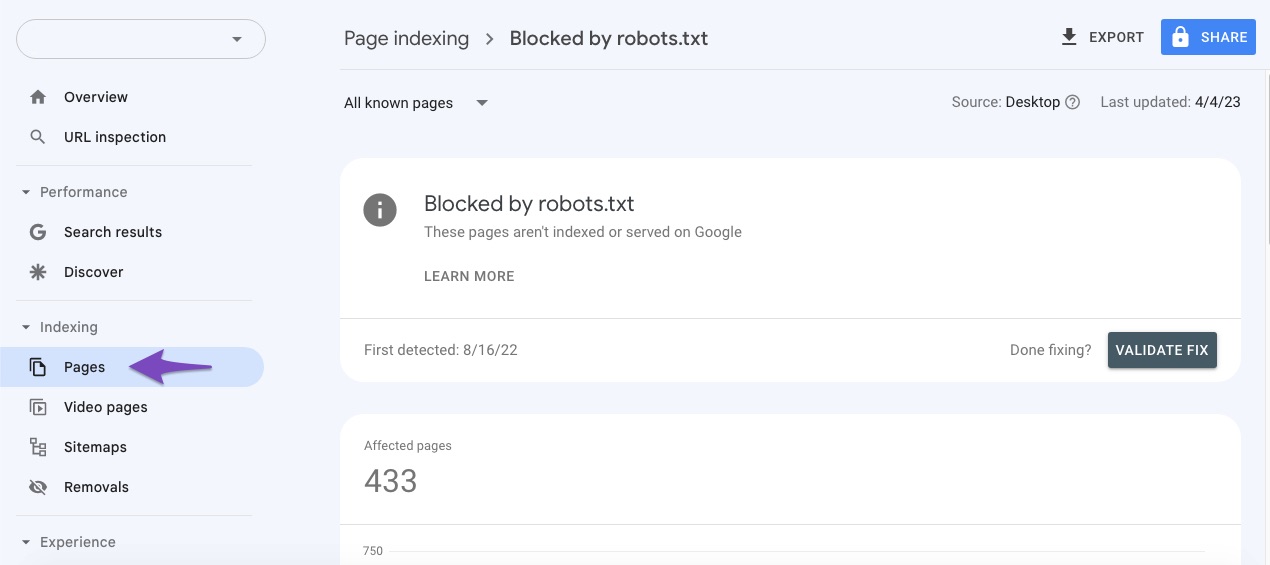
Đầu tiên, hãy đăng nhập vào tài khoản Google Search Console của bạn. Tìm đến mục “Coverage” (Phạm vi lập chỉ mục) trong thanh điều hướng bên trái. Tại đây, bạn sẽ thấy một biểu đồ tổng quan về trạng thái lập chỉ mục của website. Hãy tìm đến hộp “Excluded” (Bị loại trừ) và tìm dòng có lỗi “Blocked by robots.txt”. Nhấp vào đó, GSC sẽ liệt kê tất cả các URL trên website của bạn đang bị ảnh hưởng bởi lỗi này. Đây chính là danh sách mục tiêu bạn cần xử lý.
Với danh sách các URL bị chặn trong tay, bạn hãy mở file robots.txt của mình. Bạn có thể truy cập file này bằng cách kết nối với máy chủ qua FTP hoặc sử dụng trình quản lý file trong cPanel của hosting. So sánh các URL bị chặn với các lệnh Disallow trong file robots.txt. Hãy tìm ra quy tắc nào đang gây ra vấn đề. Ví dụ, nếu URL https://yourdomain.com/blog/important-post bị chặn, có thể do một lệnh như Disallow: /blog/. Nếu bài viết đó cần được lập chỉ mục, bạn phải xóa hoặc sửa đổi lệnh này. Hãy chỉnh sửa file một cách cẩn thận, chỉ gỡ bỏ những rào cản không cần thiết.
Sau khi đã chỉnh sửa xong, hãy lưu lại và tải file robots.txt mới lên thư mục gốc (root directory) của website, ghi đè lên file cũ. Để chắc chắn, hãy truy cập yourdomain.com/robots.txt trên trình duyệt để xem phiên bản mới đã được cập nhật hay chưa. Tiếp theo, quay lại công cụ kiểm tra robots.txt trong Google Search Console, dán nội dung file mới vào và kiểm tra lại các URL đã bị chặn trước đó. Công cụ sẽ xác nhận liệu chúng có còn bị chặn hay không.
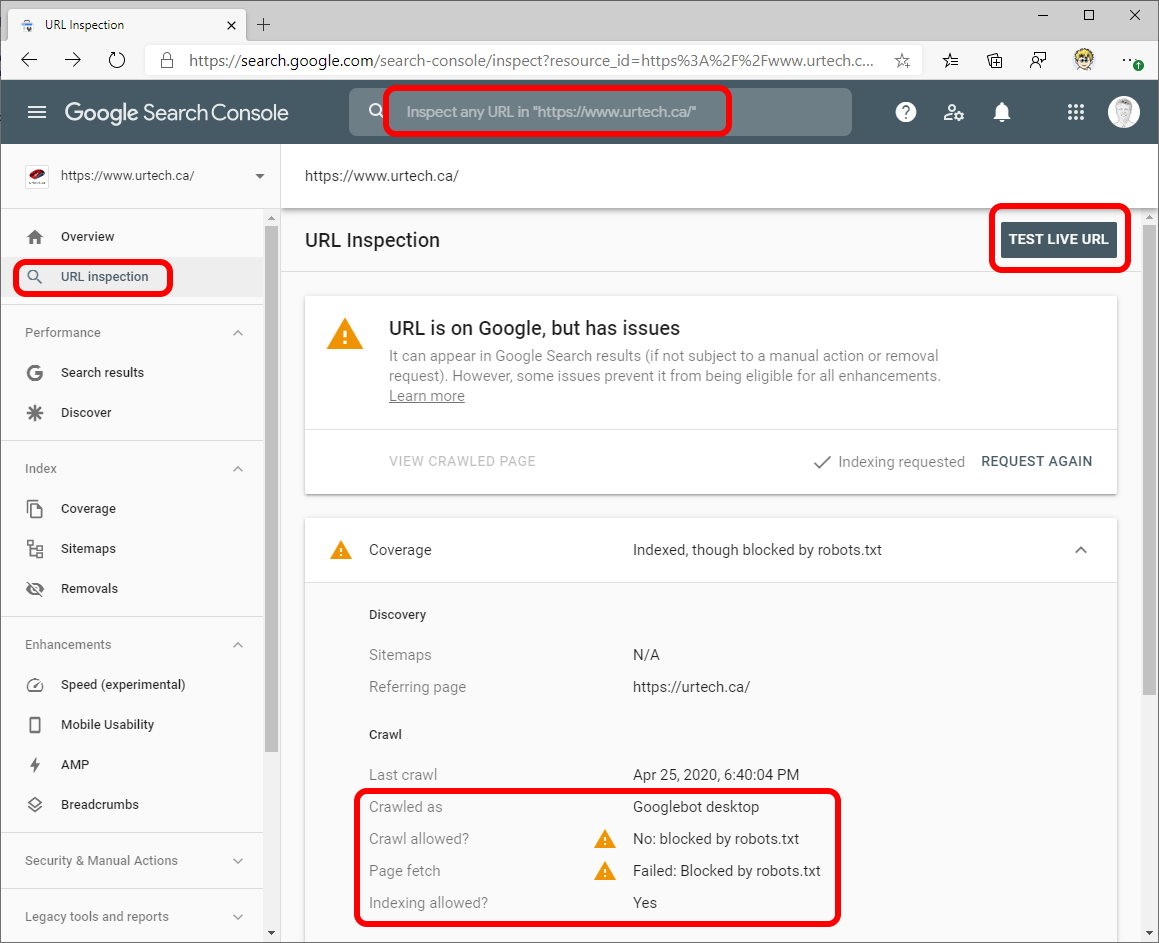
Khi bạn đã chắc chắn rằng file robots.txt không còn chặn các URL quan trọng nữa, bước cuối cùng là thông báo cho Google về sự thay đổi này. Trong Google Search Console, hãy sử dụng công cụ “URL Inspection” (Kiểm tra URL). Nhập lần lượt các URL đã sửa lỗi vào thanh tìm kiếm. Sau khi công cụ phân tích xong, nhấp vào nút “Request Indexing” (Yêu cầu lập chỉ mục). Thao tác này sẽ đưa URL vào hàng đợi ưu tiên của Google để được thu thập dữ liệu lại, giúp quá trình cập nhật diễn ra nhanh hơn.
Việc sửa lỗi và yêu cầu lập chỉ mục lại chỉ là một nửa chặng đường. Bạn cần phải theo dõi và xác nhận rằng Google đã thực sự ghi nhận thay đổi và các trang của bạn đã được lập chỉ mục thành công. Bỏ qua bước này có thể khiến công sức của bạn trở nên vô ích nếu vẫn còn vấn đề tiềm ẩn.
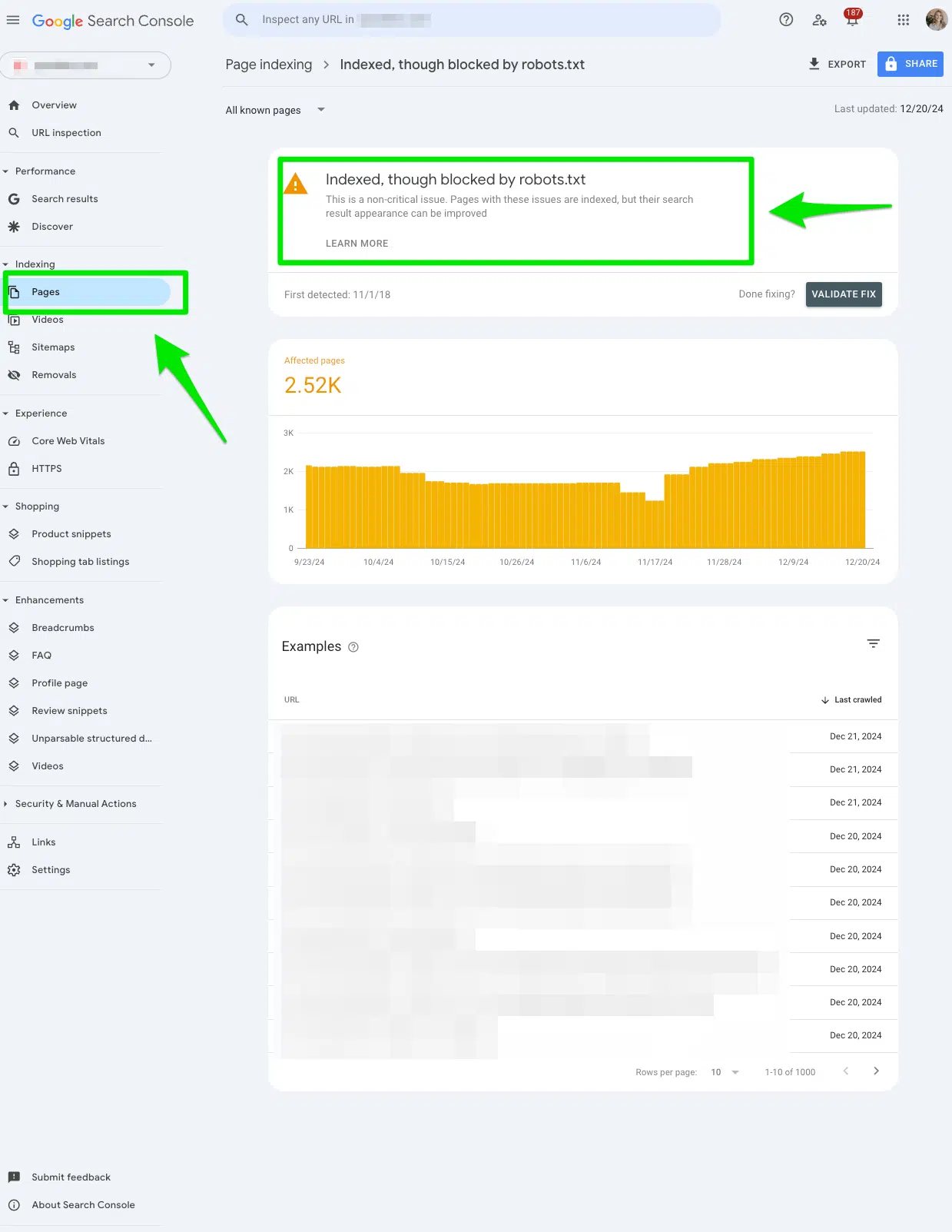
Sau khoảng một vài ngày kể từ khi bạn yêu cầu lập chỉ mục lại, hãy quay lại công cụ “URL Inspection”. Nhập lại một trong các URL đã được sửa lỗi. Lần này, hãy chú ý đến trạng thái “Page coverage”. Nếu mọi thứ diễn ra đúng kế hoạch, bạn sẽ thấy thông báo “URL is on Google” (URL đã có trên Google), và phần “Crawl allowed?” (Cho phép thu thập dữ liệu?) sẽ hiển thị là “Yes” (Có). Đây là dấu hiệu rõ ràng nhất cho thấy Googlebot đã có thể truy cập và xử lý trang của bạn một cách bình thường.

Cách kiểm tra tổng thể và hiệu quả nhất là theo dõi báo cáo “Coverage”. Trong những ngày và tuần tiếp theo, hãy thường xuyên kiểm tra lại mục lỗi “Blocked by robots.txt”. Bạn sẽ thấy số lượng URL bị lỗi giảm dần khi Googlebot tiến hành thu thập lại dữ liệu trên toàn bộ trang web của bạn. Khi con số này trở về 0 hoặc chỉ còn lại những trang bạn thực sự chủ động muốn chặn, thì khi đó bạn đã khắc phục thành công vấn đề. Đừng quên nhấp vào nút “Validate Fix” (Xác thực bản sửa lỗi) trong báo cáo lỗi để thông báo cho Google rằng bạn đã giải quyết vấn đề, điều này sẽ thúc đẩy quá trình xác nhận của họ.

File robots.txt không chỉ dùng để sửa lỗi, nó còn là một công cụ mạnh mẽ để tối ưu hóa SEO Onpage là gì kỹ thuật. Sử dụng nó một cách thông minh sẽ giúp bạn hướng dẫn các công cụ tìm kiếm sử dụng ngân sách thu thập dữ liệu (crawl budget) một cách hiệu quả hơn, tập trung vào những nội dung giá trị nhất trên website của bạn.
Đầu tiên, hãy luôn cẩn trọng để tránh chặn nhầm các trang quan trọng. Trước khi thêm bất kỳ lệnh Disallow nào, hãy tự hỏi: “Trang này có giá trị gì với người dùng tìm kiếm không?”. Nếu câu trả lời là có, đừng bao giờ chặn nó. Các trang như trang sản phẩm, bài viết blog, trang giới thiệu, và trang liên hệ luôn phải được phép truy cập.
Thứ hai, hãy tận dụng lệnh Allow. Lệnh này đặc biệt hữu ích khi bạn cần chặn một thư mục lớn nhưng lại muốn cho phép truy cập một file hoặc thư mục con cụ thể bên trong. Ví dụ, bạn có thể chặn thư mục /wp-includes/ nhưng lại cho phép truy cập một file CSS hoặc JS quan trọng bên trong nó để Google có thể hiển thị trang một cách chính xác.
Thứ ba, hãy giữ cho file robots.txt của bạn luôn được cập nhật. Lên lịch kiểm tra định kỳ (ví dụ: mỗi quý một lần) hoặc mỗi khi có sự thay đổi lớn về cấu trúc website. Điều này đảm bảo các quy tắc bạn đặt ra luôn phù hợp với tình trạng hiện tại của trang. Cuối cùng, hãy giữ file robots.txt càng ngắn gọn và rõ ràng càng tốt. Một file phức tạp với hàng trăm dòng lệnh không chỉ khó quản lý mà còn tăng nguy cơ gây ra lỗi. Chỉ bao gồm những chỉ thị thực sự cần thiết.
Trong quá trình làm việc với file robots.txt, có một vài sai lầm phổ biến mà ngay cả những người có kinh nghiệm cũng có thể mắc phải. Nhận biết và biết cách xử lý chúng sẽ giúp bạn tiết kiệm rất nhiều thời gian và tránh được những hậu quả nghiêm trọng cho SEO.
Đây là sai lầm nguy hiểm nhất. Chỉ một dòng lệnh Disallow: / sẽ ra lệnh cho tất cả các bot không được truy cập vào bất kỳ trang nào trên website của bạn. Đôi khi, lệnh này được thêm vào trong giai đoạn phát triển website để ngăn Google lập chỉ mục phiên bản chưa hoàn thiện, nhưng người phát triển lại quên xóa nó đi khi website chính thức ra mắt. Nếu bạn phát hiện traffic tự nhiên đột ngột giảm mạnh về 0, hãy kiểm tra file robots.txt ngay lập tức. Cách khắc phục rất đơn giản: xóa ngay dòng Disallow: / và lưu lại file.
Một vấn đề khác cũng thường xảy ra là bạn đã chỉnh sửa file robots.txt trên máy tính cá nhân nhưng lại quên tải nó lên máy chủ. Hoặc bạn tải lên nhưng do cơ chế cache của máy chủ hoặc CDN, phiên bản mà Googlebot thấy vẫn là file cũ. Để khắc phục, hãy chắc chắn rằng bạn đã tải file chính xác lên đúng thư mục gốc của hosting. Sau đó, hãy xóa cache của website và kiểm tra lại bằng công cụ của Google Search Console. Việc xác nhận rằng phiên bản mới nhất đã được áp dụng là vô cùng quan trọng.
Để sử dụng file robots.txt một cách an toàn và hiệu quả, việc tuân thủ các quy tắc thực hành tốt nhất là điều cần thiết. Những nguyên tắc này giúp giảm thiểu rủi ro và tối đa hóa lợi ích mà file robots.txt mang lại cho chiến lược SEO của bạn.
Trước hết, hãy luôn tạo một bản sao lưu (backup) của file robots.txt hiện tại trước khi thực hiện bất kỳ thay đổi nào. Nếu có sự cố xảy ra, bạn có thể nhanh chóng khôi phục lại phiên bản cũ đang hoạt động ổn định. Đây là một mạng lưới an toàn đơn giản nhưng cực kỳ hiệu quả.
Thứ hai, không bao giờ chỉnh sửa và cập nhật file một cách mù quáng. Luôn sử dụng công cụ kiểm tra robots.txt của Google Search Console để thử nghiệm các thay đổi của bạn trước khi áp dụng chính thức. Việc này giúp bạn đảm bảo rằng các quy tắc mới hoạt động đúng như mong đợi và không vô tình chặn các nội dung quan trọng.
Thứ ba, cần hiểu rõ rằng robots.txt chỉ là một chỉ thị, không phải là một bức tường lửa. Các bot “lịch sự” như Googlebot sẽ tuân thủ, nhưng các bot độc hại có thể bỏ qua nó. Vì vậy, không bao giờ sử dụng robots.txt để che giấu các thông tin nhạy cảm. Thay vào đó, hãy sử dụng các phương pháp bảo mật phía máy chủ như bảo vệ thư mục bằng mật khẩu.
Cuối cùng, hãy kết hợp sức mạnh của robots.txt với thẻ meta robots. Trong khi robots.txt kiểm soát việc thu thập dữ liệu (crawling), thẻ meta robots (noindex) kiểm soát việc lập chỉ mục (indexing). Sử dụng cả hai sẽ cho bạn khả năng kiểm soát sâu hơn và linh hoạt hơn đối với cách công cụ tìm kiếm tương tác với website của bạn.

Lỗi “blocked by robots.txt” có thể là một rào cản lớn, ảnh hưởng trực tiếp đến khả năng hiển thị và thứ hạng của website trên trang kết quả tìm kiếm. Tuy nhiên, đây hoàn toàn không phải là một vấn đề không thể giải quyết. Bằng cách hiểu rõ vai trò của file robots.txt, nhận diện các nguyên nhân phổ biến và áp dụng quy trình kiểm tra, sửa đổi một cách có hệ thống, bạn có thể hoàn toàn làm chủ tình hình. Việc xử lý thành công lỗi này là một bước đi quan trọng trong hành trình tối ưu hóa Quy trình SEO kỹ thuật, đảm bảo rằng những nội dung giá trị của bạn luôn được Google tìm thấy và lập chỉ mục.
Đừng để một lỗi kỹ thuật đơn giản làm gián đoạn nỗ lực và tâm huyết bạn đã đầu tư vào website. Hãy chủ động kiểm tra Google Search Console ngay hôm nay, áp dụng các bước hướng dẫn trong bài viết này để đảm bảo “người gác cổng” robots.txt đang làm đúng nhiệm vụ của mình. Sau khi đã khắc phục, hãy duy trì thói quen theo dõi báo cáo trong GSC và tiếp tục tối ưu các yếu tố Thiết kế website chuẩn SEO khác để xây dựng một nền tảng vững chắc cho sự phát triển của website trong tương lai.
Có cao nhân từng nói rằng: "Kiến thức trên thế giới này đầy rẫy trên internet. Tôi chỉ là người lao công cần mẫn đem nó tới cho người cần mà thôi !"
Kiến thức SEO Tìm Hiểu Nhóm Từ Khóa và Lợi Ích Trong SEO
Kiến thức SEO Hướng Dẫn Xóa Schema Sai và Dư Thừa để Bảo Vệ SEO