Trong thời đại số, chúng ta đang phải đối mặt với một đại dương thông tin theo đúng nghĩa đen. Mỗi ngày, hàng triệu bài viết, blog, và tài liệu được tạo ra. Vậy làm thế nào để các công cụ tìm kiếm như Google có thể hiểu và xếp hạng nội dung nào là phù hợp nhất với truy vấn của bạn? Hay làm sao để một hệ thống có thể tự động phân loại hàng ngàn email vào đúng thư mục? Câu trả lời nằm ở một kỹ thuật quan trọng trong xử lý ngôn ngữ tự nhiên (NLP) gọi là TF-IDF. Đây là công cụ đắc lực giúp máy tính “đọc” và đánh giá tầm quan trọng của từng từ trong một văn bản. Bài viết này sẽ cùng bạn đi từ khái niệm cơ bản đến ứng dụng thực tế của TF-IDF một cách dễ hiểu nhất.
Giới thiệu về TF-IDF
Chúng ta đang sống trong một kỷ nguyên bùng nổ dữ liệu văn bản. Từ các bài đăng trên mạng xã hội, tin tức trực tuyến, tài liệu nghiên cứu cho đến email công việc, lượng thông tin dạng chữ viết đang tăng lên theo cấp số nhân. Theo thống kê, mỗi ngày có hàng triệu blog post được xuất bản và hàng tỷ email được gửi đi.
Trong biển dữ liệu khổng lồ đó, việc tìm ra thông tin thực sự giá trị và liên quan trở thành một thách thức lớn. Làm thế nào chúng ta có thể xác định được đâu là những từ khóa cốt lõi, đại diện cho nội dung chính của một tài liệu dài hàng ngàn chữ? Đây không chỉ là vấn đề của người đọc mà còn là bài toán hóc búa đối với các hệ thống máy tính.
Để giải quyết vấn đề này, các nhà khoa học máy tính đã phát triển một phương pháp hiệu quả mang tên TF-IDF. Đây là một kỹ thuật thống kê giúp lượng hóa tầm quan trọng của một từ trong một tài liệu, so với một tập hợp nhiều tài liệu khác. Nó giúp máy tính lọc bỏ những từ phổ thông, ít mang ý nghĩa và tập trung vào những thuật ngữ thực sự đắt giá.
Trong bài viết này, Bùi Mạnh Đức sẽ cùng bạn khám phá chi tiết về TF-IDF. Chúng ta sẽ bắt đầu từ định nghĩa, tìm hiểu công thức tính toán, xem xét các ứng dụng thực tế trong SEO và học máy, đồng thời phân tích cả ưu điểm lẫn hạn chế của phương pháp này.

TF-IDF là gì? Định nghĩa và ý nghĩa trong xử lý ngôn ngữ tự nhiên
Vậy chính xác thì TF-IDF là gì và nó hoạt động như thế nào? Để hiểu rõ, chúng ta cần mổ xẻ cái tên của nó, vốn là viết tắt của hai khái niệm riêng biệt nhưng lại liên kết chặt chẽ với nhau.
Khái niệm TF-IDF
TF-IDF là viết tắt của “Term Frequency – Inverse Document Frequency”. Đây là một trọng số thống kê được sử dụng để đánh giá mức độ quan trọng của một từ trong một văn bản, đặt trong bối cảnh của một tập hợp lớn các văn bản (còn gọi là corpus).
Nói một cách đơn giản, TF-IDF giúp bạn trả lời câu hỏi: “Data science là gì” và “Từ này có thực sự đặc biệt và đại diện cho nội dung của tài liệu này không?”.
Để làm được điều đó, TF-IDF kết hợp hai yếu tố:
- TF (Term Frequency – Tần suất từ): Đo lường mức độ thường xuyên một từ xuất hiện trong một văn bản cụ thể. Một từ xuất hiện càng nhiều, chỉ số TF của nó càng cao.
- IDF (Inverse Document Frequency – Tần suất nghịch của văn bản): Đo lường mức độ “hiếm” hay “đặc biệt” của một từ trong toàn bộ tập hợp văn bản. Những từ xuất hiện trong nhiều văn bản (như “là”, “của”, “và”) sẽ có chỉ số IDF thấp, trong khi những từ chỉ xuất hiện trong một vài văn bản chuyên ngành sẽ có chỉ số IDF cao.
Mục đích cuối cùng của TF-IDF là tìm ra sự cân bằng hoàn hảo. Một từ có trọng số TF-IDF cao khi nó xuất hiện thường xuyên trong một văn bản (TF cao) nhưng lại hiếm gặp ở các văn bản khác (IDF cao).
Ý nghĩa của TF-IDF đối với xử lý ngôn ngữ tự nhiên
Trong lĩnh vực xử lý ngôn ngữ tự nhiên (NLP), TF-IDF không chỉ là một công thức toán học khô khan. Nó mang ý nghĩa thực tiễn to lớn, giúp máy tính “hiểu” được nội dung văn bản ở một mức độ sâu hơn.
Ý nghĩa quan trọng nhất của TF-IDF là khả năng đánh giá tầm quan trọng của từ khóa. Thay vì chỉ đếm số lần xuất hiện một cách máy móc, TF-IDF giúp lọc ra những thuật ngữ thực sự mang thông tin cốt lõi. Những từ như “Trái Đất”, “hành tinh”, “không gian” sẽ có điểm TF-IDF cao trong một bài viết về thiên văn học, trong khi những từ phổ biến như “bài viết”, “nghiên cứu”, “cho thấy” sẽ có điểm thấp hơn.
Nhờ khả năng này, TF-IDF trở thành nền tảng cho việc lọc và sắp xếp thông tin hiệu quả. Các công cụ tìm kiếm sử dụng nó để xếp hạng các trang web phù hợp nhất với truy vấn của người dùng. Các hệ thống gợi ý nội dung dùng nó để đề xuất những bài viết liên quan mà bạn có thể quan tâm. Rõ ràng, TF-IDF đóng vai trò như một bộ lọc thông minh, giúp chúng ta không bị lạc lối trong thế giới thông tin rộng lớn.

Công thức và cách tính TF-IDF chi tiết
Hiểu được khái niệm rồi, giờ chúng ta sẽ đi sâu vào phần toán học đằng sau nó. Đừng lo lắng, công thức của TF-IDF khá trực quan và dễ hiểu qua các ví dụ cụ thể.
Cách tính TF (Tần suất từ)
TF (Term Frequency) là phần đơn giản nhất, dùng để đo tần suất xuất hiện của một từ trong một văn bản. Công thức cơ bản nhất của TF là:
TF(t, d) = (Số lần từ t xuất hiện trong văn bản d) / (Tổng số từ trong văn bản d)
Trong đó:
t là từ (term) bạn đang xét.d là văn bản (document) cụ thể.
Ví dụ minh họa:
Giả sử chúng ta có một câu (xem như một văn bản ngắn):
d1 = "Bùi Mạnh Đức chia sẻ kiến thức về website và kiến thức về hosting."
Tổng số từ trong câu này là 11 từ.
Bây giờ, hãy tính TF cho các từ “kiến thức”, “website” và “và”:
- Từ “kiến thức” xuất hiện 2 lần.
=> TF(“kiến thức”, d1) = 2 / 11 ≈ 0.18
- Từ “website” xuất hiện 1 lần.
=> TF(“website”, d1) = 1 / 11 ≈ 0.09
- Từ “và” xuất hiện 1 lần.
=> TF(“và”, d1) = 1 / 11 ≈ 0.09
Chỉ số TF cho thấy “kiến thức” là từ quan trọng hơn trong câu này vì nó xuất hiện thường xuyên hơn. Tuy nhiên, nếu chỉ dựa vào TF, những từ phổ biến như “và”, “là”, “của” cũng có thể có điểm số cao, đó là lúc chúng ta cần đến IDF.
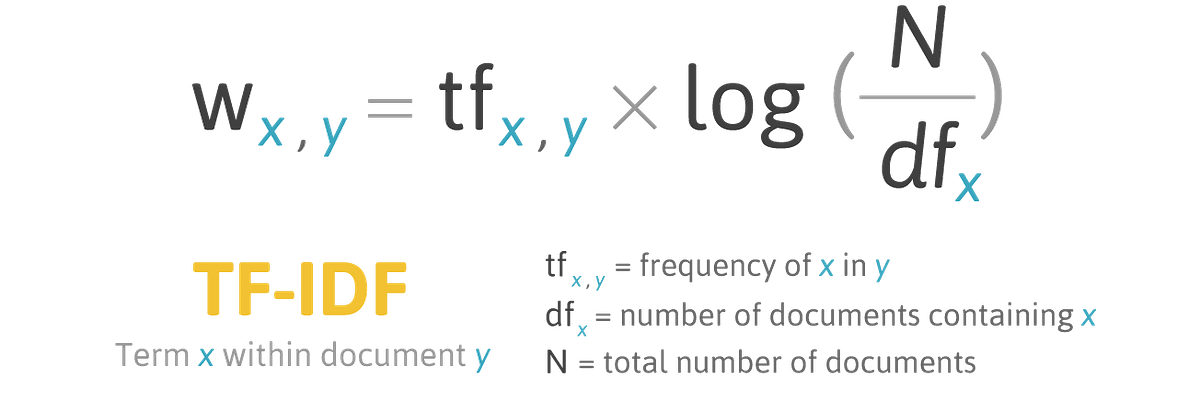
Cách tính IDF và công thức TF-IDF
IDF (Inverse Document Frequency) được sinh ra để giải quyết điểm yếu của TF. Nó giúp giảm trọng số của những từ xuất hiện ở khắp mọi nơi và tăng trọng số cho những từ hiếm, mang tính chuyên môn cao.
Công thức tính IDF là:
IDF(t, D) = log( (Tổng số văn bản trong tập dữ liệu D) / (Số văn bản chứa từ t) )
Trong đó:
t là từ bạn đang xét.D là toàn bộ tập hợp các văn bản.log là hàm logarit, thường là logarit tự nhiên (ln). Việc lấy logarit giúp làm mượt giá trị và tránh trường hợp chênh lệch quá lớn.
Nguyên lý của IDF rất thông minh:
- Nếu một từ xuất hiện trong tất cả các văn bản, tỉ số trong hàm log sẽ là 1, và
log(1) = 0. Từ đó bị coi là không quan trọng.
- Nếu một từ xuất hiện trong rất ít văn bản, tỉ số sẽ lớn, và giá trị log cũng sẽ cao, cho thấy từ đó rất đặc biệt.
Cuối cùng, chúng ta kết hợp TF và IDF để có được công thức hoàn chỉnh:
TF-IDF(t, d, D) = TF(t, d) * IDF(t, D)
Ví dụ thực tế:
Hãy xét 2 văn bản sau trong tập dữ liệu của chúng ta:
d1 = "Bùi Mạnh Đức chia sẻ kiến thức về website và kiến thức về hosting." (11 từ)d2 = "Kiến thức SEO rất quan trọng cho website." (7 từ)
Tổng số văn bản (N) là 2.
Hãy cùng tính TF-IDF cho từ “website” và “kiến thức” trong văn bản d1:
- Từ “website”:
- TF(“website”, d1) = 1/11 ≈ 0.09
- Từ “website” xuất hiện trong cả 2 văn bản.
- IDF(“website”, D) = log(2/2) = log(1) = 0
- TF-IDF(“website”, d1) = 0.09 * 0 = 0
- Lưu ý: Để tránh kết quả bằng 0, người ta thường dùng công thức IDF cải tiến như Data mining là gì hoặc Machine learning là gì mô tả.
- Từ “kiến thức”:
- TF(“kiến thức”, d1) = 2/11 ≈ 0.18
- Từ “kiến thức” xuất hiện trong cả 2 văn bản.
- IDF(“kiến thức”, D) = log(2/2) = log(1) = 0
- TF-IDF(“kiến thức”, d1) = 0.18 * 0 = 0
- Từ “hosting”:
- TF(“hosting”, d1) = 1/11 ≈ 0.09
- Từ “hosting” chỉ xuất hiện trong
d1 (1 văn bản).
- IDF(“hosting”, D) = log(2/1) = log(2) ≈ 0.693
- TF-IDF(“hosting”, d1) = 0.09 * 0.693 ≈ 0.062
Qua ví dụ trên, dù “kiến thức” xuất hiện nhiều lần nhất trong d1, nhưng vì nó cũng có mặt ở văn bản khác nên điểm TF-IDF không cao. Ngược lại, “hosting” tuy chỉ xuất hiện một lần nhưng lại là từ “độc quyền” của d1 trong tập dữ liệu này, nên nó được đánh giá là từ khóa quan trọng hơn.
Ứng dụng của TF-IDF trong thực tế
Lý thuyết là vậy, nhưng TF-IDF được ứng dụng vào thực tế như thế nào? Bạn sẽ bất ngờ khi biết rằng kỹ thuật này đang hoạt động thầm lặng trong rất nhiều công cụ bạn sử dụng hàng ngày.

Đánh giá tầm quan trọng của từ khóa trong văn bản
Đây là ứng dụng cơ bản và phổ biến nhất của TF-IDF, đặc biệt trong lĩnh vực SEO và phân tích nội dung.
Trong SEO (Tối ưu hóa công cụ tìm kiếm), các chuyên gia sử dụng các công cụ phân tích dựa trên TF-IDF để tìm ra những thuật ngữ, cụm từ mà các bài viết top đầu của Google thường sử dụng khi nói về một chủ đề nào đó. Bằng cách tính toán điểm TF-IDF của các từ khóa trên trang của mình và so sánh với đối thủ, người viết có thể xác định được những “lỗ hổng” nội dung.
Ví dụ, nếu bạn viết bài về “cách làm website WordPress” và nhận thấy các bài viết top đầu đều có điểm TF-IDF cao cho các từ như “plugin”, “theme”, “hosting“, “bảo mật”, nhưng bài của bạn lại thiếu những từ này, đó là dấu hiệu bạn cần bổ sung thêm các chủ đề con liên quan để bài viết trở nên toàn diện và có chiều sâu hơn trong mắt công cụ tìm kiếm.
Vai trò TF-IDF trong tìm kiếm thông tin và phân loại văn bản
TF-IDF là một trong những cột trụ của các hệ thống tìm kiếm thông tin (Information Retrieval). Khi bạn gõ một truy vấn vào Google, hệ thống không chỉ tìm các trang chứa từ khóa đó. Nó còn sử dụng các thuật toán tương tự TF-IDF để đánh giá xem trang nào thực sự “nói về” chủ đề bạn đang tìm kiếm.
Một trang web có điểm TF-IDF cao cho các từ trong truy vấn của bạn sẽ được xem là liên quan hơn và có khả năng được xếp hạng cao hơn. Điều này giúp hệ thống trả về kết quả chính xác, thay vì chỉ là những trang có chứa từ khóa một cách ngẫu nhiên.
Ngoài ra, TF-IDF còn được áp dụng rộng rãi trong việc phân loại và phân nhóm tài liệu. Ví dụ, một hệ thống email có thể sử dụng TF-IDF để tự động phân loại thư đến. Nếu một email có điểm số cao cho các từ “hóa đơn“, “thanh toán”, “giao dịch”, nó sẽ được tự động chuyển vào thư mục “Tài chính”. Tương tự, nó có thể được dùng để phân nhóm hàng ngàn bài báo thành các chủ đề như “Thể thao”, “Công nghệ“, “Chính trị” một cách tự động.
Ví dụ thực tiễn sử dụng TF-IDF trong học máy
Trong lĩnh vực học máy (Machine Learning), dữ liệu văn bản cần được chuyển đổi thành dạng số để các thuật toán có thể xử lý. TF-IDF chính là một trong những phương pháp phổ biến nhất để thực hiện quá trình “vector hóa” văn bản này.

Ứng dụng trong bài toán phân loại văn bản
Phân loại văn bản là một nhiệm vụ kinh điển trong học máy, ví dụ như phân loại bình luận của khách hàng là “tích cực”, “tiêu cực” hay “trung tính” (phân tích cảm xúc), hoặc xác định chủ đề của một bài viết.
Hãy tưởng tượng bạn có một tập dữ liệu gồm 10,000 bình luận về sản phẩm, mỗi bình luận đã được gán nhãn. Để xây dựng một mô hình dự đoán, bạn không thể đưa thẳng các câu chữ vào thuật toán. Thay vào đó, bạn sẽ dùng TF-IDF để biến mỗi bình luận thành một vector số. Mỗi phần tử trong vector đại diện cho điểm TF-IDF của một từ trong từ điển.
Ví dụ, bình luận “Sản phẩm này rất tốt và bền” sẽ được chuyển thành một vector có giá trị cao ở các chiều tương ứng với từ “tốt”, “bền” và giá trị thấp (hoặc 0) ở các chiều khác. Bằng cách này, mô hình học máy có thể học được mối liên hệ giữa sự xuất hiện của các từ có trọng số cao (như “tốt”, “tuyệt vời”) với nhãn “tích cực”, và ngược lại. Việc sử dụng TF-IDF giúp mô hình tập trung vào những từ ngữ mang nhiều cảm xúc và ý nghĩa, từ đó cải thiện đáng kể độ chính xác.
Tích hợp TF-IDF trong các thuật toán học máy phổ biến
TF-IDF không phải là một thuật toán học máy, mà là một bước tiền xử lý và trích xuất đặc trưng (feature extraction). Các vector do TF-IDF tạo ra có thể được dùng làm đầu vào cho nhiều thuật toán học máy khác nhau.
- Naive Bayes: Đây là một thuật toán phân loại dựa trên xác suất, hoạt động rất hiệu quả với dữ liệu văn bản. Khi kết hợp với TF-IDF, Naive Bayes có thể tính toán xác suất một văn bản thuộc về một lớp nào đó dựa trên điểm TF-IDF của các từ trong văn bản đó.
- Support Vector Machines (SVM): SVM là một thuật toán mạnh mẽ, tìm cách kẻ ra một “ranh giới” tối ưu để phân tách các lớp dữ liệu. Khi nhận đầu vào là các vector TF-IDF, SVM có thể tìm ra mặt phẳng phân cách các bình luận “tích cực” và “tiêu cực” trong không gian nhiều chiều, nơi mỗi chiều là một từ.
- K-Means Clustering: Trong các bài toán không giám sát, K-Means có thể sử dụng các vector TF-IDF để nhóm các tài liệu tương tự lại với nhau mà không cần biết trước nhãn của chúng. Các tài liệu có vector TF-IDF gần nhau trong không gian vector sẽ được gom vào cùng một cụm.
Việc tích hợp này cho phép các thuật toán cổ điển có thể xử lý hiệu quả nguồn dữ liệu phi cấu trúc khổng lồ là văn bản.
Ưu điểm và hạn chế của phương pháp TF-IDF
Mặc dù rất mạnh mẽ và phổ biến, TF-IDF không phải là một phương pháp hoàn hảo. Hiểu rõ ưu và nhược điểm của nó sẽ giúp bạn áp dụng một cách hiệu quả và biết khi nào cần tìm đến các giải pháp thay thế.

Ưu điểm nổi bật của TF-IDF
- Đơn giản và dễ hiểu: So với các mô hình ngôn ngữ phức tạp sau này như Deep learning là gì hay BERT, khái niệm và công thức của TF-IDF khá trực quan. Bạn có thể dễ dàng giải thích cách nó hoạt động và thậm chí tự mình tính toán với các ví dụ nhỏ.
- Dễ triển khai: Hầu hết các thư viện khoa học dữ liệu và học máy phổ biến (như Scikit-learn trong Python) đều có sẵn các module để tính toán TF-IDF một cách nhanh chóng, chỉ với vài dòng mã.
- Hiệu quả với dữ liệu lớn: TF-IDF hoạt động tốt trên các tập dữ liệu văn bản lớn. Nó cung cấp một cách hiệu quả để lọc nhiễu và trích xuất các thuật ngữ quan trọng mà không đòi hỏi quá nhiều tài nguyên tính toán so với các mô hình deep learning.
- Không phụ thuộc vào ngôn ngữ: Về cơ bản, TF-IDF là một phương pháp thống kê dựa trên tần suất từ, nên nó có thể áp dụng cho nhiều ngôn ngữ khác nhau mà không cần thay đổi quá nhiều về kiến trúc.
Hạn chế cần lưu ý
- Không hiểu ngữ cảnh và ngữ nghĩa: Đây là hạn chế lớn nhất của TF-IDF. Nó coi mỗi từ là một đơn vị độc lập và không hiểu được mối quan hệ ngữ nghĩa giữa chúng. Ví dụ, TF-IDF không thể biết rằng “vua” và “nữ hoàng” có liên quan đến nhau, hay “tốt” và “tuyệt vời” là đồng nghĩa. Nó cũng không phân biệt được “ngân hàng” (tổ chức tài chính) và “ngân hàng” (dữ liệu).
- Bỏ qua trật tự từ: Vì chỉ dựa trên mô hình “túi từ” (bag-of-words), TF-IDF hoàn toàn bỏ qua thứ tự của các từ trong câu. Do đó, hai câu “chó cắn người” và “người cắn chó” sẽ có cùng một vector TF-IDF, mặc dù ý nghĩa hoàn toàn trái ngược.
- Dễ bị ảnh hưởng bởi độ dài văn bản: Các văn bản dài tự nhiên có xu hướng có giá trị TF cao hơn, dù đã được chuẩn hóa. Điều này đôi khi có thể làm sai lệch kết quả.
- Không hiệu quả với từ hiếm: Mặc dù IDF được thiết kế để đề cao từ hiếm, nhưng nếu một từ quá hiếm (ví dụ, xuất hiện chỉ một lần trong một kho dữ liệu khổng lồ), nó có thể không cung cấp đủ thông tin thống kê hữu ích. Trong trường hợp này, metadata là gì cũng có thể hỗ trợ.
Các vấn đề thường gặp khi sử dụng TF-IDF
Khi bắt tay vào áp dụng TF-IDF, bạn có thể sẽ gặp phải một số thách thức thực tế. Nhận biết trước những vấn đề này sẽ giúp bạn chuẩn bị phương án đối phó tốt hơn.

TF-IDF không phân biệt được ngữ cảnh từ
Như đã đề cập ở phần hạn chế, việc không hiểu ngữ cảnh là một vấn đề cố hữu. Điều này dẫn đến những tình huống khó xử trong thực tế.
Hãy xem xét từ “bank” trong tiếng Anh. Nó có thể có nghĩa là “ngân hàng” (financial institution) hoặc “bờ sông” (river bank). Một hệ thống dựa trên TF-IDF sẽ gán cùng một trọng số cho từ “bank” bất kể nó xuất hiện trong câu “I need to go to the bank to deposit money” hay “We had a picnic on the river bank”.
Hậu quả là, nếu bạn tìm kiếm thông tin về “financial bank”, hệ thống có thể trả về các tài liệu nói về địa lý bờ sông. Trong phân tích cảm xúc, nếu từ “lạnh” xuất hiện, TF-IDF không thể biết đó là “thời tiết lạnh” (trung tính) hay “thái độ lạnh lùng” (tiêu cực). Điều này làm giảm độ chính xác và sự tinh tế của các mô hình NLP.
Khó khăn khi áp dụng TF-IDF với văn bản ngắn hoặc ít dữ liệu
TF-IDF hoạt động dựa trên quy luật thống kê của số lớn. Do đó, nó sẽ gặp khó khăn khi áp dụng cho các loại văn bản rất ngắn như tin nhắn Twitter, tiêu đề sản phẩm, hoặc các truy vấn tìm kiếm ngắn.
Với một câu chỉ vài từ, tần suất từ (TF) sẽ không mang nhiều ý nghĩa. Hầu hết các từ chỉ xuất hiện một lần, khiến giá trị TF trở nên giống nhau. Tương tự, nếu bạn chỉ có một tập hợp nhỏ các tài liệu (vài chục hoặc vài trăm), chỉ số IDF cũng sẽ không đáng tin cậy. Một từ có thể bị coi là “hiếm” trong tập dữ liệu nhỏ của bạn, nhưng thực tế lại rất phổ biến.
Để xử lý vấn đề này, các nhà phát triển thường phải mở rộng tập dữ liệu, hoặc kết hợp văn bản ngắn với các siêu dữ liệu khác (metadata là gì) để làm giàu thông tin trước khi áp dụng TF-IDF. Đôi khi, các phương pháp khác như word embeddings (Word2Vec, GloVe) sẽ phù hợp hơn cho văn bản ngắn.
Các best practices sử dụng TF-IDF hiệu quả
Để khai thác tối đa sức mạnh của TF-IDF và hạn chế các nhược điểm của nó, việc áp dụng các phương pháp thực hành tốt nhất (best practices) là vô cùng quan trọng. Đây không chỉ là việc áp dụng công thức, mà là cả một quy trình.
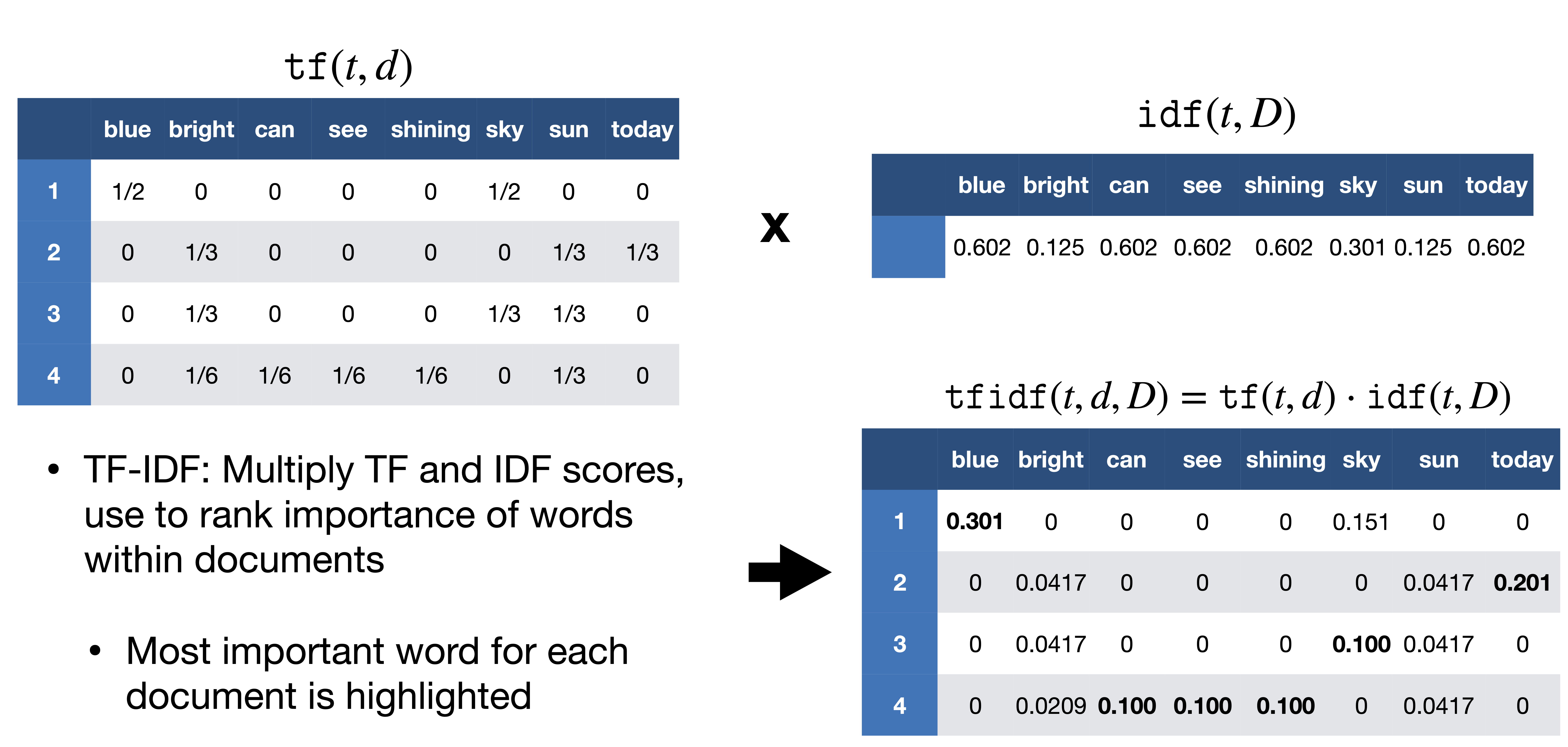
- Tiền xử lý dữ liệu kỹ lưỡng: Đây là bước quan trọng nhất. “Rác đầu vào, rác đầu ra”. Trước khi tính TF-IDF, bạn cần làm sạch dữ liệu văn bản. Quá trình này bao gồm:
- Loại bỏ stop words: Xóa các từ phổ biến nhưng không mang nhiều ý nghĩa như “là”, “của”, “và”, “thì”, “mà” trong tiếng Việt.
- Chuẩn hóa văn bản (Normalization): Đưa tất cả các từ về dạng chữ thường (lowercase).
- Stemming/Lemmatization: Đưa các từ về dạng gốc của chúng. Ví dụ, “học”, “học tập”, “đi học” có thể được đưa về cùng một gốc là “học”. Điều này giúp hợp nhất tần suất của các từ cùng nghĩa.
- Loại bỏ dấu câu, số, và các ký tự đặc biệt không cần thiết.
- Kết hợp TF-IDF với các kỹ thuật NLP khác: Đừng xem TF-IDF là cây đũa thần. Sức mạnh thực sự của nó được phát huy khi kết hợp với các kỹ thuật khác. Ví dụ, bạn có thể sử dụng TF-IDF để trích xuất các từ khóa quan trọng, sau đó dùng các mô hình word embedding (như Word2Vec) để phân tích ngữ nghĩa của các từ khóa đó.
- Không lạm dụng TF-IDF độc lập: Hãy nhận biết giới hạn của nó. Đối với các bài toán đòi hỏi sự hiểu biết sâu sắc về ngữ nghĩa, trật tự từ, hoặc ngữ cảnh (như dịch máy, chatbot phức tạp), TF-IDF một mình là không đủ. Trong những trường hợp này, nó chỉ nên là một phần trong một hệ thống lớn hơn, hoặc bạn cần xem xét các mô hình tiên tiến như mạng nơ-ron hồi quy (RNN) hay Transformer (GPT 4).
- Luôn kiểm tra và đánh giá kết quả thực tế: Sau khi áp dụng TF-IDF và xây dựng mô hình, hãy luôn kiểm tra hiệu suất của nó trên một tập dữ liệu thử nghiệm (test set) mà mô hình chưa từng thấy. So sánh kết quả với các phương pháp khác để đảm bảo rằng TF-IDF thực sự là lựa chọn phù hợp cho bài toán của bạn.
Kết luận
Qua hành trình tìm hiểu chi tiết, chúng ta có thể thấy TF-IDF không chỉ là một công thức toán học mà là một khái niệm nền tảng, một công cụ mạnh mẽ trong lĩnh vực xử lý ngôn ngữ tự nhiên và khoa học dữ liệu. Nó cung cấp một phương pháp trực quan và hiệu quả để lượng hóa tầm quan trọng của từ ngữ, giúp máy tính “nhìn” thấy những gì là cốt lõi trong một biển thông tin văn bản. Từ việc cải thiện kết quả tìm kiếm, phân loại tài liệu tự động, cho đến việc làm đầu vào cho các mô hình học máy phức tạp, vai trò của TF-IDF là không thể phủ nhận.
Tuy nhiên, điều quan trọng là phải nhận thức được những hạn chế của nó, đặc biệt là việc thiếu khả năng hiểu ngữ cảnh và ngữ nghĩa. Chính vì vậy, phương pháp thực hành tốt nhất là không nên coi TF-IDF là một giải pháp độc lập cho mọi vấn đề. Hãy xem nó như một công cụ đắc lực trong bộ đồ nghề của bạn, và khéo léo kết hợp nó với các kỹ thuật tiền xử lý dữ liệu và các mô hình NLP tiên tiến khác để đạt được hiệu quả cao nhất.
Thế giới của NLP và học máy vẫn đang phát triển không ngừng. Hy vọng bài viết này đã cung cấp cho bạn một nền tảng vững chắc về TF-IDF và truyền cảm hứng để bạn tiếp tục khám phá sâu hơn về các thuật toán thú vị khác.

