Trong thế giới quản trị server, việc duy trì hiệu suất ổn định và ngăn ngừa sự cố là ưu tiên hàng đầu. Một trong những chỉ số quan trọng nhất bạn cần theo dõi chính là tải trung bình hệ thống, hay còn gọi là System Load Average. Đây là một thông số đo lường mức độ bận rộn của server, cho bạn biết có bao nhiêu tiến trình đang hoạt động và đang phải chờ đợi tài nguyên để được xử lý. Việc hiểu và thiết lập cảnh báo cho chỉ số này không chỉ là một kỹ năng kỹ thuật, mà còn là một nghệ thuật giúp bạn giữ cho “trái tim” của hệ thống hosting luôn đập ở nhịp độ tối ưu. Tầm quan trọng của nó càng được nhân lên khi bạn chịu trách nhiệm cho nhiều website khách hàng, nơi mà mỗi giây downtime đều có thể gây ra thiệt hại. Tuy nhiên, nhiều quản trị viên mới thường bỏ qua hoặc thiết lập ngưỡng cảnh báo mặc định, dẫn đến việc nhận quá nhiều thông báo không cần thiết hoặc tệ hơn là bỏ lỡ những dấu hiệu quá tải thực sự. Bài viết này sẽ là kim chỉ nam, hướng dẫn bạn từ A-Z cách thay đổi và tối ưu hóa cảnh báo tải trung bình trên DirectAdmin, giúp bạn làm chủ hiệu năng server một cách chuyên nghiệp và hiệu quả.
Ý nghĩa và vai trò của cảnh báo tải trung bình trên DirectAdmin
Load Average là gì và cách nó ảnh hưởng đến hiệu suất server
Khi nói về Load Average, bạn sẽ thường thấy ba con số đi kèm nhau, ví dụ: 0.50, 0.75, 0.80. Các con số này lần lượt đại diện cho tải trung bình của hệ thống trong 1 phút, 5 phút và 15 phút vừa qua. Hãy tưởng tượng server của bạn như một cây cầu có nhiều làn xe, và mỗi tiến trình (task) là một chiếc xe cần đi qua. Số làn xe chính là số lõi CPU (CPU cores) của bạn. Nếu Load Average là 1.0 trên một server có 1 lõi CPU, điều đó có nghĩa là cây cầu đang được sử dụng đúng công suất, không có xe nào phải chờ. Nếu con số này tăng lên 2.0, nghĩa là có một hàng xe tương đương với số xe đang lưu thông phải xếp hàng chờ đợi.

Do đó, một Load Average cao không nhất thiết có nghĩa là CPU đang quá tải 100%. Nó có thể bao gồm cả các tiến trình đang chờ đợi các tài nguyên khác như đọc/ghi ổ cứng (I/O wait) hoặc tài nguyên mạng. Mối liên hệ này rất quan trọng: một server có thể có CPU rảnh rỗi nhưng Load Average vẫn cao vút nếu ổ cứng quá chậm, tạo thành một “nút thắt cổ chai”. Hiểu rõ điều này giúp bạn chẩn đoán chính xác hơn nguyên nhân gây chậm server, thay vì chỉ đổ lỗi cho CPU. Các con số này cung cấp một cái nhìn toàn cảnh về xu hướng tải của hệ thống. Con số 1 phút cho thấy tình hình tức thời, trong khi con số 15 phút phản ánh xu hướng tải dài hạn và ổn định hơn. Bạn có thể tham khảo thêm các kiến thức liên quan trong bài viết Cloud hosting để hiểu cách tối ưu hiệu suất server trong môi trường lưu trữ đám mây.
Tầm quan trọng của cảnh báo load average trong quản lý hosting
Cảnh báo Load Average đóng vai trò như một người lính gác tận tụy cho server của bạn. Vai trò chính của nó là phát hiện sớm các dấu hiệu bất thường và gửi thông báo cho bạn trước khi vấn đề trở nên nghiêm trọng. Thay vì đợi đến khi website ngừng hoạt động và người dùng phàn nàn, bạn có thể chủ động can thiệp ngay khi tải hệ thống bắt đầu tăng đột biến. Điều này giúp ngăn ngừa gián đoạn dịch vụ, giảm thiểu downtime đến mức tối đa và bảo vệ uy tín của bạn cũng như của khách hàng.
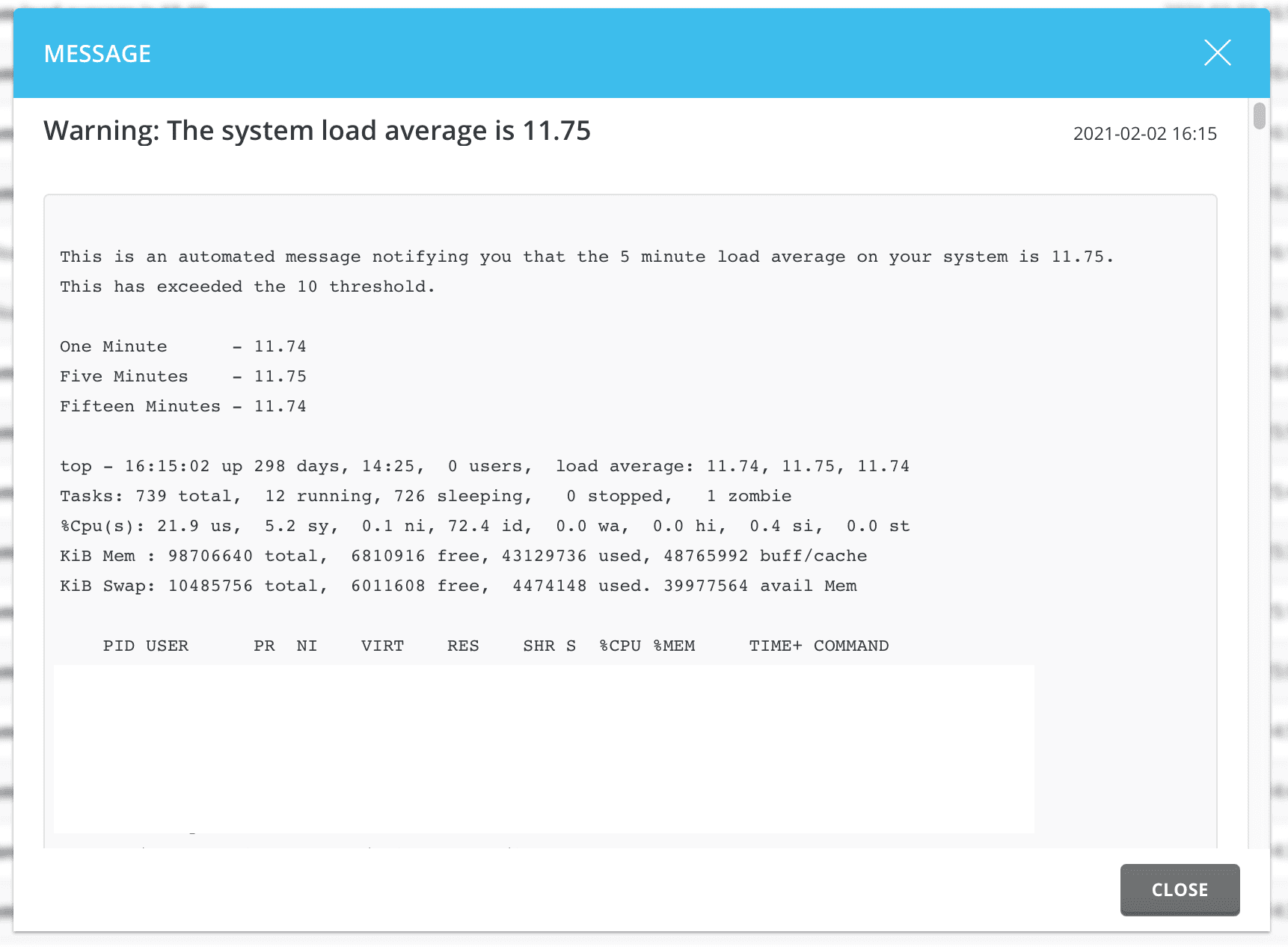
Một hệ thống cảnh báo được cấu hình tốt còn là tấm khiên bảo vệ trải nghiệm người dùng. Khi server quá tải, thời gian phản hồi của website sẽ tăng lên, gây khó chịu cho người truy cập và ảnh hưởng tiêu cực đến thứ hạng SEO. Bằng cách nhận được cảnh báo sớm, bạn có thể nhanh chóng xác định nguyên nhân, có thể là do một plugin bị lỗi, một cuộc tấn công DDoS quy mô nhỏ, hoặc một tác vụ nền đang tiêu tốn quá nhiều tài nguyên. Việc xử lý kịp thời không chỉ giữ cho website hoạt động mượt mà mà còn đảm bảo an toàn dữ liệu, tránh các rủi ro mất mát thông tin khi server bị treo hoặc sập đột ngột. Để quản lý hosting hiệu quả hơn, bạn cũng có thể tìm hiểu về các Hosting tốt nhất để chọn lựa dịch vụ phù hợp với nhu cầu của mình.
Hướng dẫn truy cập và thay đổi cấu hình load_average.conf trên DirectAdmin
Vị trí và vai trò của file load_average.conf trong hệ thống
Trái tim của hệ thống cảnh báo tải trung bình trong DirectAdmin nằm ở một file cấu hình đơn giản có tên là load_average.conf. File này chứa ngưỡng giá trị mà DirectAdmin sẽ sử dụng để so sánh với tải trung bình thực tế của server. Khi tải trung bình vượt qua ngưỡng này, DirectAdmin sẽ tự động kích hoạt một hành động, thường là gửi email cảnh báo đến quản trị viên. Việc hiểu rõ vị trí và vai trò của file này là bước đầu tiên để bạn có thể tùy chỉnh hệ thống giám sát theo nhu_cầu_của_mình. Theo mặc định, bạn có thể tìm thấy file này tại đường dẫn: /usr/local/directadmin/conf/load_average.conf. Để có thể chỉnh sửa file này, bạn cần có quyền truy cập root vào server. Nội dung bên trong file này rất đơn giản, thường chỉ chứa một dòng duy nhất, ví dụ: load_average=10. Con số 10 ở đây chính là ngưỡng cảnh báo. Bất cứ khi nào tải trung bình trong 1 phút của server vượt qua 10, một thông báo sẽ được gửi đi. Việc thay đổi con số này sẽ trực tiếp thay đổi độ nhạy của hệ thống cảnh báo. Tham khảo thêm cách sử dụng công cụ để quản lý file host trên server trong bài viết Filezilla là gì.
Các bước cụ thể để chỉnh sửa file load_average.conf
Việc chỉnh sửa file load_average.conf khá đơn giản và có thể thực hiện chỉ trong vài phút. Dưới đây là các bước chi tiết bạn cần làm theo. Đầu tiên, bạn cần truy cập vào server của mình với quyền root. Cách phổ biến nhất là sử dụng một trình khách SSH như PuTTY (trên Windows) hoặc Terminal (trên macOS/Linux). Sau khi đăng nhập thành công, bạn sẽ làm việc trực tiếp với giao diện dòng lệnh của server.
Tiếp theo, hãy sử dụng một trình soạn thảo văn bản trên dòng lệnh để mở file. Hai trình soạn thảo phổ biến nhất là nano và vi. Nếu bạn là người mới, nano sẽ dễ sử dụng hơn. Gõ lệnh sau và nhấn Enter: nano /usr/local/directadmin/conf/load_average.conf. Màn hình sẽ hiển thị nội dung của file. Bây giờ, bạn chỉ cần thay đổi con số sau dấu = thành giá trị ngưỡng mà bạn mong muốn. Ví dụ, nếu bạn muốn đặt ngưỡng cảnh báo là 8, bạn sửa dòng load_average=10 thành load_average=8. Sau khi chỉnh sửa xong, nhấn tổ hợp phím Ctrl + X, sau đó nhấn Y để xác nhận lưu thay đổi, và cuối cùng nhấn Enter để thoát khỏi nano. Để các thay đổi có hiệu lực ngay lập tức, bạn nên khởi động lại dịch vụ DirectAdmin bằng lệnh: systemctl restart directadmin. Bạn cũng có thể tìm hiểu thêm cách lựa chọn và mua hosting nước ngoài như Cách mua Hosting Hawkhost nếu muốn nâng cấp hiệu năng hosting của mình.
Thiết lập ngưỡng cảnh báo load average phù hợp với hiệu năng server
Xác định ngưỡng cảnh báo dựa trên tài nguyên phần cứng
Một trong những câu hỏi lớn nhất khi tùy chỉnh cảnh báo là: “Nên đặt ngưỡng là bao nhiêu?”. Một quy tắc chung và rất hữu ích là dựa vào số lượng lõi CPU (CPU cores) mà server của bạn có. Về lý thuyết, một server có N lõi CPU có thể xử lý đồng thời N tiến trình mà không cần phải xếp hàng. Do đó, một mức Load Average bằng với số lõi CPU được xem là mức tải tối ưu 100%. Nếu Load Average vượt qua số lõi, điều đó có nghĩa là hệ thống đang bắt đầu có hiện tượng “ùn tắc”.
Để xác định số lõi CPU của server, bạn có thể đăng nhập SSH và sử dụng lệnh nproc hoặc lscpu. Ví dụ, nếu lệnh nproc trả về kết quả là 4, server của bạn có 4 lõi. Dựa vào đó, bạn có thể đặt ngưỡng cảnh báo ban đầu là 4.0 hoặc cao hơn một chút, ví dụ 5.0 hoặc 6.0 để tránh các cảnh báo không cần thiết do các đột biến tải tạm thời. Tương tự, một server mạnh mẽ với 16 lõi có thể có ngưỡng cảnh báo an toàn ở mức 16.0 hoặc thậm chí 20.0, tùy thuộc vào loại hình dịch vụ đang chạy. Quy tắc này cung cấp một điểm khởi đầu rất tốt và thực tế hơn nhiều so với việc sử dụng một con số mặc định chung cho mọi loại server. Để lựa chọn vị trí đặt server hoặc lựa chọn hosting phù hợp với phần cứng mạnh mẽ, bạn có thể tìm hiểu thêm về Hosting Việt Nam và các dịch vụ trong nước.
Điều chỉnh ngưỡng cảnh báo nhằm cân bằng hiệu suất và độ nhạy cảnh báo
Việc chọn một ngưỡng cảnh báo hoàn hảo là một quá trình tìm kiếm sự cân bằng. Nếu bạn đặt ngưỡng quá thấp, chẳng hạn như 2.0 trên một server 4 lõi, bạn có thể sẽ bị “ngập” trong email cảnh báo mỗi khi có một tác vụ hơi nặng một chút chạy, ví dụ như quá trình sao lưu hàng đêm. Tình trạng này được gọi là “mệt mỏi vì cảnh báo” (alert fatigue), khiến bạn có xu hướng bỏ qua các thông báo và có thể lỡ mất một cảnh báo quan trọng thực sự.
Ngược lại, nếu đặt ngưỡng quá cao, ví dụ 15.0 trên server 4 lõi, thì khi cảnh báo được gửi đi, server của bạn có thể đã ở trong tình trạng quá tải nghiêm trọng, thậm chí gần như không thể truy cập được. Chiến lược tốt nhất là bắt đầu với ngưỡng bằng số lõi CPU, sau đó quan sát hoạt động của server trong một vài tuần. Nếu bạn không nhận được cảnh báo nào trong khi cảm thấy website đôi khi bị chậm, hãy thử giảm ngưỡng xuống một chút. Nếu bạn nhận được quá nhiều cảnh báo về các đợt tăng tải ngắn và vô hại, hãy tăng ngưỡng lên. Mục tiêu là tìm ra “điểm ngọt” nơi mà hệ thống chỉ cảnh báo khi có nguy cơ quá tải thực sự, giúp bạn tập trung vào những vấn đề đáng quan tâm. Việc này rất quan trọng khi vận hành các dịch vụ đặc thù như Hosting server Minecraft hoặc các kiểu hosting chuyên biệt khác.
Kiểm tra và xác nhận cảnh báo load average hoạt động hiệu quả trên DirectAdmin
Các công cụ kiểm tra và giám sát load average
Sau khi đã cấu hình xong ngưỡng cảnh báo, làm thế nào để bạn biết nó đang hoạt động đúng? Việc kiểm tra và giám sát thường xuyên là rất quan trọng. May mắn là Linux cung cấp nhiều công cụ mạnh mẽ ngay trên dòng lệnh để bạn xem các thông số hệ thống theo thời gian thực. Lệnh đơn giản và nhanh nhất là uptime. Chỉ cần gõ uptime và nhấn Enter, bạn sẽ thấy ngay lập tức ba con số Load Average của 1, 5 và 15 phút.
Để có cái nhìn chi tiết hơn, bạn có thể sử dụng lệnh top. Lệnh này cung cấp một bảng điều khiển trực tiếp, hiển thị danh sách các tiến trình đang chạy, mức sử dụng CPU, RAM và cả Load Average. Một công cụ khác thân thiện và nhiều màu sắc hơn là htop. Nếu chưa có, bạn có thể dễ dàng cài đặt nó (yum install htop hoặc apt install htop). htop hiển thị thông tin một cách trực quan hơn, giúp bạn dễ dàng nhận biết các tiến trình đang “ăn” nhiều tài nguyên nhất. Ngoài ra, đừng quên kiểm tra hệ thống tin nhắn (Message System) ngay trong giao diện DirectAdmin hoặc hộp thư email của quản trị viên. Đây là nơi các cảnh báo sẽ được gửi đến, và việc kiểm tra lịch sử cảnh báo có thể cho bạn biết tần suất và thời điểm server thường bị quá tải. Để duy trì và nâng cao hiệu suất các dịch vụ hosting như vậy, bạn cần hiểu rõ về các loại Hosting là gì cũng như chọn lựa dịch vụ tối ưu.
Xác nhận cảnh báo đã được thiết lập đúng và hoạt động thực tế
Việc giám sát là cần thiết, nhưng để chắc chắn 100% rằng hệ thống cảnh báo sẽ hoạt động khi cần, bạn có thể thực hiện một bài kiểm tra giả định. Phương pháp này bao gồm việc tạo ra một lượng tải nhân tạo trên server để đẩy Load Average vượt qua ngưỡng bạn đã thiết lập và xem liệu cảnh báo có được gửi đi hay không. Một công cụ phổ biến để làm việc này là stress-ng. Lưu ý cực kỳ quan trọng: Bạn chỉ nên thực hiện việc này trong giờ thấp điểm hoặc trên một môi trường thử nghiệm (staging server) để tránh ảnh hưởng đến người dùng. Ví dụ, nếu server của bạn có 4 lõi và bạn đã đặt ngưỡng cảnh báo là 5, bạn có thể chạy lệnh stress-ng --cpu 6 --timeout 120s để tạo ra tải trên 6 lõi CPU trong vòng 2 phút. Trong khi lệnh này đang chạy, hãy sử dụng lệnh uptime hoặc htop ở một cửa sổ SSH khác để theo dõi Load Average tăng lên. Sau khoảng một phút, nếu mọi thứ được cấu hình chính xác, bạn sẽ nhận được một email cảnh báo từ DirectAdmin. Nếu không nhận được, đó là lúc bạn cần quay lại và kiểm tra các bước khắc phục sự cố, như cấu hình email hay quyền của file. Đây cũng là phần quan trọng trong việc đảm bảo hosting của bạn hoạt động ổn định, tương tự như khi lựa chọn Hosting Windows phù hợp với nhu cầu.
Các vấn đề thường gặp khi thay đổi cảnh báo load average
Cảnh báo không được gửi hoặc nhận
Một trong những vấn đề gây bối rối nhất là khi bạn đã thiết lập mọi thứ nhưng lại không nhận được bất kỳ cảnh báo nào, ngay cả khi bạn biết chắc rằng server đã quá tải. Nguyên nhân phổ biến nhất thường không nằm ở file load_average.conf mà là ở hệ thống gửi mail của server. Đầu tiên, hãy kiểm tra xem địa chỉ email của quản trị viên trong DirectAdmin có được cấu hình chính xác hay không. Sau đó, hãy đảm bảo rằng dịch vụ mail server (thường là Exim trên các hệ thống CentOS/AlmaLinux) đang hoạt động bình thường. Bạn có thể kiểm tra nhật ký mail tại /var/log/exim/mainlog để tìm kiếm các lỗi liên quan đến việc gửi mail.
Một nguyên nhân khác có thể là do các vấn đề về quyền truy cập. Hãy chắc chắn rằng file /usr/local/directadmin/conf/load_average.conf có quyền đọc đối với người dùng diradmin. Bạn có thể kiểm tra bằng lệnh ls -l /usr/local/directadmin/conf/load_average.conf. Cuối cùng, một số nhà cung cấp dịch vụ hosting hoặc tường lửa có thể chặn cổng 25 (cổng gửi mail mặc định), ngăn không cho server của bạn gửi email ra ngoài. Trong trường hợp này, bạn có thể cần cấu hình server sử dụng một dịch vụ SMTP relay bên ngoài để đảm bảo email cảnh báo được gửi đi thành công. Việc đảm bảo dịch vụ hosting không bị gián đoạn cũng tương tự như việc cân nhắc lựa chọn Hosting miễn phí với các hạn chế và ưu điểm riêng.
Cảnh báo sai lệch hoặc báo quá nhiều
Vấn đề ngược lại là nhận được quá nhiều cảnh báo, đến mức chúng trở nên vô nghĩa. Nếu bạn liên tục nhận được email thông báo về tải cao rồi lại thấy thông báo tải đã trở lại bình thường chỉ sau vài phút, nguyên nhân lớn nhất là do ngưỡng cảnh báo của bạn đang được đặt quá thấp so với mức tải hoạt động bình thường của server. Các tác vụ nền như sao lưu dữ liệu, quét virus, hoặc một lượng lớn truy cập đột ngột từ bot tìm kiếm có thể gây ra các đợt tăng tải ngắn hạn. Đây là hoạt động bình thường và không nhất thiết là dấu hiệu của một vấn đề nghiêm trọng.

Để giải quyết vấn đề này, hãy xem xét lại ngưỡng cảnh báo của bạn. Thay vì chỉ dựa vào con số tải trong 1 phút, hãy phân tích cả xu hướng tải trong 5 và 15 phút. Nếu tải 1 phút cao nhưng tải 15 phút vẫn ở mức thấp, đó có thể chỉ là một đột biến tạm thời. Bạn có thể cần tăng nhẹ ngưỡng cảnh báo của mình lên một chút. Đồng thời, hãy điều tra các tiến trình thường xuyên gây ra tải cao. Sử dụng lệnh top hoặc htop trong những thời điểm nhận được cảnh báo để xác định xem có một cron job hay một ứng dụng cụ thể nào là thủ phạm hay không. Tối ưu hóa các tiến trình này cũng là một cách hiệu quả để giảm thiểu các cảnh báo sai. Đây cũng là cách bạn có thể áp dụng nếu đang vận hành Hosting video hoặc dịch vụ lưu trữ đòi hỏi hiệu suất cao và ổn định.
Lời khuyên và thực hành tốt dành cho quản trị viên
Để trở thành một quản trị viên server chuyên nghiệp, việc thiết lập cảnh báo chỉ là bước khởi đầu. Dưới đây là những lời khuyên và thực hành tốt nhất bạn nên áp dụng. Đầu tiên, đừng bao giờ dựa hoàn toàn vào hệ thống cảnh báo tự động. Hãy tạo thói quen đăng nhập vào server và kiểm tra các thông số hiệu suất, bao gồm Load Average, ít nhất một lần mỗi ngày. Việc theo dõi thường xuyên giúp bạn nắm bắt được “nhịp đập” bình thường của server và dễ dàng phát hiện các xu hướng bất thường trước khi chúng trở thành vấn đề.
Thứ hai, hãy tùy chỉnh ngưỡng cảnh báo cho từng server cụ thể. Một server chuyên chạy web có thể chịu được mức tải đột biến cao hơn so với một server cơ sở dữ liệu, nơi mà sự ổn định và độ trễ thấp là yếu tố sống còn. Đừng áp dụng một con số mặc định cho tất cả. Hãy dành thời gian phân tích và tìm ra con số tối ưu cho từng môi trường. Bên cạnh đó, hãy kết hợp giám sát Load Average với các chỉ số quan trọng khác như mức sử dụng RAM, hoạt động đọc/ghi ổ cứng (I/O), và lưu lượng mạng. Một cái nhìn toàn diện sẽ giúp bạn chẩn đoán vấn đề chính xác hơn. Luôn nhớ sao lưu file cấu hình trước khi thực hiện bất kỳ thay đổi nào. Một lệnh đơn giản như cp load_average.conf load_average.conf.bak có thể cứu bạn khỏi những sai lầm không đáng có. Cuối cùng, một quy tắc vàng: không bao giờ thay đổi cấu hình hoặc khởi động lại các dịch vụ quan trọng khi server đang trong tình trạng quá tải nghiêm trọng, vì điều đó có thể làm tình hình tồi tệ hơn. Việc tối ưu và bảo mật hosting bạn nên đọc thêm tại bài Hosting là gì để có cái nhìn tổng quan.
Kết luận
Việc quản lý và giám sát tải trung bình hệ thống là một nhiệm vụ nền tảng nhưng vô cùng quan trọng đối với bất kỳ quản trị viên nào làm việc với DirectAdmin. Nó không chỉ đơn thuần là việc thay đổi một con số trong file cấu hình, mà là cả một quá trình thấu hiểu sâu sắc về hoạt động và giới hạn của server. Một hệ thống cảnh báo được tinh chỉnh tốt sẽ hoạt động như một người trợ lý ảo đáng tin cậy, giúp bạn phát hiện sớm các nguy cơ, chủ động xử lý sự cố và đảm bảo rằng các dịch vụ hosting luôn hoạt động ổn định và hiệu quả. Nó mang lại sự an tâm, cho phép bạn tập trung vào việc phát triển kinh doanh thay vì phải liên tục lo lắng về hiệu suất của hạ tầng.
Qua bài viết này, Bùi Mạnh Đức đã cung cấp cho bạn một lộ trình chi tiết, từ việc hiểu rõ khái niệm Load Average đến các bước thực hành cụ thể và những lời khuyên hữu ích. Đừng ngần ngại áp dụng ngay những kiến thức này. Hãy dành chút thời gian để đăng nhập vào server của bạn, kiểm tra lại cấu hình cảnh báo hiện tại và điều chỉnh nó cho phù hợp với đặc điểm phần cứng cũng như nhu cầu sử dụng của bạn. Đây là một hành động nhỏ nhưng có thể tạo ra tác động lớn, giúp bảo vệ server và mang lại trải nghiệm tốt nhất cho người dùng cuối. Nếu bạn muốn tìm hiểu sâu hơn, hãy tiếp tục khám phá các bài viết khác trên blog về tối ưu hiệu suất server và bảo mật hosting trên DirectAdmin.