Giới thiệu
Trong kỷ nguyên bùng nổ của trí tuệ nhân tạo (AI Agent là gì), cuộc đua về tốc độ xử lý dữ liệu ngày càng trở nên gay gắt. Các mô hình học sâu (Deep learning là gì) ngày càng phức tạp, đòi hỏi khả năng tính toán khổng lồ mà những bộ xử lý truyền thống khó lòng đáp ứng. Vấn đề này đặt ra một thách thức lớn: làm thế nào để tăng tốc quá trình huấn luyện AI mà không làm chi phí tăng vọt? Đây chính là lúc Tensor Core xuất hiện như một lời giải đột phá. Được NVIDIA giới thiệu, Tensor Core là các đơn vị xử lý chuyên biệt được tích hợp thẳng vào GPU, được thiết kế để giải quyết bài toán tính toán ma trận một cách hiệu quả chưa từng có. Bài viết này sẽ cùng bạn khám phá chi tiết Tensor Core là gì, cấu trúc, vai trò và những ứng dụng thực tiễn của nó nhé.
Định nghĩa Tensor Core là gì
Tensor Core là gì trong bối cảnh GPU
Vậy chính xác thì Tensor Core là gì? Hiểu một cách đơn giản, Tensor Core là một đơn vị xử lý chuyên dụng được tích hợp bên trong các GPU hiện đại của NVIDIA. Chúng không phải là một loại GPU mới, mà là một thành phần bổ sung, hoạt động song song với các nhân CUDA Core truyền thống. Mục đích chính của chúng là thực hiện các phép toán ma trận, đặc biệt là phép nhân và cộng ma trận (matrix multiply-accumulate), với tốc độ cực nhanh. Đây chính là “trái tim” của các thuật toán học sâu và AI.
Lợi thế lớn nhất của Tensor Core so với bộ xử lý thông thường nằm ở khả năng xử lý song song và hiệu suất vượt trội trong các tác vụ chuyên biệt. Thay vì xử lý từng phép tính một cách tuần tự, một Tensor Core có thể thực hiện hàng chục, thậm chí hàng trăm phép toán trong một chu kỳ xung nhịp duy nhất. Điều này tạo ra một bước nhảy vọt về hiệu năng, giúp giảm đáng kể thời gian huấn luyện mô hình và tăng tốc các ứng dụng AI.

Lịch sử phát triển và sự tiến hóa của Tensor Core
Công nghệ Tensor Core không phải lúc nào cũng tồn tại. Nó là kết quả của một quá trình nghiên cứu và phát triển không ngừng của NVIDIA để đáp ứng nhu cầu của ngành AI. Lần đầu tiên Tensor Core được giới thiệu là vào năm 2017 với kiến trúc GPU Volta (ví dụ như trên GPU Tesla V100). Sự ra đời của thế hệ Tensor Core đầu tiên đã tạo ra một cuộc cách mạng, cung cấp hiệu suất học sâu cao hơn gấp nhiều lần so với kiến trúc Pascal trước đó.
Kể từ đó, NVIDIA đã liên tục cải tiến Tensor Core qua từng thế hệ kiến trúc mới. Kiến trúc Turing (dòng card GeForce RTX 20 series) mang Tensor Core đến với người dùng phổ thông, hỗ trợ các tính năng đột phá như DLSS (Deep Learning Super Sampling) trong game. Tiếp theo, kiến trúc Ampere (dòng GeForce RTX 30 series) và Ada Lovelace (dòng GeForce RTX 40 series) đã nâng hiệu suất và khả năng của Tensor Core lên một tầm cao mới, hỗ trợ nhiều định dạng dữ liệu hơn và tăng cường hiệu quả xử lý, khẳng định vai trò không thể thiếu của chúng trong thế giới điện toán hiện đại.
Cấu trúc và nguyên lý hoạt động của Tensor Core
Kiến trúc và thành phần cơ bản của Tensor Core
Để hiểu tại sao Tensor Core lại mạnh mẽ đến vậy, chúng ta cần xem xét kiến trúc phần cứng của nó. Về cơ bản, mỗi Tensor Core là một cụm mạch logic được thiết kế tối ưu cho một nhiệm vụ duy nhất: tính toán ma trận. Hãy tưởng tượng CUDA Core là một công nhân đa năng có thể làm nhiều việc, còn Tensor Core là một dây chuyền lắp ráp tự động, chỉ làm một việc nhưng với tốc độ và hiệu quả không tưởng.
Cấu trúc của một Tensor Core cho phép nó nhận các ma trận có kích thước nhỏ (ví dụ: 4×4) và thực hiện phép nhân và cộng chúng chỉ trong một chu kỳ đồng hồ. Nó được thiết kế để xử lý các phép toán với độ chính xác hỗn hợp (mixed-precision). Điều này có nghĩa là nó có thể nhận đầu vào là các số có độ chính xác thấp hơn (như FP16 hoặc INT8) nhưng lại thực hiện phép tính và tích lũy kết quả ở độ chính xác cao hơn (FP32). Cách tiếp cận này vừa giữ được độ chính xác cần thiết cho các mô hình AI, vừa tăng tốc độ xử lý lên đáng kể.
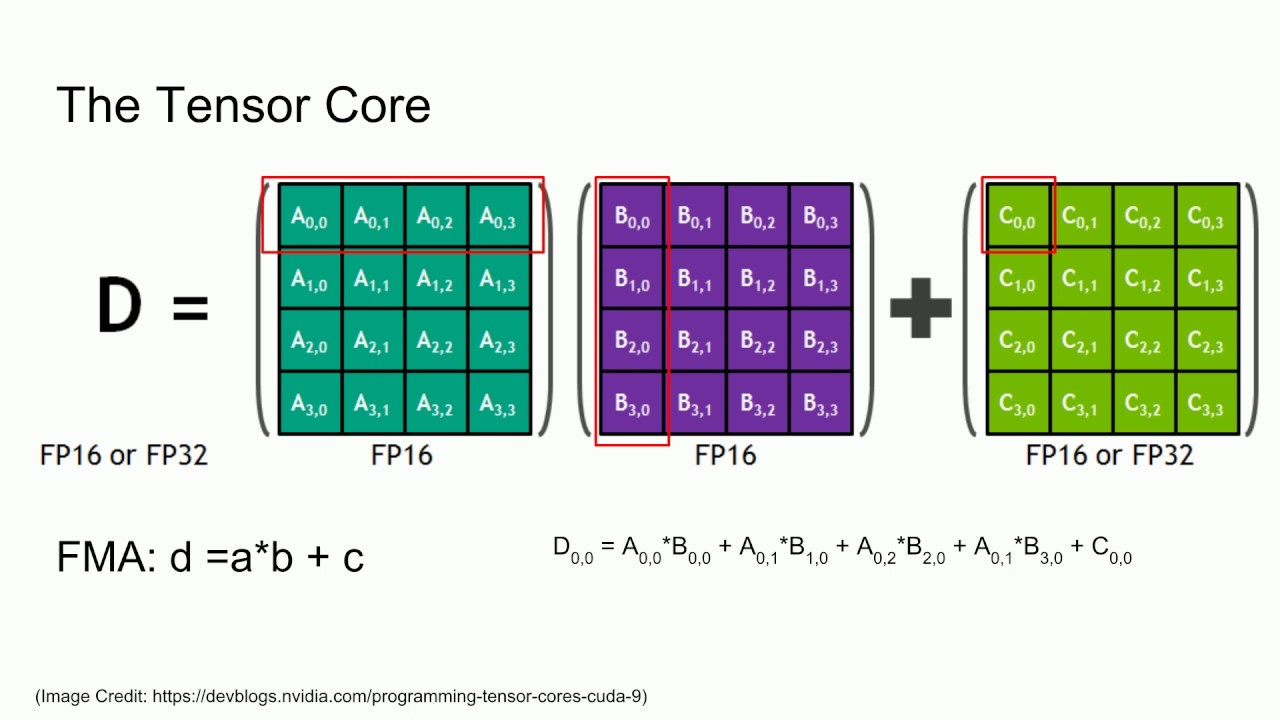
Nguyên lý hoạt động của Tensor Core trong xử lý ma trận
Nguyên lý hoạt động của Tensor Core xoay quanh việc thực thi phép toán D = A * B + C một cách cực kỳ hiệu quả. Trong đó, A và B là hai ma trận đầu vào, và C là ma trận tích lũy kết quả. Thay vì phải chia nhỏ phép nhân ma trận thành hàng nghìn phép tính riêng lẻ như các bộ xử lý thông thường, Tensor Core xử lý toàn bộ khối ma trận này cùng một lúc.
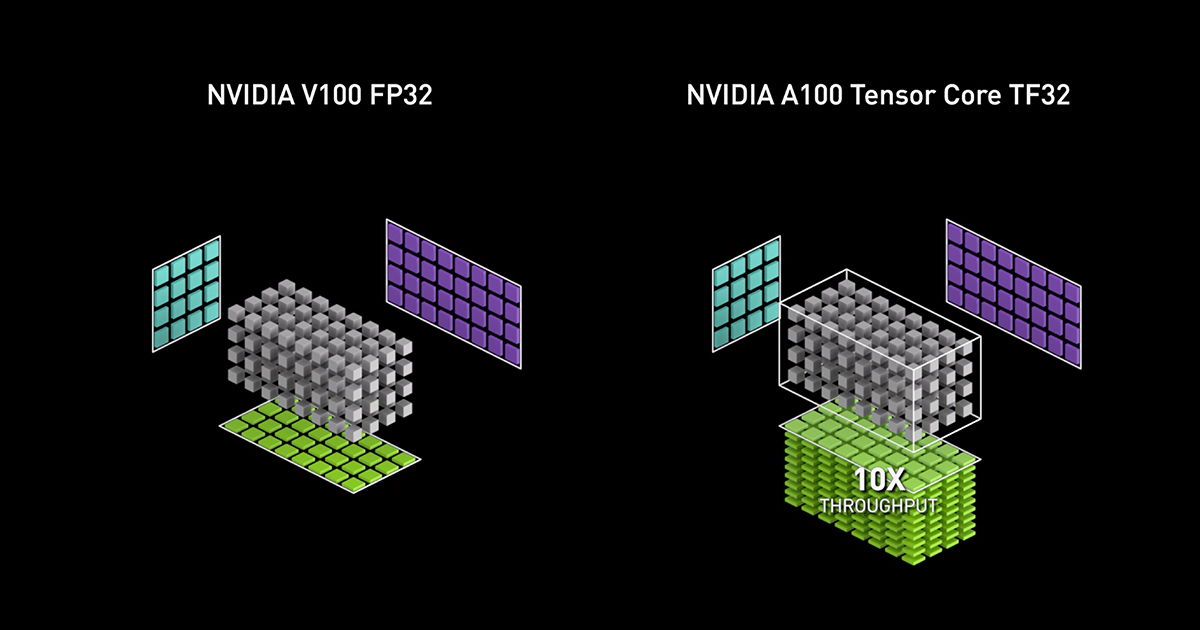
Ví dụ, một Tensor Core trong kiến trúc Volta có thể thực hiện 64 phép toán nhân-cộng dấu phẩy động (FMA) trong một chu kỳ duy nhất. Quá trình này diễn ra song song trên hàng trăm hoặc hàng nghìn Tensor Core có trong một GPU. Kết quả là, GPU có thể đạt được thông lượng tính toán hàng trăm teraflops (nghìn tỷ phép tính mỗi giây) cho các tác vụ AI. Chính khả năng xử lý ma trận theo khối và song song hóa ở quy mô lớn này là bí quyết đằng sau tốc độ đáng kinh ngạc của Tensor Core.
Vai trò của Tensor Core trong GPU và học sâu
Tăng tốc quá trình tính toán trong GPU
Vai trò chính của Tensor Core trong một GPU là trở thành “động cơ tăng áp” cho các tác vụ tính toán chuyên sâu. Khi một ứng dụng (ví dụ như một chương trình huấn luyện AI) thực hiện các phép toán ma trận, GPU sẽ thông minh chuyển những tác vụ này từ các nhân CUDA Core thông thường sang cho Tensor Core xử lý. Điều này giúp giải phóng CUDA Core để chúng tập trung vào các công việc khác, từ đó tối ưu hóa toàn bộ luồng công việc.
Kết quả là thời gian xử lý giảm đi đáng kể. Các nhà phát triển và nghiên cứu có thể huấn luyện các mô hình AI phức tạp trong vài giờ thay vì vài ngày hoặc vài tuần. Đối với người dùng thông thường, đặc biệt là game thủ, Tensor Core mang lại lợi ích qua công nghệ Generative AI là gì DLSS, giúp tăng tốc độ khung hình (FPS) mà vẫn giữ được chất lượng hình ảnh sắc nét. Về cơ bản, Tensor Core nâng cao hiệu suất tổng thể của GPU bằng cách xử lý các tác vụ nặng nhất một cách hiệu quả nhất.
Ứng dụng của Tensor Core trong thuật toán học sâu (Deep Learning)
Trong lĩnh vực học sâu, Tensor Core đóng một vai trò không thể thiếu. Hầu hết các thuật toán học sâu, từ mạng nơ-ron tích chập (CNN) cho thị giác máy tính đến mạng nơ-ron hồi quy (RNN) cho xử lý ngôn ngữ tự nhiên, đều dựa trên nền tảng là các phép tính ma trận và tensor. Quá trình huấn luyện một mô hình AI bao gồm hai giai đoạn chính: lan truyền xuôi (forward propagation) và lan truyền ngược (backward propagation), cả hai đều yêu cầu thực hiện hàng tỷ tỷ phép nhân và cộng ma trận.
Đây chính là nơi Tensor Core phát huy sức mạnh tối đa. Chúng được sinh ra để giải quyết chính xác loại bài toán này. Bằng cách tăng tốc các phép tính ma trận cốt lõi, Tensor Core trực tiếp đẩy nhanh toàn bộ quá trình huấn luyện và suy luận (inference) của mô hình. Nếu không có Tensor Core, việc phát triển các mô hình AI quy mô lớn như GPT 4 hay các hệ thống xe tự lái sẽ tốn kém hơn rất nhiều về cả thời gian và tài nguyên.
Ứng dụng của Tensor Core trong trí tuệ nhân tạo và deep learning
Tăng tốc huấn luyện và suy luận mô hình AI
Một trong những ứng dụng quan trọng nhất của Tensor Core là đẩy nhanh quá trình huấn luyện (training) và suy luận (inference) của các mô hình AI. Huấn luyện một mô hình AI hiện đại có thể đòi hỏi một lượng dữ liệu khổng lồ và hàng triệu vòng lặp tính toán. Tensor Core giúp rút ngắn quá trình này từ vài tháng xuống chỉ còn vài tuần hoặc vài ngày, cho phép các nhà khoa học dữ liệu thử nghiệm và cải tiến mô hình nhanh hơn.
Sau khi mô hình đã được huấn luyện, quá trình suy luận là lúc mô hình đưa ra dự đoán dựa trên dữ liệu mới. Ví dụ, khi bạn dùng Google Translate, mô hình AI đang thực hiện suy luận để dịch câu nói của bạn. Tensor Core giúp quá trình này diễn ra gần như tức thời, mang lại trải nghiệm mượt mà cho người dùng cuối. Từ các trợ lý ảo, hệ thống nhận dạng khuôn mặt cho đến các công cụ phân tích dữ liệu phức tạp, tốc độ suy luận nhanh là yếu tố then chốt, và Tensor Core chính là công nghệ đằng sau nó.

Ví dụ thực tiễn trong công nghiệp và nghiên cứu
Tensor Core đã và đang được ứng dụng rộng rãi trong nhiều ngành công nghiệp và lĩnh vực nghiên cứu. Trong y tế, chúng được sử dụng để phân tích hình ảnh y khoa (như X-quang, MRI) để phát hiện sớm các dấu hiệu bệnh tật với độ chính xác cao. Trong ngành công nghiệp ô tô, Tensor Core là trái tim của các hệ thống lái xe tự động, xử lý dữ liệu từ camera và cảm biến để đưa ra quyết định trong thời gian thực.
Đối với người dùng phổ thông, ứng dụng dễ thấy nhất là trong lĩnh vực gaming. Công nghệ NVIDIA Công cụ AI DLSS (Deep Learning Super Sampling) sử dụng Tensor Core để tái tạo hình ảnh từ độ phân giải thấp lên độ phân giải cao hơn bằng AI, giúp tăng tốc độ khung hình một cách ngoạn mục mà không làm giảm chất lượng đồ họa. Trong nghiên cứu khoa học, chúng giúp các nhà khoa học mô phỏng các hiện tượng phức tạp, từ biến đổi khí hậu đến tương tác phân tử, mở ra những chân trời mới cho khám phá.
Lợi ích của việc sử dụng Tensor Core trong tăng tốc xử lý dữ liệu
Nâng cao hiệu suất và tiết kiệm thời gian
Lợi ích rõ ràng và trực tiếp nhất của việc sử dụng Tensor Core là sự gia tăng đột phá về hiệu suất. So với việc chỉ sử dụng các nhân CUDA Core truyền thống cho các tác vụ AI, Tensor Core có thể mang lại hiệu suất cao hơn từ 5 đến 16 lần, tùy thuộc vào kiến trúc GPU và ứng dụng cụ thể. Mức tăng tốc này không chỉ là một con số, nó đại diện cho việc tiết kiệm hàng trăm, thậm chí hàng nghìn giờ làm việc của máy tính.
Đối với các doanh nghiệp, điều này có nghĩa là các dự án AI có thể được triển khai nhanh hơn, sản phẩm sớm được đưa ra thị trường và có khả năng cạnh tranh tốt hơn. Đối với các nhà nghiên cứu, thời gian chờ đợi kết quả giảm xuống cho phép họ thực hiện nhiều thí nghiệm hơn, thúc đẩy sự đổi mới và sáng tạo. Tiết kiệm thời gian chính là một trong những yếu tố quan trọng nhất giúp các tổ chức duy trì lợi thế trong thế giới số phát triển không ngừng.

Tiết kiệm năng lượng và tối ưu chi phí
Bên cạnh hiệu suất, Tensor Core còn mang lại lợi ích đáng kể về mặt năng lượng. Bằng cách hoàn thành công việc nhanh hơn rất nhiều, GPU tiêu thụ ít năng lượng hơn cho cùng một khối lượng công việc. Hiệu quả năng lượng này (tính bằng số phép tính trên mỗi Watt điện) của Tensor Core vượt trội hơn hẳn so với các phương pháp xử lý truyền thống. Điều này đặc biệt quan trọng đối với các trung tâm dữ liệu lớn, nơi chi phí điện năng là một khoản chi khổng lồ.
Việc tiết kiệm năng lượng trực tiếp dẫn đến tối ưu chi phí vận hành. Hơn nữa, vì một GPU trang bị Tensor Core có thể thay thế cho nhiều máy chủ chỉ sử dụng CPU cho các tác vụ AI, doanh nghiệp có thể cắt giảm chi phí đầu tư phần cứng, không gian lắp đặt và hệ thống làm mát. Tóm lại, Tensor Core không chỉ giúp bạn làm việc nhanh hơn mà còn giúp bạn làm việc một cách thông minh và tiết kiệm hơn.
So sánh Tensor Core với các đơn vị xử lý truyền thống trên GPU
Điểm khác biệt về hiệu năng và thiết kế
Để hiểu rõ hơn về Tensor Core, chúng ta hãy so sánh nó với CUDA Core, đơn vị xử lý cơ bản và phổ biến nhất trên GPU của NVIDIA. Sự khác biệt cốt lõi nằm ở triết lý thiết kế: CUDA Core là bộ xử lý đa năng, còn Tensor Core là chuyên gia.
CUDA Core được thiết kế để xử lý một loạt các tác vụ tính toán song song. Chúng rất linh hoạt và có thể chạy gần như mọi loại thuật toán. Tuy nhiên, chúng xử lý các phép tính ở mức độ cơ bản (ví dụ: một phép nhân hoặc một phép cộng tại một thời điểm). Ngược lại, Tensor Core được thiết kế chỉ cho một mục đích: xử lý các phép toán nhân-cộng ma trận (Matrix Multiply-Accumulate) theo khối. Chúng kém linh hoạt hơn CUDA Core nhưng lại thực hiện nhiệm vụ chuyên biệt của mình với hiệu suất cao hơn gấp nhiều lần. Đây là sự đánh đổi giữa tính đa năng và hiệu suất chuyên dụng.

Ưu nhược điểm khi sử dụng Tensor Core so với kỹ thuật truyền thống
Việc sử dụng Tensor Core mang lại nhiều ưu điểm vượt trội nhưng cũng có một số nhược điểm cần lưu ý.
Ưu điểm:
- Tốc độ cực cao: Đây là lợi thế lớn nhất, giúp tăng tốc đáng kể các tác vụ học sâu và AI.
- Hiệu quả năng lượng: Xử lý nhiều phép tính hơn trên mỗi Watt điện, giúp tiết kiệm chi phí vận hành.
- Thúc đẩy công nghệ mới: Là nền tảng cho các tính năng đột phá như DLSS trong game, giúp cải thiện trải nghiệm người dùng.
Nhược điểm:
- Tính chuyên dụng cao: Tensor Core chỉ phát huy tác dụng đối với các phép toán ma trận. Với các tác vụ khác, chúng không mang lại lợi ích.
- Yêu cầu tương thích phần mềm: Để khai thác được sức mạnh của Tensor Core, phần mềm và các thư viện lập trình (như Machine learning là gì, TensorFlow, PyTorch, cuDNN) phải được tối ưu hóa để “gọi” chúng. Nếu không, GPU sẽ chỉ sử dụng các nhân CUDA Core thông thường.
- Độ chính xác: Mặc dù sử dụng kỹ thuật độ chính xác hỗn hợp để giảm thiểu sai số, một số ứng dụng khoa học cực kỳ nhạy cảm có thể yêu cầu tính toán hoàn toàn ở độ chính xác cao (FP64), vốn không phải là thế mạnh của Tensor Core.

Các vấn đề thường gặp và cách khắc phục
Lỗi tương thích phần mềm với Tensor Core
Một trong những vấn đề phổ biến nhất mà người dùng gặp phải là không thấy được sự tăng tốc như kỳ vọng. Nguyên nhân thường không nằm ở phần cứng mà là do phần mềm chưa được tối ưu để tận dụng Tensor Core. Ví dụ, bạn đang chạy một đoạn mã AI trên GPU RTX 4090 nhưng lại sử dụng phiên bản cũ của TensorFlow hoặc PyTorch không hỗ trợ các tính năng của kiến trúc Ada Lovelace.
Cách khắc phục:
- Cập nhật driver GPU: Luôn đảm bảo bạn đang sử dụng phiên bản driver Game Ready hoặc Studio mới nhất từ NVIDIA.
- Sử dụng phiên bản thư viện mới nhất: Cài đặt và sử dụng các phiên bản mới nhất của các framework học sâu như TensorFlow, PyTorch và các thư viện nền tảng như CUDA Toolkit, cuDNN.
- Kiểm tra tài liệu: Đọc kỹ tài liệu hướng dẫn của phần mềm bạn đang sử dụng để xem nó có hỗ trợ và yêu cầu cấu hình đặc biệt nào để kích hoạt Tensor Core hay không.
Vấn đề tối ưu hiệu suất khi triển khai Tensor Core
Ngay cả khi phần mềm đã tương thích, việc tối ưu để đạt được hiệu suất tối đa từ Tensor Core cũng là một thách thức. Một vấn đề thường gặp là kích thước của ma trận hoặc tensor không phù hợp, dẫn đến việc Tensor Core không được sử dụng hiệu quả. Ví dụ, Tensor Core hoạt động tốt nhất khi kích thước đầu vào (như số lượng mẫu trong một batch) là bội số của 8.
Cách khắc phục:
- Sử dụng Automatic Mixed Precision (AMP): Hầu hết các framework hiện đại đều có tính năng này. AMP sẽ tự động chuyển đổi các phép toán sang định dạng FP16 để chạy trên Tensor Core và giữ các phép toán nhạy cảm ở FP32, giúp tối ưu hiệu suất mà không cần can thiệp thủ công nhiều.
- Điều chỉnh kích thước Batch Size: Khi huấn luyện mô hình, hãy thử nghiệm với các kích thước batch size là bội số của 8 (ví dụ: 32, 64, 128) để xem hiệu suất có cải thiện không.
- Sử dụng NVIDIA Profiler: Sử dụng các công cụ như NVIDIA Nsight Systems để phân tích hiệu suất ứng dụng của bạn. Nó sẽ cho bạn biết chính xác phần nào của mã đang sử dụng Tensor Core và phần nào chưa, từ đó giúp bạn tìm ra điểm nghẽn để tối ưu.

Các best practices khi sử dụng Tensor Core
Để khai thác tối đa sức mạnh của Tensor Core, việc tuân thủ các phương pháp hay nhất (best practices) là vô cùng quan trọng. Dưới đây là những lời khuyên hữu ích dành cho các nhà phát triển và người dùng.
Những điều nên làm:
- Ưu tiên sử dụng Mixed Precision: Luôn bật tính năng Automatic Mixed Precision (AMP) trong các framework học sâu. Đây là cách dễ nhất và hiệu quả nhất để có được sự tăng tốc từ Tensor Core mà không phải hy sinh nhiều về độ chính xác.
- Giữ cho môi trường phát triển luôn cập nhật: Thường xuyên cập nhật NVIDIA Driver, CUDA Toolkit, và các thư viện AI/ML. Các phiên bản mới thường đi kèm với những cải tiến hiệu suất và hỗ trợ tốt hơn cho các thế hệ Tensor Core mới.
- Tận dụng các thư viện của NVIDIA: Sử dụng các thư viện được NVIDIA tối ưu hóa cao như cuBLAS (cho đại số tuyến tính cơ bản) và cuDNN (cho mạng nơ-ron sâu). Chúng được thiết kế để tự động tận dụng Tensor Core khi có thể.
- Tối ưu hóa kích thước Tensor: Như đã đề cập, hãy cố gắng đảm bảo kích thước các chiều của tensor (đặc biệt là batch size và số kênh) là bội số của 8 để tối ưu hóa việc nạp dữ liệu vào Tensor Core.
Những điều nên tránh:
- Tránh chuyển đổi kiểu dữ liệu không cần thiết: Việc liên tục chuyển đổi dữ liệu giữa FP32 và FP16 có thể tạo ra chi phí hiệu năng. Hãy để các công cụ như AMP quản lý việc này một cách tự động.
- Đừng cho rằng mọi thứ sẽ tự động nhanh hơn: Hãy nhớ rằng Tensor Core chỉ tăng tốc các phép toán cụ thể. Đừng mong đợi toàn bộ ứng dụng của bạn sẽ nhanh hơn gấp 10 lần nếu nó có nhiều tác vụ không liên quan đến tính toán ma trận.
- Không bỏ qua việc đo lường hiệu năng: Đừng chỉ “cảm thấy” nó nhanh hơn. Hãy sử dụng các công cụ profiler chuyên dụng để đo lường và xác nhận rằng bạn thực sự đang nhận được lợi ích từ Tensor Core và để tìm ra các cơ hội tối ưu hóa thêm.
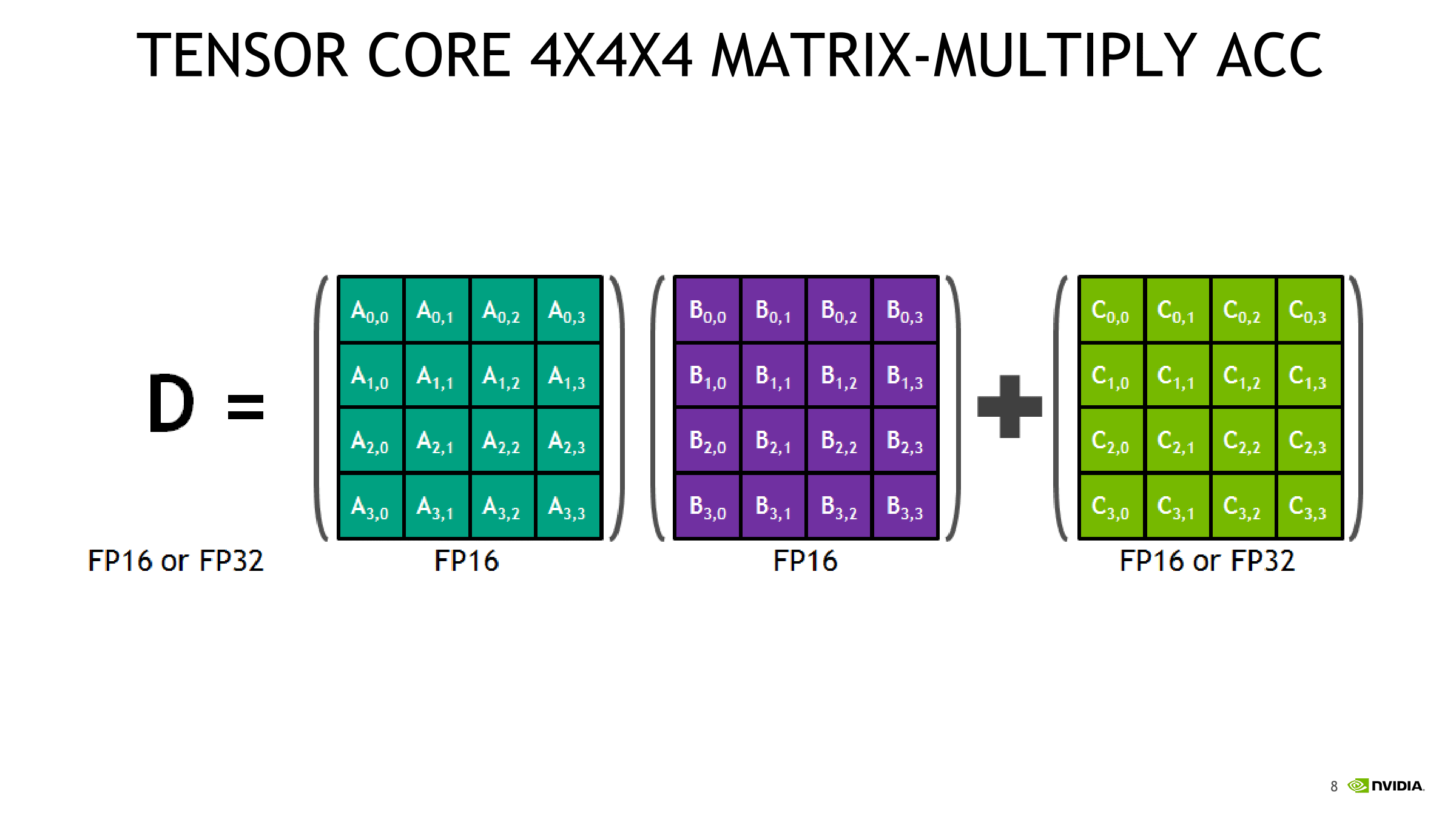
Kết luận
Qua bài viết này, chúng ta đã cùng nhau khám phá một cách chi tiết về Tensor Core – những đơn vị xử lý chuyên biệt đã tạo nên cuộc cách mạng trong lĩnh vực trí tuệ nhân tạo và điện toán hiệu năng cao. Từ định nghĩa cơ bản, cấu trúc phần cứng thông minh, cho đến vai trò không thể thiếu trong việc tăng tốc GPU và các mô hình học sâu, Tensor Core đã chứng tỏ mình là một công nghệ nền tảng của kỷ nguyên AI.
Lợi ích mà chúng mang lại không chỉ dừng lại ở hiệu suất tính toán vượt trội và tiết kiệm thời gian, mà còn mở ra những khả năng mới trong nghiên cứu khoa học, y tế, giải trí và nhiều ngành công nghiệp khác. Dù có những yêu cầu nhất định về phần mềm và tối ưu hóa, sức mạnh mà Tensor Core cung cấp là không thể phủ nhận. Hy vọng rằng những kiến thức này sẽ giúp bạn hiểu rõ hơn về công nghệ đang định hình tương lai. Nếu bạn đang làm việc trong lĩnh vực AI và Deep Learning là gì, đừng ngần ngại tìm hiểu sâu hơn và bắt đầu ứng dụng sức mạnh của Tensor Core vào các dự án của mình để tạo ra những đột phá mới.

