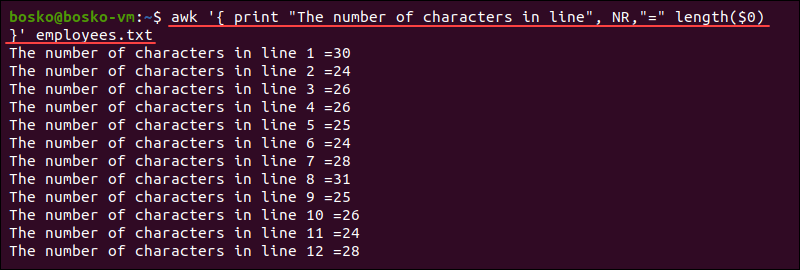
Trong thế giới quản trị hệ thống Linux, dòng lệnh là một công cụ quyền năng không thể thiếu. Giữa vô vàn tiện ích, lệnh AWK nổi lên như một “con dao đa năng” của Thụy Sĩ, chuyên dùng để xử lý và thao tác dữ liệu văn bản. Tuy nhiên, nhiều người dùng mới, đặc biệt là những ai chưa quen với shell scripting, thường cảm thấy bối rối trước cú pháp và khả năng của nó. Họ gặp khó khăn khi cần trích xuất thông tin cụ thể, tính toán trên các cột dữ liệu hay định dạng lại báo cáo từ các file log, CSV. Lệnh AWK ra đời để giải quyết chính xác vấn đề này, cung cấp một phương pháp cực kỳ nhanh chóng và linh hoạt để biến những tập tin văn bản thô kệch thành thông tin có giá trị. Bài viết này sẽ là kim chỉ nam của bạn, dẫn dắt bạn từ những khái niệm cơ bản nhất về AWK, qua các ví dụ minh họa trực quan, đến những mẹo sử dụng hiệu quả để bạn có thể tự tin làm chủ công cụ mạnh mẽ này.
Giới thiệu về lệnh AWK và vai trò trong hệ điều hành Linux
Lệnh AWK là một công cụ không thể thiếu đối với bất kỳ ai làm việc thường xuyên trên môi trường Linux. Hiểu rõ về nó sẽ mở ra cho bạn nhiều khả năng xử lý dữ liệu mạnh mẽ.
Lệnh AWK là gì?
AWK là một ngôn ngữ lập trình thông dịch được thiết kế chuyên biệt cho việc xử lý văn bản. Tên của nó được viết tắt từ họ của ba tác giả đã tạo ra nó vào năm 1977 tại Bell Labs: Alfred Aho, Peter Weinberger và Brian Kernighan. Chức năng chính của AWK là quét một hoặc nhiều tập tin theo từng dòng, tìm kiếm các mẫu (pattern) mà bạn chỉ định và thực hiện các hành động (action) tương ứng.
Sức mạnh cốt lõi của AWK nằm ở khả năng nhận diện dữ liệu theo từng cột (field). Nó tự động chia mỗi dòng thành các cột dựa trên ký tự phân cách (mặc định là khoảng trắng), cho phép bạn dễ dàng truy cập, so sánh và thao tác với từng phần dữ liệu riêng lẻ. Điều này làm cho AWK trở thành công cụ cực kỳ quan trọng và hiệu quả khi xử lý các loại dữ liệu có cấu trúc như file log, file CSV, hoặc bất kỳ tập tin văn bản nào được tổ chức theo cột.
Vai trò của AWK trong quản trị hệ thống và lập trình shell
Trong quản trị hệ thống, AWK đóng vai trò như một trợ thủ đắc lực giúp tự động hóa các tác vụ hàng ngày. Bạn có thể dùng AWK để nhanh chóng phân tích file log hệ thống, trích xuất các cảnh báo lỗi, tạo báo cáo tóm tắt về việc sử dụng tài nguyên CPU hoặc bộ nhớ, hay lọc ra những thông tin quan trọng từ output của các lệnh khác.
Khi kết hợp trong các kịch bản shell (shell script), AWK phát huy tối đa sức mạnh. Nó không chỉ đơn thuần là một bộ lọc dữ liệu. Bạn có thể thực hiện các phép tính toán học, sử dụng biến, vòng lặp và các câu lệnh điều kiện ngay trong một dòng lệnh AWK. So với các công cụ xử lý dòng lệnh khác, AWK có sự khác biệt rõ rệt. Trong khi grep chuyên dùng để tìm kiếm và lọc các dòng chứa một chuỗi ký tự, và sed tập trung vào việc chỉnh sửa nội dung của dòng, thì AWK vượt trội hơn ở khả năng xử lý dữ liệu theo từng cột. Nó giống như một công cụ xử lý bảng tính thu nhỏ ngay trên terminal của bạn.
Cú pháp cơ bản của lệnh AWK
Để làm chủ AWK, điều đầu tiên bạn cần nắm vững chính là cú pháp của nó. Thoạt nhìn có vẻ phức tạp, nhưng khi phân tích từng thành phần, bạn sẽ thấy nó rất logic và có cấu trúc.
Cấu trúc chung của câu lệnh AWK
Một câu lệnh AWK cơ bản nhất luôn tuân theo cấu trúc sau:
awk 'pattern {action}' filename
Hãy cùng phân tích từng phần để hiểu rõ hơn:
- awk: Là lệnh để gọi chương trình AWK.
- ‘pattern {action}’: Đây là phần chương trình cốt lõi mà bạn viết để AWK thực thi, luôn được đặt trong cặp dấu nháy đơn
''.
- pattern: Là một điều kiện. AWK sẽ kiểm tra điều kiện này trên mỗi dòng của tập tin. Nếu điều kiện đúng (true), hành động trong khối
action sẽ được thực thi trên dòng đó. Nếu bạn bỏ qua pattern, hành động sẽ được áp dụng cho tất cả các dòng.
- {action}: Là một hoặc nhiều lệnh mà AWK sẽ thực hiện khi
pattern được thỏa mãn. Phần này phải được đặt trong cặp dấu ngoặc nhọn {}. Hành động phổ biến nhất là print để in dữ liệu ra màn hình.
- filename: Là tên của tập tin đầu vào mà AWK sẽ xử lý.
Bạn có thể hình dung cấu trúc này như một câu mệnh lệnh: “Này AWK, với mỗi dòng trong filename, nếu nó khớp với pattern, hãy thực hiện action.”

Các thành phần thường gặp
Khi viết chương trình AWK, bạn sẽ thường xuyên làm việc với các biến và hàm nội tại của nó. Đây là những công cụ cơ bản giúp bạn thao tác với dữ liệu.
Các biến nội tại (built-in variables) quan trọng nhất bao gồm:
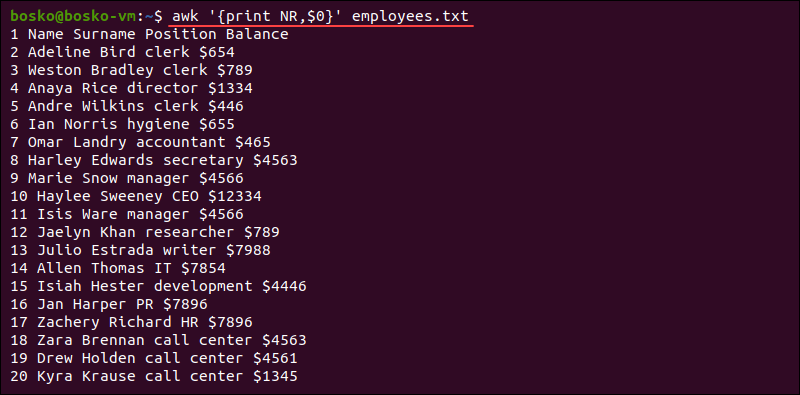
- $0: Đại diện cho toàn bộ nội dung của dòng hiện tại đang được xử lý.
- $1, $2, $3,…: Đại diện cho nội dung của cột (field) thứ nhất, thứ hai, thứ ba,… trong dòng hiện tại. AWK tự động chia dòng thành các cột dựa trên ký tự phân cách.
- NF (Number of Fields): Lưu số lượng cột trong dòng hiện tại. Biến này rất hữu ích để kiểm tra cấu trúc dữ liệu hoặc truy cập vào cột cuối cùng bằng cách dùng
$NF.
- NR (Number of Records): Lưu số thứ tự của dòng hiện tại đang được xử lý. Nó bắt đầu đếm từ 1.
Bên cạnh các biến, AWK cũng cung cấp nhiều hàm cơ bản, trong đó phổ biến nhất là:
- print: Dùng để in ra màn hình. Bạn có thể in toàn bộ dòng (
print $0), một vài cột cụ thể (print $1, $3), hoặc thậm chí là các chuỗi văn bản và kết quả tính toán.
- length(s): Trả về độ dài (số ký tự) của chuỗi
s. Ví dụ, length($1) sẽ cho bạn biết độ dài của cột đầu tiên.
- substr(s, i, n): Trích xuất một chuỗi con dài
n ký tự từ chuỗi s, bắt đầu từ vị trí i.
Nắm vững các biến và hàm này là chìa khóa để viết các kịch bản AWK từ đơn giản đến phức tạp.
Các ví dụ minh họa sử dụng lệnh AWK trong xử lý dữ liệu
Lý thuyết sẽ dễ hiểu hơn rất nhiều khi đi kèm với các ví dụ thực tế. Hãy cùng xem qua một vài tình huống phổ biến để thấy được sức mạnh của AWK. Giả sử chúng ta có một file văn bản tên là nhanvien.txt với nội dung như sau:
101 Tuan Anh Marketing 50000
102 Minh Hang Sales 65000
103 Van Lam IT 72000
104 Bich Phuong IT 78000
105 Quoc Tuan Sales 68000
Mỗi dòng chứa thông tin: ID, Tên, Phòng ban và Lương.
Ví dụ xử lý văn bản đơn giản
Đây là những tác vụ cơ bản nhất mà bạn có thể thực hiện với AWK.
1. In một cột cụ thể từ file văn bản:
Nếu bạn chỉ muốn xem danh sách tên của tất cả nhân viên (cột thứ hai và ba), bạn có thể dùng lệnh:
awk '{print $2, $3}' nhanvien.txt
Kết quả sẽ là:
Tuan Anh
Minh Hang
Van Lam
Bich Phuong
Quoc Tuan
2. Lọc dòng dựa trên một điều kiện nhất định:
Giả sử bạn muốn tìm tất cả nhân viên thuộc phòng “IT“. Bạn sẽ sử dụng cột thứ tư ($4) làm điều kiện trong phần pattern.
awk '$4 == "IT" {print $0}' nhanvien.txt
Lệnh này có nghĩa là: “Nếu giá trị của cột thứ tư bằng “IT”, hãy in toàn bộ dòng đó ($0)”. Kết quả:
103 Van Lam IT 72000
104 Bich Phuong IT 78000
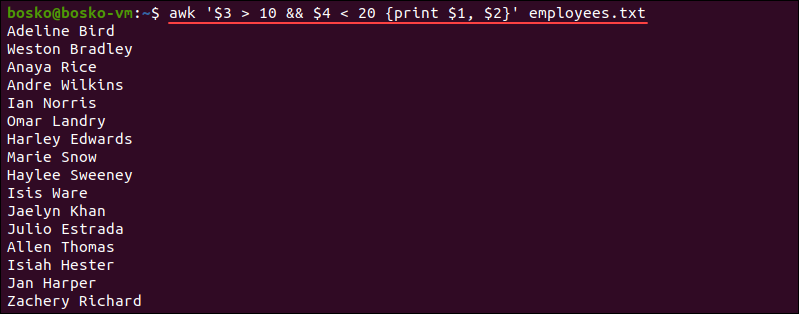
Bạn cũng có thể lọc theo điều kiện số. Ví dụ, tìm những nhân viên có mức lương cao hơn 70000:
awk '$5 > 70000 {print $2, $3, $5}' nhanvien.txt
Kết quả:
Van Lam 72000
Bich Phuong 78000
Ví dụ nâng cao với tính toán và định dạng
AWK không chỉ dừng lại ở việc trích xuất dữ liệu, nó còn có thể thực hiện các phép tính và định dạng đầu ra.
1. Tính tổng và trung bình giá trị trong một cột số:
Để tính tổng lương của tất cả nhân viên, bạn có thể tạo một biến (ví dụ tong_luong) và cộng dồn giá trị của cột thứ năm ($5) vào biến này trên mỗi dòng. Khối END là một pattern đặc biệt, nó chỉ thực thi sau khi tất cả các dòng đã được xử lý.
awk '{tong_luong += $5} END {print "Tong luong:", tong_luong}' nhanvien.txt
Kết quả:
Tong luong: 333000
Để tính lương trung bình, bạn chỉ cần lấy tổng lương chia cho số lượng dòng (sử dụng biến NR):
awk '{tong_luong += $5} END {print "Luong trung binh:", tong_luong / NR}' nhanvien.txt
Kết quả:
Luong trung binh: 66600
2. Định dạng lại dữ liệu đầu ra cho dễ đọc:
Thay vì dùng print, bạn có thể dùng hàm printf (tương tự như trong ngôn ngữ C) để kiểm soát định dạng đầu ra một cách chính xác. printf không tự động xuống dòng, vì vậy bạn cần thêm \n.
Ví dụ, in ra danh sách nhân viên phòng “Sales” với định dạng đẹp hơn:
awk '$4 == "Sales" {printf "Nhan vien: %-15s | Luong: %d\n", $2 " " $3, $5}' nhanvien.txt
Trong đó, %-15s có nghĩa là canh lề trái cho một chuỗi trong khoảng 15 ký tự, và %d là định dạng cho số nguyên. Kết quả sẽ rất ngay ngắn:
Nhan vien: Minh Hang | Luong: 65000
Nhan vien: Quoc Tuan | Luong: 68000
Những ví dụ này chỉ là bề nổi của những gì AWK có thể làm, nhưng chúng cho thấy khả năng xử lý dữ liệu mạnh mẽ và linh hoạt của công cụ này.
Các tùy chọn phổ biến và cách sử dụng hiệu quả
Để khai thác tối đa sức mạnh của AWK, bạn cần biết cách sử dụng các tùy chọn dòng lệnh và kết hợp nó với các công cụ khác trong hệ sinh thái Linux.
Các tùy chọn command line thường dùng
AWK cung cấp một số tùy chọn (flags) mạnh mẽ giúp bạn tùy chỉnh hành vi của nó ngay từ khi thực thi lệnh.
1. Tùy chọn -F để định nghĩa ký tự phân cách trường:
Mặc định, AWK sử dụng khoảng trắng (space hoặc tab) làm ký tự phân cách các cột (field separator). Tuy nhiên, trong thực tế, dữ liệu thường được phân cách bởi các ký tự khác như dấu phẩy (CSV), dấu hai chấm, hoặc dấu gạch đứng. Tùy chọn -F cho phép bạn chỉ định chính xác ký tự này.
Ví dụ, với một file data.csv có nội dung:
sanpham,soluong,dongia
Ao Thun,100,150000
Quan Jean,50,350000
Để xử lý file này, bạn cần chỉ định dấu phẩy là ký tự phân cách:
awk -F',' '{print "San pham:", $1, "| Don gia:", $3}' data.csv
Lệnh này sẽ hiểu và tách các cột một cách chính xác.
2. Tùy chọn -v để truyền biến vào trong AWK:
Đôi khi bạn cần sử dụng một giá trị từ bên ngoài (ví dụ, một biến trong shell script) vào bên trong chương trình AWK của mình. Tùy chọn -v (viết tắt của variable) cho phép bạn làm điều đó một cách dễ dàng.
Giả sử bạn có một biến shell phong_ban_can_tim="IT" và muốn dùng nó để lọc file nhanvien.txt:
phong_ban_can_tim="IT"
awk -v pb="$phong_ban_can_tim" '$4 == pb {print $0}' nhanvien.txt
Ở đây, -v pb="$phong_ban_can_tim" tạo ra một biến tên là pb bên trong AWK, có giá trị là “IT”. Sau đó, bạn có thể sử dụng biến pb này trong phần pattern của mình. Cách làm này giúp kịch bản của bạn trở nên linh hoạt và dễ tái sử dụng hơn.
Sử dụng lệnh AWK kết hợp với các công cụ khác
AWK trở nên mạnh mẽ hơn bội phần khi được sử dụng trong một chuỗi xử lý (pipeline) cùng với các công cụ dòng lệnh khác. Pipeline (|) cho phép bạn chuyển đầu ra của một lệnh này làm đầu vào cho lệnh tiếp theo.
1. Kết hợp với grep, sed, sort trong pipeline xử lý dữ liệu:
Đây là một kịch bản rất phổ biến trong quản trị hệ thống. Ví dụ, bạn muốn tìm tất cả các thông báo lỗi “Failed password” trong file log hệ thống, sau đó trích xuất địa chỉ IP và sắp xếp chúng để xem IP nào tấn công nhiều nhất.
grep "Failed password" /var/log/auth.log | awk '{print $(NF-3)}' | sort | uniq -c | sort -nr
Hãy phân tích chuỗi lệnh này:
grep "Failed password" ...: Lọc ra tất cả các dòng chứa chuỗi “Failed password”.| awk '{print $(NF-3)}': Đầu ra của grep được chuyển cho awk. awk sẽ in ra cột thứ 3 từ cuối lên (thường là địa chỉ IP trong các log này).| sort: Sắp xếp các địa chỉ IP theo thứ tự.| uniq -c: Đếm số lần xuất hiện của mỗi IP liên tiếp.| sort -nr: Sắp xếp kết quả theo số đếm giảm dần, giúp bạn thấy ngay IP nào xuất hiện nhiều nhất.
2. Ứng dụng trong shell script tự động hoá:
Trong một shell script, bạn có thể dùng AWK để phân tích đầu ra của các lệnh hệ thống. Ví dụ, bạn muốn viết một script cảnh báo nếu dung lượng ổ đĩa nào đó vượt quá 90%.
#!/bin/bash
df -h | awk 'NR>1 {sub(/%/, "", $5); if ($5 > 90) print "Canh bao: O dia", $1, "da su dung toi", $5 "%!"}'
Lệnh df -h liệt kê dung lượng các ổ đĩa. Đầu ra của nó được chuyển cho awk. AWK sẽ bỏ qua dòng tiêu đề (NR>1), loại bỏ ký tự % khỏi cột thứ năm, sau đó kiểm tra nếu giá trị sử dụng lớn hơn 90 thì in ra cảnh báo. Việc kết hợp này giúp bạn tạo ra các công cụ giám sát hệ thống đơn giản mà hiệu quả.
Áp dụng lệnh AWK trong xử lý và trích xuất dữ liệu từ tập tin văn bản
Với những kiến thức về cú pháp và các tùy chọn, giờ là lúc áp dụng AWK vào các bài toán thực tế: trích xuất thông tin có chọn lọc và tạo báo cáo tổng hợp từ các tập tin dữ liệu lớn.
Trích xuất dữ liệu theo điều kiện cụ thể
Một trong những ứng dụng phổ biến nhất của AWK là đóng vai trò như một bộ lọc thông minh, giúp bạn nhanh chóng tìm thấy những “viên ngọc” thông tin ẩn trong “biển” dữ liệu thô.
Hãy tưởng tượng bạn đang quản lý một máy chủ web và cần phân tích file access.log. File này chứa hàng triệu dòng ghi lại mọi yêu cầu truy cập. Nhiệm vụ của bạn là tìm ra tất cả các yêu cầu gây ra lỗi “404 Not Found” từ một dải địa chỉ IP cụ thể của công ty (ví dụ: 192.168.1.x).
awk '$9 == 404 && $1 ~ /^192\.168\.1\./ {print "Thoi gian:", $4, "| IP:", $1, "| Yeu cau:", $7}' access.log

Trong lệnh này:
$9 == 404: Đây là điều kiện đầu tiên, kiểm tra xem mã trạng thái (thường ở cột 9) có phải là 404 hay không.&&: Toán tử logic “VÀ”, yêu cầu cả hai điều kiện phải cùng đúng.$1 ~ /^192\.168\.1\./: Đây là điều kiện thứ hai. Toán tử ~ dùng để so khớp biểu thức chính quy (regular expression). Biểu thức này kiểm tra xem địa chỉ IP (cột 1) có bắt đầu bằng 192.168.1. hay không.{print ...}: Nếu cả hai điều kiện trên đều đúng, hành động in ra thông tin quan trọng như thời gian, IP và URL yêu cầu sẽ được thực hiện.
Bằng cách này, thay vì phải đọc thủ công hàng ngàn dòng log, bạn có thể có ngay kết quả mình cần chỉ trong vài giây.
Tổng hợp và báo cáo dữ liệu từ tập tin lớn
Sức mạnh của AWK không chỉ dừng lại ở việc lọc dữ liệu. Nó còn là một công cụ tuyệt vời để tổng hợp, thống kê và tạo ra các báo cáo nhanh chóng từ những tập tin dữ liệu khổng lồ mà không cần đến các công cụ phức tạp như cơ sở dữ liệu hay bảng tính.
Giả sử bạn có một file sales_2023.csv chứa dữ liệu bán hàng của cả năm, với hàng triệu dòng theo định dạng:
Ngay,KhuVuc,MaSanPham,SoLuong,DoanhThu
2023-01-15,Mien Bac,SP001,5,5000000
2023-01-16,Mien Nam,SP003,2,8000000
...
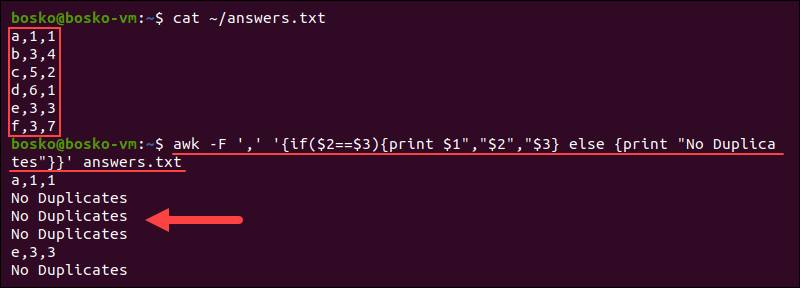
Yêu cầu của bạn là tạo một báo cáo tổng hợp doanh thu theo từng khu vực. Đây là lúc mảng kết hợp (associative array) của AWK tỏa sáng. Mảng kết hợp cho phép bạn dùng chuỗi làm chỉ số (index).
awk -F',' 'NR > 1 {doanhthu_theo_khuvuc[$2] += $5} END {printf "%-15s | %s\n", "Khu Vuc", "Tong Doanh Thu"; for (khuvuc in doanhthu_theo_khuvuc) {printf "%-15s | %'d\n", khuvuc, doanhthu_theo_khuvuc[khuvuc]}}' sales_2023.csv

Hãy cùng phân tích lệnh phức tạp này:
-F',': Chỉ định dấu phẩy là ký tự phân cách.NR > 1: Bỏ qua dòng tiêu đề đầu tiên.doanhthu_theo_khuvuc[$2] += $5: Đây là phần cốt lõi. Nó tạo một mảng tên là doanhthu_theo_khuvuc. Với mỗi dòng, nó lấy tên khu vực (cột 2) làm chỉ số của mảng và cộng dồn doanh thu (cột 5) vào giá trị tương ứng. Ví dụ, doanhthu_theo_khuvuc["Mien Bac"] sẽ tích lũy tổng doanh thu của Miền Bắc.END {...}: Sau khi xử lý hết tất cả các dòng, khối END sẽ được thực thi.for (khuvuc in doanhthu_theo_khuvuc) {...}: Vòng lặp này duyệt qua tất cả các chỉ số (tên khu vực) đã được lưu trong mảng.printf ...: In ra kết quả dưới dạng bảng được định dạng gọn gàng. %d với dấu `’` (%'d) là một tính năng của gawk giúp định dạng số hàng ngàn.
Chỉ với một dòng lệnh, AWK đã giúp bạn xử lý một tập tin lớn và tạo ra một báo cáo tổng hợp giá trị, một công việc có thể mất rất nhiều thời gian nếu làm thủ công.
Lời khuyên và mẹo khi sử dụng lệnh AWK
Để sử dụng AWK một cách hiệu quả và chuyên nghiệp, bạn nên ghi nhớ một vài lời khuyên và mẹo nhỏ sau. Chúng sẽ giúp bạn tránh được những lỗi không đáng có và viết ra những kịch bản mạnh mẽ, dễ bảo trì hơn.
Luôn kiểm thử câu lệnh trên một phần dữ liệu nhỏ trước: Khi làm việc với các tập tin lớn (hàng GB), một câu lệnh AWK viết sai có thể chạy rất lâu hoặc tạo ra kết quả không mong muốn. Một thói quen tốt là hãy trích một phần nhỏ của file dữ liệu (ví dụ, 100 dòng đầu tiên) để thử nghiệm câu lệnh của bạn. Lệnh head là công cụ hoàn hảo cho việc này: head -n 100 large_file.log | awk '...'

Dùng comment để ghi chú các đoạn script AWK phức tạp: Giống như bất kỳ ngôn ngữ lập trình nào, một kịch bản AWK phức tạp có thể trở nên khó hiểu sau một thời gian. Hãy sử dụng ký tự # để thêm các ghi chú (comment) vào trong mã của bạn. Điều này không chỉ giúp bạn trong tương lai mà còn giúp đồng nghiệp dễ dàng hiểu và bảo trì script.
Tận dụng các hàm có sẵn để tránh viết lại những gì đã có: AWK cung cấp rất nhiều hàm nội tại mạnh mẽ cho việc xử lý chuỗi (sub, gsub, split, index), tính toán (sin, cos, sqrt, rand) và nhiều hơn nữa. Trước khi bạn định viết một logic phức tạp, hãy kiểm tra tài liệu của AWK để xem liệu đã có hàm nào giải quyết vấn đề đó chưa. Việc này giúp mã của bạn ngắn gọn và hiệu quả hơn.
Tránh xử lý dữ liệu quá lớn nếu không tối ưu: Mặc dù AWK rất nhanh, việc đọc toàn bộ một tập tin vài chục GB vào bộ nhớ (ví dụ, để xây dựng một mảng kết hợp khổng lồ) có thể làm cạn kiệt tài nguyên hệ thống. Trong những trường hợp này, hãy cân nhắc các phương pháp xử lý theo luồng (stream processing) hoặc kết hợp với các công cụ khác như sort và uniq để giảm tải cho AWK.
Sử dụng phiên bản AWK phù hợp (gawk, mawk) tùy môi trường: Trên hầu hết các hệ thống Linux hiện đại, awk thực chất là một liên kết tượng trưng đến gawk (GNU AWK). gawk là phiên bản mạnh mẽ nhất với nhiều tính năng mở rộng (như xử lý mạng, định dạng số %'d). Tuy nhiên, cũng có các phiên bản khác như mawk, được biết đến với tốc độ cực nhanh nhưng ít tính năng hơn. Hãy nhận biết phiên bản bạn đang dùng để tận dụng các tính năng của nó hoặc đảm bảo tính tương thích khi chuyển script sang môi trường khác.
Common Issues/Troubleshooting
Khi mới bắt đầu, việc gặp lỗi là không thể tránh khỏi. Dưới đây là một số vấn đề thường gặp và cách khắc phục khi làm việc với AWK.
Lỗi cú pháp phổ biến khi viết lệnh AWK
Lỗi cú pháp là loại lỗi dễ gặp nhất, thường xuất phát từ việc gõ nhầm hoặc quên một ký tự nào đó.
- Quên dấu ngoặc nhọn
{} hoặc dấu nháy đơn '': Toàn bộ chương trình AWK phải được bao bọc bởi dấu nháy đơn ''. Khối action phải nằm trong dấu ngoặc nhọn {}. Lệnh awk '$1 == "ERROR" print $0' sẽ thất bại vì thiếu {} quanh print $0.
- Nhầm lẫn giữa toán tử gán
= và toán tử so sánh ==: Đây là lỗi kinh điển trong nhiều ngôn ngữ lập trình. Để so sánh một giá trị, bạn phải dùng ==. Ví dụ, awk '$1 = "ERROR"' sẽ cố gắng gán giá trị “ERROR” cho cột $1 (và luôn trả về true), thay vì so sánh nó. Lệnh đúng phải là awk '$1 == "ERROR"'.
- Sử dụng biến chuỗi mà không có dấu ngoặc kép
"": Khi so sánh một trường với một chuỗi ký tự, chuỗi đó phải được đặt trong dấu ngoặc kép. Lệnh awk '$4 == IT' sẽ bị lỗi vì AWK sẽ hiểu IT là một biến (chưa được định nghĩa) chứ không phải chuỗi “IT”. Lệnh đúng là awk '$4 == "IT"'.
Vấn đề về encoding và format tập tin đầu vào
Đôi khi câu lệnh của bạn đúng hoàn toàn về mặt cú pháp nhưng kết quả lại không như ý. Nguyên nhân có thể đến từ chính tập tin đầu vào.
- Ký tự phân cách không nhất quán: File dữ liệu của bạn có thể trông ngay ngắn, nhưng đôi khi nó lẫn lộn giữa tab và nhiều khoảng trắng. Điều này làm cho việc phân tách cột mặc định của AWK trở nên sai lệch. Trong trường hợp này, bạn nên tiền xử lý file để chuẩn hóa ký tự phân cách hoặc sử dụng biểu thức chính quy phức tạp hơn với tùy chọn
-F.
- Vấn đề về mã hóa ký tự (Encoding): Nếu bạn làm việc với dữ liệu chứa tiếng Việt hoặc các ký tự đặc biệt khác, hãy chắc chắn rằng file được lưu ở định dạng UTF-8 và terminal của bạn cũng đang sử dụng UTF-8. Một file có mã hóa không tương thích có thể khiến AWK không nhận diện được các ký tự và xử lý sai.
- Định dạng dòng của Windows (CRLF) vs. Unix (LF): Các file văn bản tạo trên Windows thường kết thúc mỗi dòng bằng hai ký tự
\r\n (CRLF), trong khi Unix chỉ dùng \n (LF). Ký tự \r thừa này có thể gây ra lỗi lạ khi xử lý bằng AWK trên Linux. Ví dụ, khi so sánh $NF == "expected_value", phép so sánh có thể thất bại vì giá trị thực sự của $NF là "expected_value\r". Bạn có thể dùng các công cụ như dos2unix để chuyển đổi định dạng file trước khi xử lý.
Best Practices
Để nâng cao kỹ năng sử dụng AWK từ mức cơ bản lên chuyên nghiệp, việc tuân thủ các quy tắc thực hành tốt nhất (best practices) là rất quan trọng. Điều này không chỉ giúp bạn viết code hiệu quả hơn mà còn đảm bảo các kịch bản của bạn dễ đọc, dễ bảo trì và dễ mở rộng.
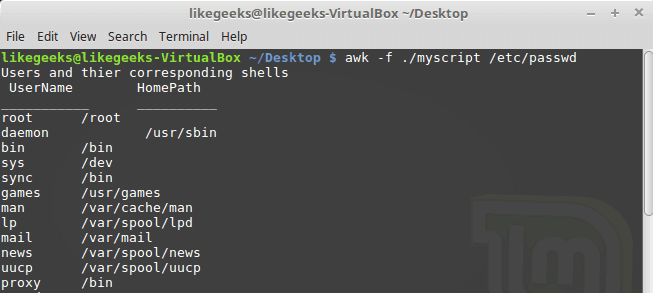
Viết script AWK rõ ràng, dễ bảo trì: Khi một kịch bản AWK trở nên dài hơn vài dòng, hãy cân nhắc viết nó vào một file riêng biệt (ví dụ: my_script.awk) và thực thi bằng lệnh awk -f my_script.awk data.txt. Trong file script, hãy sử dụng thụt đầu dòng, khoảng trắng và comment (#) để làm cho mã của bạn có cấu trúc và dễ hiểu. Đặt tên biến một cách có ý nghĩa thay vì các tên ngắn gọn như x, y, z.
Sử dụng biến để tăng tính tái sử dụng: Thay vì “hard-code” các giá trị trực tiếp vào trong script, hãy sử dụng biến. Đặc biệt khi kết hợp với tùy chọn -v của dòng lệnh, bạn có thể tạo ra các kịch bản linh hoạt. Ví dụ, thay vì viết awk '$5 > 5000', hãy viết awk -v threshold=5000 '$5 > threshold', cho phép bạn dễ dàng thay đổi ngưỡng mà không cần sửa đổi mã nguồn script.
Kết hợp AWK với shell script để mở rộng chức năng: AWK rất mạnh trong việc xử lý văn bản, nhưng nó có giới hạn. Đối với các tác vụ phức tạp hơn như tương tác với hệ thống file, thực thi các lệnh khác, hoặc xử lý logic điều kiện phức tạp, hãy bao bọc lệnh AWK của bạn trong một shell script. Shell script có thể chuẩn bị dữ liệu đầu vào, gọi AWK để xử lý, sau đó lấy kết quả của AWK để thực hiện các bước tiếp theo.
Không dùng AWK cho các tác vụ cực kỳ phức tạp hoặc xử lý dữ liệu lớn vượt khả năng: Hãy biết khi nào nên dừng lại. AWK là công cụ tuyệt vời cho các tác vụ xử lý văn bản từ đơn giản đến trung bình. Tuy nhiên, nếu bạn thấy mình đang phải viết hàng trăm dòng mã AWK để xử lý các cấu trúc dữ liệu lồng nhau phức tạp hoặc thao tác với các file dữ liệu quá lớn gây quá tải bộ nhớ, đó là dấu hiệu bạn nên chuyển sang một ngôn ngữ lập trình mạnh mẽ hơn như Python (với thư viện Pandas) hoặc Perl. Sử dụng đúng công cụ cho đúng công việc là một kỹ năng quan trọng của một kỹ sư hệ thống giỏi.
Conclusion
Chúng ta đã cùng nhau đi qua một hành trình chi tiết để khám phá lệnh AWK, từ những khái niệm nền tảng nhất đến các ứng dụng thực tiễn và mẹo sử dụng nâng cao. Có thể thấy rằng, AWK không chỉ là một lệnh đơn thuần, mà là một ngôn ngữ xử lý dữ liệu thu nhỏ, một công cụ quyền năng và không thể thiếu trong “bộ đồ nghề” của bất kỳ ai làm việc với hệ điều hành Linux. Ưu điểm nổi bật của nó nằm ở sự linh hoạt trong việc xử lý dữ liệu theo cột, khả năng kết hợp các điều kiện lọc với hành động xử lý, và hiệu suất ấn tượng khi làm việc với các tập tin văn bản lớn.
Để thực sự làm chủ được AWK, không có con đường nào tốt hơn việc thực hành thường xuyên. Lý thuyết chỉ là nền tảng, chính việc áp dụng vào giải quyết các vấn đề thực tế trong công việc và các dự án cá nhân mới giúp bạn biến kiến thức thành kỹ năng. Tôi khuyến khích bạn hãy bắt đầu ngay hôm nay. Hãy thử lấy một file log hệ thống, một file CSV dữ liệu, hay đơn giản là đầu ra của một lệnh bất kỳ và thử “nghịch” với AWK. Hãy tự đặt ra các câu hỏi như: “Làm sao để trích xuất thông tin này?”, “Làm thế nào để tính toán và tổng hợp dữ liệu kia?”.
Hành trình học hỏi là vô tận. Nếu bạn muốn tìm hiểu sâu hơn, có rất nhiều tài liệu tuyệt vời như sách “The AWK Programming Language” của chính các tác giả, các trang hướng dẫn (man pages) và vô số bài viết, khóa học trực tuyến. Chúc bạn thành công trên con đường chinh phục dòng lệnh và biến những dòng dữ liệu khô khan thành những thông tin hữu ích!

