Giới thiệu về xử lý URL trong Python
Bạn có bao giờ tự hỏi URL hoạt động ra sao trong Python không? Trong thời đại số hóa hiện tại, việc xử lý URL đã trở thành kỹ năng thiết yếu cho mọi lập trình viên Python. Từ việc phát triển website đến web scraping, khả năng thao tác với địa chỉ web một cách linh hoạt sẽ giúp bạn tiết kiệm hàng giờ đồng hồ công việc.

Việc xử lý URL là bước quan trọng giúp truy xuất dữ liệu web hiệu quả. Khi bạn cần lấy thông tin từ một website, gửi dữ liệu đến API, hoặc phân tích cấu trúc của hàng trăm trang web, việc hiểu rõ cách thao tác với URL sẽ là chìa khóa thành công. Python cung cấp nhiều công cụ mạnh mẽ để giúp bạn xử lý URL một cách chuyên nghiệp.
Bài viết này sẽ hướng dẫn bạn cách phân tích, tạo và sửa URL, kèm theo các thao tác gửi HTTP request thực tế. Tôi sẽ chia sẻ kinh nghiệm từ các dự án thực tế, giúp bạn tránh những sai lầm phổ biến. Nội dung được chia thành các bước từ cơ bản đến nâng cao, dễ theo dõi cho mọi trình độ – từ người mới bắt đầu đến developer có kinh nghiệm.
Các thư viện tiêu chuẩn để xử lý URL trong Python
Giới thiệu urllib và các module con
Python tích hợp sẵn bộ thư viện urllib – một công cụ mạnh mẽ để xử lý URL mà bạn không cần cài đặt thêm. Nhưng urllib không phải là một module đơn lẻ, mà là một tập hợp các module nhỏ, mỗi module phục vụ một mục đích riêng biệt.
Module urllib.parse chính là “thần tài” giúp bạn phân tích và xây dựng URL. Nó có thể tách một URL phức tạp thành từng phần riêng biệt như domain, đường dẫn, tham số query. Khi nào bạn nên dùng urllib.parse? Câu trả lời là bất cứ khi nào bạn cần hiểu cấu trúc của một URL hoặc tạo URL mới từ các thành phần khác nhau.
Trong khi đó, urllib.request đóng vai trò như một “người đưa thư” giúp bạn gửi request HTTP đơn giản. Nó có thể download nội dung từ website, gửi dữ liệu đến server, và xử lý các response cơ bản. Mặc dù không mạnh mẽ bằng các thư viện khác, urllib.request vẫn là lựa chọn tốt cho các tác vụ đơn giản.
Các thư viện phổ biến khác
Requests là thư viện “siêu sao” trong cộng đồng Python khi nói đến việc gửi HTTP request. Nếu urllib.request là chiếc xe đạp, thì requests chính là chiếc ô tô – mạnh mẽ, tiện lợi và dễ sử dụng hơn rất nhiều. Thư viện này được thiết kế với triết lý “HTTP cho con người”, có nghĩa là API rất trực quan và dễ hiểu.
Ưu điểm của requests là gì? Đầu tiên, cú pháp đơn giản hơn nhiều so với urllib.request. Thứ hai, nó tự động xử lý nhiều thao tác phức tạp như quản lý cookie, xử lý redirect, và encode dữ liệu. Cuối cùng, requests hỗ trợ nhiều tính năng nâng cao như authentication, session management, và connection pooling.
Để cài đặt requests, bạn chỉ cần chạy lệnh pip install requests trong terminal. Sau khi cài đặt, việc gửi một GET request đơn giản chỉ cần một dòng code: response = requests.get('https://example.com'). Đơn giản và trực quan đến vậy!
Phân tích và trích xuất thành phần URL
Cấu trúc URL chuẩn và các thành phần
Bạn có biết một URL giống như địa chỉ nhà, mỗi phần có ý nghĩa riêng biệt? Hãy cùng phân tích URL https://www.example.com:8080/path/to/page?param1=value1¶m2=value2#section1 để hiểu rõ hơn.
Scheme (giao thức) là “https” – cho biết cách thức giao tiếp với server. Netloc (network location) bao gồm “www.example.com:8080” – đây là địa chỉ server và cổng kết nối. Path là “/path/to/page” – đường dẫn đến tài nguyên cụ thể trên server. Query string “param1=value1¶m2=value2” chứa các tham số bổ sung. Fragment “#section1” chỉ định vị trí cụ thể trong trang.
Vì sao cần tách nhỏ URL thành từng phần? Điều này giúp bạn dễ dàng sửa đổi chỉ một phần của URL mà không ảnh hưởng đến phần khác. Ví dụ, bạn có thể thay đổi tham số query để lọc dữ liệu khác nhau từ cùng một API endpoint.
Sử dụng urllib.parse để phân tích URL
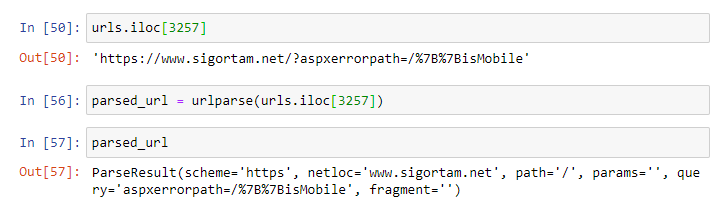
Hàm urlparse() là công cụ chính để phân tích URL trong Python. Nó trả về một đối tượng ParseResult chứa tất cả thành phần của URL. Hãy xem ví dụ thực tế:
from urllib.parse import urlparse
url = 'https://buimanhduc.com/category/python?sort=date&limit=10#latest'
parsed = urlparse(url)
print(f"Scheme: {parsed.scheme}")
print(f"Netloc: {parsed.netloc}")
print(f"Path: {parsed.path}")
print(f"Query: {parsed.query}")
print(f"Fragment: {parsed.fragment}")

Sự khác biệt giữa urlparse() và urlsplit() là gì? Trong khi urlparse() tách params thành phần riêng, urlsplit() gộp params vào path. Trong hầu hết trường hợp, urlparse() sẽ đáp ứng nhu cầu của bạn tốt hơn vì nó cung cấp thông tin chi tiết hơn.
Việc trích xuất từng thành phần URL từ chuỗi đầu vào giúp bạn dễ dàng xử lý các tác vụ như kiểm tra domain có hợp lệ không, lấy tên file từ đường dẫn, hoặc phân tích các tham số được gửi qua URL. Bạn có thể xem thêm kiểu dữ liệu trong Python để hiểu về cách quản lý dữ liệu hiệu quả hơn.
Tạo, chỉnh sửa và kết hợp URL
Xây dựng URL mới từ các phần riêng biệt
Sau khi học cách tách URL, bạn cũng cần biết cách ghép chúng lại. Hàm urlunparse() hoạt động ngược lại với urlparse() – nó nhận vào 6 thành phần và trả về URL hoàn chỉnh.
from urllib.parse import urlunparse
parts = ('https', 'buimanhduc.com', '/tutorials/python', '', 'level=beginner', 'intro')
new_url = urlunparse(parts)
print(new_url) # https://buimanhduc.com/tutorials/python?level=beginner#intro
Việc kết hợp các thành phần URL linh hoạt giúp bạn tạo ra các URL động dựa trên logic của ứng dụng. Ví dụ, bạn có thể tạo URL khác nhau cho từng người dùng, hoặc thay đổi tham số dựa trên input của họ. Đây là kỹ thuật quan trọng khi xây dựng hàm trong Python để tái sử dụng code hiệu quả.
Chỉnh sửa URL và cập nhật tham số query
Một trong những tác vụ phổ biến nhất là thao tác với query parameters. Hàm parse_qs() giúp bạn chuyển query string thành dictionary, trong khi urlencode() làm ngược lại.
from urllib.parse import urlparse, parse_qs, urlencode, urlunparse
url = 'https://api.example.com/search?q=python&page=1'
parsed = urlparse(url)
query_dict = parse_qs(parsed.query)
# Thêm tham số mới
query_dict['limit'] = ['20']
# Sửa tham số có sẵn
query_dict['page'] = ['2']
new_query = urlencode(query_dict, doseq=True)
new_url = urlunparse((parsed.scheme, parsed.netloc, parsed.path,
parsed.params, new_query, parsed.fragment))

Kỹ thuật này đặc biệt hữu ích trong web scraping khi bạn cần duyệt qua nhiều trang kết quả, hoặc trong việc phát triển API client để gửi các request với tham số khác nhau. Để học thêm về cấu trúc và kỹ thuật lập trình hiệu quả, bạn có thể tham khảo bài viết về vòng lặp trong Python.
Gửi HTTP request với URL trong Python
Dùng urllib.request để lấy dữ liệu từ URL
Urllib.request cung cấp cách đơn giản để gửi GET request và nhận response. Mặc dù không mạnh mẽ bằng requests, nó vẫn đủ cho các tác vụ cơ bản:
from urllib.request import urlopen
from urllib.error import URLError
try:
with urlopen('https://buimanhduc.com') as response:
data = response.read()
print(f"Status: {response.status}")
print(f"Content-Type: {response.headers['Content-Type']}")
except URLError as e:
print(f"Error: {e}")
Việc xử lý response và lỗi cơ bản là điều quan trọng. Bạn cần luôn đặt code trong khối try-except để bắt các lỗi có thể xảy ra như timeout, connection refused, hoặc HTTP error. Nếu bạn muốn tìm hiểu sâu hơn về cách xử lý lỗi và các vòng lặp, hãy đọc bài viết vòng lặp while trong Python để nâng cao kỹ năng lập trình.
Sử dụng thư viện requests trong thực tế
Requests làm mọi thứ trở nên đơn giản hơn rất nhiều. Cú pháp trực quan và khả năng xử lý tự động nhiều thao tác phức tạp:
import requests
# GET request đơn giản
response = requests.get('https://api.github.com/users/buimanhduc')
print(response.json())
# POST request với data
data = {'username': 'user', 'password': 'pass'}
response = requests.post('https://httpbin.org/post', json=data)
# Thiết lập headers và timeout
headers = {'User-Agent': 'My App 1.0'}
response = requests.get('https://example.com',
headers=headers,
timeout=10)
Requests tự động xử lý JSON response, quản lý session, handle redirects, và nhiều tính năng khác. Đây chính là lý do tại sao nó được ưa chuộng hơn urllib.request trong các dự án thực tế.
Các lỗi phổ biến và cách khắc phục khi xử lý URL
Lỗi URL không hợp lệ và InvalidURL
Một trong những lỗi phổ biến nhất là URL không đúng định dạng. Điều này có thể xảy ra khi URL chứa ký tự đặc biệt không được encode đúng cách, hoặc thiếu scheme.
from urllib.parse import urlparse
from urllib.error import URLError
def validate_url(url):
try:
result = urlparse(url)
return all([result.scheme, result.netloc])
except Exception:
return False
# Test với các URL khác nhau
urls = [
'https://buimanhduc.com', # Hợp lệ
'buimanhduc.com', # Thiếu scheme
'https://trang web.com', # Có dấu cách
]

Nguyên nhân chính của lỗi này thường là dữ liệu đầu vào từ người dùng không được kiểm tra kỹ. Cách khắc phục là luôn validate URL trước khi sử dụng và sử dụng urllib.parse.quote() để encode các ký tự đặc biệt.
Lỗi timeout và kết nối không thành công
Timeout là vấn đề thường gặp khi làm việc với mạng. Server có thể phản hồi chậm hoặc không phản hồi, dẫn đến ứng dụng bị “đơ”.
import requests
from requests.exceptions import Timeout, ConnectionError
def safe_request(url, timeout=10):
try:
response = requests.get(url, timeout=timeout)
return response
except Timeout:
print("Request timed out")
except ConnectionError:
print("Connection failed")
except Exception as e:
print(f"Unexpected error: {e}")
return None

Cách thiết lập timeout hợp lý và xử lý ngoại lệ hiệu quả sẽ giúp ứng dụng của bạn ổn định hơn. Thông thường, timeout 10-30 giây là phù hợp cho hầu hết các trường hợp sử dụng.
Best Practices khi xử lý URL trong Python
Kinh nghiệm từ các dự án thực tế cho thấy những nguyên tắc sau sẽ giúp bạn tránh được nhiều rắc rối:
Đầu tiên, luôn kiểm tra URL hợp lệ trước khi xử lý. Điều này không chỉ tránh lỗi runtime mà còn giúp bảo mật ứng dụng tốt hơn. Sử dụng urllib.parse để validate thay vì regex phức tạp.
Thứ hai, ưu tiên sử dụng urllib.parse để tránh lỗi cú pháp URL. Thư viện này đã được test kỹ lưỡng và handle được hầu hết các trường hợp edge case. Đừng cố gắng parse URL bằng string manipulation.
Thứ ba, sử dụng requests thay vì urllib.request khi cần thao tác HTTP nâng cao. Requests có API dễ sử dụng hơn và tích hợp nhiều tính năng hữu ích. Chỉ dùng urllib.request khi bạn muốn tránh dependencies bên ngoài.
Tránh hardcode URL trong code, thay vào đó hãy sử dụng biến môi trường hoặc config file. Điều này giúp ứng dụng linh hoạt hơn khi triển khai ở các môi trường khác nhau. Sử dụng các hàm helper để tạo URL động dựa trên parameters.
Cuối cùng, bắt ngoại lệ và log lỗi rõ ràng trong quá trình làm việc. Điều này giúp debug dễ dàng hơn và cải thiện trải nghiệm người dùng khi có lỗi xảy ra.
Kết luận
Xử lý URL trong Python là kỹ năng thiết yếu mà mọi developer cần nắm vững. Từ việc phát triển web application đến web scraping, khả năng thao tác với URL một cách chuyên nghiệp sẽ giúp bạn tiết kiệm thời gian và tạo ra những ứng dụng mạnh mẽ hơn.
Thông qua bài viết này, chúng ta đã cùng nhau khám phá từ những kiến thức cơ bản về cấu trúc URL đến các kỹ thuật nâng cao như xử lý query parameters và gửi HTTP requests. Việc tận dụng urllib và requests để thao tác URL một cách linh hoạt và mạnh mẽ sẽ mở ra nhiều cơ hội mới trong các dự án của bạn.
Hãy thực hành với các ví dụ mà tôi đã chia sẻ và thử áp dụng vào các bài tập thực tế để nắm vững kiến thức này. Bắt đầu với những tác vụ đơn giản như phân tích URL của các website bạn thường xuyên truy cập, sau đó tiến đến việc xây dựng các công cụ web scraping hoặc API client.
Đừng ngần ngại hỏi và trao đổi với cộng đồng lập trình viên Python để cùng tiến bộ trong hành trình coding của bạn. Mỗi dự án thực tế sẽ mang đến những thách thức mới, và kinh nghiệm xử lý URL sẽ là nền tảng vững chắc giúp bạn vượt qua mọi khó khăn. Chúc bạn thành công và tạo ra những ứng dụng tuyệt vời!