Bạn đã bao giờ cảm thấy choáng ngợp trước hàng ngàn dòng log khi cần tìm một thông tin cụ thể trên hệ thống Linux chưa? Việc tìm kiếm và lọc dữ liệu văn bản là một kỹ năng thiết yếu đối với bất kỳ ai làm việc với Linux, từ quản trị viên hệ thống đến các nhà phát triển. Trong kho tàng công cụ của Linux, các lệnh như grep, fgrep, và đặc biệt là egrep đóng vai trò như những trợ thủ đắc lực. Tuy nhiên, nhiều người dùng thường bối rối, không phân biệt rõ khi nào nên dùng lệnh nào, đặc biệt là với egrep. Bài viết này được tạo ra để giải quyết chính vấn đề đó. Chúng ta sẽ cùng nhau khám phá lệnh egrep là gì, từ cú pháp cơ bản đến cách vận dụng sức mạnh của biểu thức chính quy mở rộng (extended regular expressions) qua các ví dụ thực tế. Hãy bắt đầu hành trình làm chủ công cụ tìm kiếm mạnh mẽ này nhé!
Giới thiệu về lệnh egrep trong Linux
Trong môi trường Linux, việc xử lý các tệp văn bản và dữ liệu dạng chuỗi là công việc diễn ra hàng ngày. Từ việc kiểm tra tệp log hệ thống, phân tích dữ liệu, đến tìm kiếm một đoạn mã cụ thể, chúng ta luôn cần đến các công cụ tìm kiếm mạnh mẽ và linh hoạt. Linux cung cấp một họ các lệnh grep (Global Regular Expression Print) để thực hiện nhiệm vụ này, và egrep là một thành viên nổi bật trong số đó.
Vấn đề mà nhiều người dùng, kể cả những người đã có kinh nghiệm, thường gặp phải là sự nhầm lẫn giữa grep, egrep, và fgrep. Họ không chắc chắn egrep có gì khác biệt, tại sao nó lại tồn tại như một lệnh riêng và khi nào thì nên sử dụng nó. Sự mơ hồ này dẫn đến việc không tận dụng được hết tiềm năng của công cụ, làm giảm hiệu quả công việc và đôi khi gây ra lỗi cú pháp không mong muốn.
Bài viết này chính là giải pháp toàn diện cho bạn. Chúng tôi sẽ đi sâu vào việc giải thích rõ ràng về lệnh egrep, chức năng cốt lõi của nó là hỗ trợ các biểu thức chính quy mở rộng (Extended Regular Expressions – ERE). Bạn sẽ hiểu được egrep không chỉ là một phiên bản khác của grep, mà là một công cụ chuyên dụng cho các mẫu tìm kiếm phức tạp và linh hoạt hơn.
Bash là gì để hiểu thêm về shell trong Linux sẽ giúp bạn phối hợp lệnh dễ dàng hơn.
Để giúp bạn nắm vững kiến thức, bài viết sẽ được cấu trúc một cách logic và dễ theo dõi. Chúng ta sẽ bắt đầu với cú pháp cơ bản và các tham số thông dụng nhất của egrep. Sau đó, chúng ta sẽ đi qua hàng loạt ví dụ minh họa thực tế, từ đơn giản đến phức tạp, giúp bạn hình dung rõ cách áp dụng lệnh trong công việc hàng ngày. Tiếp theo, bài viết sẽ so sánh chi tiết egrep với grep và fgrep để bạn biết chính xác khi nào nên chọn công cụ nào. Cuối cùng, chúng tôi sẽ chia sẻ những mẹo, lưu ý và các phương pháp hay nhất để bạn sử dụng egrep một cách hiệu quả và chuyên nghiệp nhất. Hãy cùng khám phá sức mạnh của egrep nhé!
Cú pháp cơ bản của lệnh egrep
Để bắt đầu sử dụng egrep, điều đầu tiên bạn cần nắm vững chính là cú pháp của nó. Về cơ bản, egrep hoạt động tương tự như grep, nhưng nó được tối ưu hóa để diễn giải các biểu thức chính quy mở rộng, giúp bạn xây dựng các mẫu tìm kiếm phức tạp một cách gọn gàng hơn. Việc hiểu rõ cấu trúc lệnh và các tham số đi kèm sẽ là nền tảng vững chắc để bạn khai thác tối đa sức mạnh của nó.
Cấu trúc và các tham số phổ biến
Cú pháp chuẩn của lệnh egrep rất đơn giản và có thể được mô tả như sau:
egrep [tùy chọn] 'biểu_thức_chính_quy_mở_rộng' tên_tập_tin
Hãy cùng phân tích từng thành phần trong cú pháp này:
- [tùy chọn] (options): Đây là các cờ (flags) bạn có thể thêm vào để thay đổi hành vi mặc định của lệnh. Mỗi tùy chọn mang lại một chức năng hữu ích, giúp việc tìm kiếm trở nên linh hoạt hơn.
- ‘biểu_thức_chính_quy_mở_rộng’ (pattern): Đây chính là trái tim của lệnh
egrep. Nó là một chuỗi mẫu mà bạn muốn tìm kiếm. Sức mạnh của egrep nằm ở việc nó hỗ trợ các ký tự đặc biệt của biểu thức chính quy mở rộng (ERE) như +, ?, |, và () mà không cần ký tự thoát \ như trong grep cơ bản.
- tên_tập_tin (file): Đây là tên của một hoặc nhiều tập tin mà bạn muốn thực hiện tìm kiếm. Nếu không có tập tin nào được chỉ định,
egrep sẽ đọc từ đầu vào chuẩn (standard input), thường là dữ liệu được chuyển từ một lệnh khác qua pipe (|).
Dưới đây là một số tham số (tùy chọn) phổ biến và cực kỳ hữu ích khi làm việc với egrep:
- -i (ignore case): Bỏ qua sự phân biệt chữ hoa, chữ thường khi tìm kiếm. Ví dụ, khi tìm
Error với tùy chọn -i, cả error, ERROR, hay ErRoR đều sẽ được tìm thấy.
- -v (invert match): Đảo ngược kết quả tìm kiếm. Thay vì hiển thị các dòng khớp với mẫu, nó sẽ hiển thị tất cả các dòng KHÔNG khớp.
- -c (count): Đếm số lượng dòng khớp với mẫu thay vì hiển thị nội dung của chúng. Tùy chọn này rất hữu ích khi bạn chỉ cần thống kê.
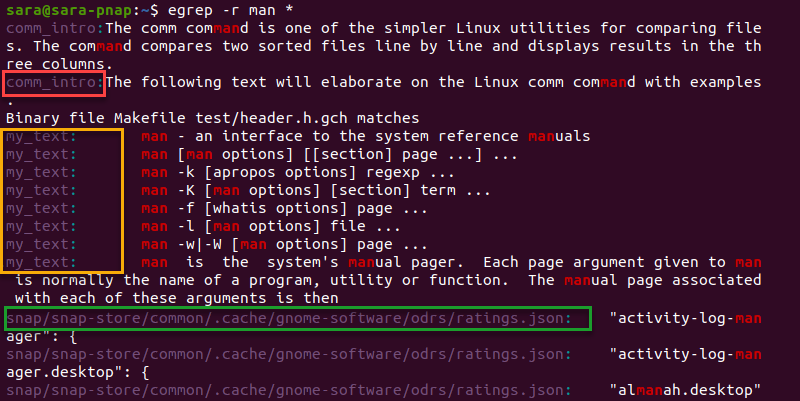
- -r (recursive): Tìm kiếm đệ quy trong tất cả các tệp và thư mục con của một thư mục được chỉ định. Đây là cứu cánh khi bạn không biết chính xác tệp cần tìm nằm ở đâu.
- -l (files with matches): Chỉ hiển thị tên của các tập tin có chứa ít nhất một dòng khớp với mẫu.
- -n (line number): Hiển thị số dòng của mỗi kết quả tìm thấy.
- –color=auto: Tự động tô màu cho chuỗi ký tự khớp với mẫu, giúp kết quả trở nên trực quan và dễ đọc hơn rất nhiều.
Ví dụ minh họa cú pháp đơn giản
Lý thuyết sẽ dễ hiểu hơn rất nhiều khi đi kèm với ví dụ thực tế. Giả sử chúng ta có một tệp tin tên là vi_du.txt với nội dung sau:
Dòng 1: Chào mừng đến với Linux.
Dòng 2: linux là hệ điều hành mạnh mẽ.
Dòng 3: Học egrep rất thú vị.
Dòng 4: Bạn có thể tìm kiếm email như contact@example.com.
Dòng 5: Hoặc tìm số điện thoại 0987654321.
Dòng 6: Chào bạn, chào thế giới!
1. Tìm một chuỗi đơn giản:
Để tìm tất cả các dòng có chứa từ “Linux“, bạn chỉ cần chạy lệnh:
egrep 'Linux' vi_du.txt
Kết quả sẽ là:
Dòng 1: Chào mừng đến với Linux.
2. Tìm kiếm không phân biệt hoa thường:
Nếu bạn muốn tìm cả “Linux” và “linux”, hãy sử dụng tùy chọn -i:
egrep -i 'linux' vi_du.txt
Kết quả sẽ bao gồm cả hai dòng:
Dòng 1: Chào mừng đến với Linux.
Dòng 2: linux là hệ điều hành mạnh mẽ.
3. Kết hợp nhiều điều kiện tìm kiếm:
Đây là lúc sức mạnh của biểu thức chính quy mở rộng trong egrep tỏa sáng. Giả sử bạn muốn tìm các dòng chứa từ “Chào” HOẶC từ “Học”. Bạn có thể sử dụng toán tử | (OR) một cách trực tiếp.
egrep 'Chào|Học' vi_du.txt
Kết quả sẽ là:
Dòng 1: Chào mừng đến với Linux.
Dòng 3: Học egrep rất thú vị.
Dòng 6: Chào bạn, chào thế giới!
Trong grep là gì cơ bản, bạn sẽ phải viết grep 'Chào\|Học' với ký tự thoát \, điều này làm cho cú pháp trở nên rườm rà hơn. Với egrep, mọi thứ trở nên gọn gàng và dễ đọc hơn rất nhiều. Đây chính là ưu điểm lớn nhất khi bạn bắt đầu làm việc với các mẫu tìm kiếm phức tạp.
Ví dụ minh họa thực tiễn sử dụng lệnh egrep
Sau khi đã nắm vững cú pháp cơ bản, hãy cùng đi vào các ví dụ thực tiễn hơn để thấy egrep thực sự hữu ích như thế nào trong công việc hàng ngày của một người làm việc với Linux. Các ví dụ này sẽ tập trung vào hai tác vụ phổ biến: phân tích tệp log và lọc dữ liệu người dùng.
Tìm kiếm dữ liệu trong tập tin log
Tệp log là nguồn thông tin quan trọng để theo dõi hoạt động và gỡ lỗi hệ thống. Tuy nhiên, chúng thường chứa một lượng dữ liệu khổng lồ, khiến việc tìm kiếm thủ công trở nên bất khả thi. egrep với khả năng xử lý biểu thức chính quy mở rộng là công cụ hoàn hảo cho nhiệm vụ này.
Giả sử chúng ta có một tệp log máy chủ web tên access.log và bạn muốn tìm tất cả các dòng ghi lại lỗi (error) hoặc cảnh báo (warning).
Ví dụ 1: Tìm các dòng chứa “error” hoặc “warning”
Bạn có thể sử dụng toán tử | để kết hợp hai điều kiện tìm kiếm. Để kết quả dễ nhìn hơn, chúng ta sẽ bật tính năng tô màu.
egrep --color=auto 'error|warning' access.log
Lệnh này sẽ quét toàn bộ tệp access.log và hiển thị tất cả các dòng có chứa từ “error” hoặc “warning”, đồng thời tô màu các từ khóa này để bạn dễ dàng nhận biết. Việc này nhanh hơn rất nhiều so với việc chạy hai lệnh grep riêng biệt.
Ví dụ 2: Tìm các yêu cầu từ một dải địa chỉ IP cụ thể
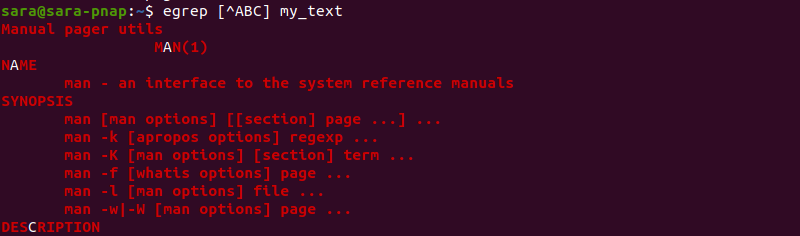
Một nhiệm vụ phổ biến khác là phân tích lưu lượng truy cập từ một nhóm người dùng hoặc một mạng nội bộ. Giả sử bạn muốn tìm tất cả các yêu cầu đến từ dải IP 192.168.1.x. Biểu thức chính quy cho việc này sẽ là tìm các chuỗi bắt đầu bằng 192.168.1.. Tuy nhiên, chỉ cần một mẫu đơn giản hơn cũng có thể hoạt động hiệu quả.
Bạn có thể sử dụng dấu ^ để chỉ định mẫu phải ở đầu dòng, nhưng trong file log, IP thường nằm ở đầu. Hãy thử tìm các IP bắt đầu bằng 192.168. và kết thúc bằng một hoặc nhiều chữ số.
egrep '^192\.168\.1\.[0-9]+' access.log
Trong ví dụ này:
^ đảm bảo mẫu nằm ở đầu dòng.192\.168\.1\. tìm kiếm chuỗi ký tự cố định. Dấu . cần được thoát bằng \ vì nó là một ký tự đặc biệt trong regex (đại diện cho một ký tự bất kỳ).[0-9]+ khớp với một hoặc nhiều chữ số (từ 0 đến 9). Dấu + (khớp một hoặc nhiều lần) là một phần của biểu thức chính quy mở rộng mà egrep hỗ trợ trực tiếp.
Sử dụng egrep để lọc danh sách người dùng, địa chỉ email
egrep cũng là một công cụ tuyệt vời để xử lý các tệp chứa dữ liệu có cấu trúc, như danh sách người dùng hoặc tệp CSV. Khả năng khớp với các mẫu phức tạp giúp bạn trích xuất thông tin một cách chính xác.
Ví dụ 3: Lọc các địa chỉ email hợp lệ
Giả sử bạn có một tệp contacts.txt chứa nhiều loại thông tin khác nhau và bạn chỉ muốn trích xuất các dòng có chứa địa chỉ email. Một biểu thức chính quy đơn giản để nhận dạng email có thể được viết như sau:
egrep '[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}' contacts.txt
Hãy phân tích biểu thức này:
[a-zA-Z0-9._%+-]+: Khớp với phần tên người dùng của email, bao gồm chữ cái, số, và các ký tự đặc biệt cho phép. Dấu + có nghĩa là các ký tự này phải xuất hiện ít nhất một lần.@: Khớp với ký tự @ cố định.[a-zA-Z0-9.-]+: Khớp với phần tên miền, bao gồm chữ cái, số, dấu chấm và dấu gạch ngang.\.: Khớp với dấu chấm phân tách tên miền và phần mở rộng (ví dụ: .com).[a-zA-Z]{2,}: Khớp với phần mở rộng của tên miền (như com, net, org), yêu cầu ít nhất hai chữ cái.

Lệnh này sẽ lọc và chỉ hiển thị những dòng chứa chuỗi trông giống một địa chỉ email, giúp bạn nhanh chóng thu thập dữ liệu cần thiết.
Ví dụ 4: Lọc người dùng hệ thống có shell là bash
Trong Linux, thông tin người dùng thường được lưu trong tệp /etc/passwd. Mỗi dòng có một định dạng cụ thể, và trường cuối cùng chỉ định shell đăng nhập mặc định của người dùng. Nếu bạn muốn tìm tất cả người dùng đang sử dụng /bin/bash làm shell, bạn có thể dùng egrep.
egrep '/bin/bash$' /etc/passwd
Ở đây, ký tự $ là một ký tự đặc biệt trong regex, nó chỉ định rằng mẫu /bin/bash phải xuất hiện ở cuối dòng. Điều này đảm bảo rằng chúng ta chỉ khớp với những người dùng có shell chính xác là /bin/bash, chứ không phải những người dùng có tên chứa chuỗi này. Kết quả sẽ là danh sách các tài khoản người dùng thực sự trên hệ thống. Bạn có thể tìm hiểu thêm về Bash là gì để phối hợp tốt hơn với shell và các lệnh Linux.
Ứng dụng egrep trong tìm kiếm văn bản với biểu thức chính quy
Sức mạnh thực sự của egrep không nằm ở việc tìm kiếm chuỗi văn bản cố định, mà ở khả năng diễn giải các biểu thức chính quy mở rộng (Extended Regular Expressions – ERE). Đây là một “ngôn ngữ” mini giúp bạn định nghĩa các mẫu tìm kiếm cực kỳ linh hoạt và mạnh mẽ. Hiểu về biểu thức chính quy sẽ mở ra một thế giới hoàn toàn mới trong việc xử lý văn bản trên Linux.
Tổng quan về biểu thức chính quy trong Linux
Biểu thức chính quy (thường được viết tắt là “regex” hoặc “regexp”) là một chuỗi ký tự đặc biệt dùng để định nghĩa một mẫu tìm kiếm. Nó không phải là một chuỗi văn bản thông thường, mà là một tập hợp các quy tắc để khớp với các chuỗi khác. Ví dụ, thay vì tìm chính xác từ “apple”, bạn có thể tạo một regex để tìm bất kỳ từ nào bắt đầu bằng “a” và kết thúc bằng “e”.
Trong thế giới Linux, có hai loại biểu thức chính quy chính:
- Biểu thức chính quy cơ bản (Basic Regular Expressions – BRE): Đây là loại được sử dụng bởi lệnh
grep truyền thống. Trong BRE, các ký tự đặc biệt như ?, +, {}, |, (), nếu muốn có ý nghĩa đặc biệt của chúng, phải được “thoát” bằng một dấu gạch chéo ngược (\). Ví dụ: grep 'a\+b' để tìm chuỗi có một hoặc nhiều chữ ‘a’ theo sau bởi chữ ‘b’.
- Biểu thức chính quy mở rộng (Extended Regular Expressions – ERE): Đây là loại được
egrep hỗ trợ. Trong ERE, các ký tự đặc biệt nói trên có thể được sử dụng trực tiếp mà không cần dấu thoát. Điều này làm cho cú pháp trở nên gọn gàng, trực quan và dễ đọc hơn rất nhiều. Ví dụ: egrep 'a+b'.
Chính vì sự tiện lợi và dễ đọc này mà egrep (hoặc grep -E) trở thành lựa chọn ưa thích của nhiều người khi cần xây dựng các mẫu tìm kiếm phức tạp. Bạn không cần phải nhớ khi nào cần thêm \ và khi nào không, giúp giảm thiểu lỗi và tăng tốc độ làm việc. Nếu bạn muốn xem thêm về Linux là gì, đây là nguồn kiến thức nền tảng rất bổ ích.

Các biểu thức chính quy thường dùng với egrep
Để giúp bạn bắt đầu, dưới đây là một số ký tự và cấu trúc regex mở rộng phổ biến nhất mà bạn có thể sử dụng ngay với egrep. Hãy tưởng tượng chúng là những khối lego, bạn có thể kết hợp chúng lại để xây dựng bất kỳ mẫu tìm kiếm nào bạn muốn.
| (Toán tử OR – Hoặc): Cho phép bạn tìm kiếm nhiều chuỗi cùng một lúc.
- Ví dụ:
egrep 'apple|orange' fruits.txt sẽ tìm các dòng chứa “apple” hoặc “orange”.
+ (Quantifier – Một hoặc nhiều lần): Khớp với ký tự hoặc nhóm đứng trước nó xuất hiện một hoặc nhiều lần.
- Ví dụ:
egrep 'go+d' words.txt sẽ khớp với “god”, “good”, “goood”, v.v.
? (Quantifier – Không hoặc một lần): Khớp với ký tự hoặc nhóm đứng trước nó xuất hiện không hoặc một lần.
- Ví dụ:
egrep 'colou?r' text.txt sẽ khớp với cả “color” (kiểu Mỹ) và “colour” (kiểu Anh).
() (Grouping – Nhóm): Dùng để nhóm các phần của biểu thức lại với nhau. Điều này rất hữu ích khi kết hợp với các toán tử khác như | hoặc các bộ định lượng.
- Ví dụ:
egrep '(ab)+c' data.txt sẽ khớp với “abc”, “ababc”, “abababc”, nhưng không khớp với “ac” hay “bc”. Nó yêu cầu nhóm “ab” phải xuất hiện ít nhất một lần.
- Ví dụ khác:
egrep 'Bui (Manh|Minh) Duc' names.txt sẽ tìm “Bui Manh Duc” hoặc “Bui Minh Duc”. Đây liên quan mật thiết đến Ram là gì trong việc xử lý bộ nhớ khi chạy Linux.
. (Ký tự đại diện): Khớp với bất kỳ một ký tự đơn lẻ nào (ngoại trừ ký tự xuống dòng).
- Ví dụ:
egrep 'h.t' words.txt sẽ khớp với “hat”, “hot”, “hit”.
[] (Bộ ký tự): Khớp với bất kỳ ký tự nào bên trong dấu ngoặc vuông.
- Ví dụ:
egrep 'h[oa]t' words.txt sẽ chỉ khớp với “hot” và “hat”, không khớp với “hit”.
Bạn cũng có thể định nghĩa một khoảng ký tự, ví dụ [0-9] để khớp với một chữ số bất kỳ, hoặc [a-z] để khớp với một chữ cái thường bất kỳ.
{} (Quantifier – Số lần lặp cụ thể): Cho phép bạn chỉ định chính xác số lần một ký tự hoặc nhóm lặp lại.
- Ví dụ:
egrep 'a{3}' text.txt sẽ tìm các dòng có chứa chính xác ba chữ “a” liền nhau (“aaa”).
- Ví dụ:
egrep '[0-9]{10}' contacts.txt có thể dùng để tìm các chuỗi có 10 chữ số, giống như một số điện thoại.
Bằng cách kết hợp các thành phần này, bạn có thể tạo ra các mẫu tìm kiếm vô cùng chính xác để trích xuất đúng thông tin mình cần từ bất kỳ tệp văn bản nào.
So sánh egrep với grep và fgrep
Khi làm việc trong môi trường dòng lệnh của Linux, bạn sẽ thấy không chỉ có egrep mà còn có grep và fgrep. Cả ba đều là công cụ tìm kiếm văn bản, nhưng chúng có những điểm khác biệt quan trọng về chức năng và hiệu suất. Hiểu rõ sự khác biệt này sẽ giúp bạn chọn đúng công cụ cho từng tác vụ cụ thể, tối ưu hóa cả thời gian viết lệnh và tốc độ thực thi.
Điểm giống và khác nhau giữa egrep và grep
Về cơ bản, egrep có thể được coi là một phiên bản mở rộng của grep. Trong hầu hết các hệ thống Linux hiện đại, lệnh egrep thực chất là một lối tắt (alias) cho lệnh grep -E. Điều này có nghĩa là chạy egrep hoàn toàn tương đương với việc chạy grep với tùy chọn -E (Extended regex).
Điểm giống nhau:
- Cả hai đều được sử dụng để tìm kiếm các mẫu văn bản trong tệp hoặc từ đầu vào chuẩn.
- Chúng chia sẻ một bộ lớn các tùy chọn dòng lệnh chung như
-i, -v, -c, -r, -n, --color, v.v.
- Mục tiêu cuối cùng của cả hai là lọc và hiển thị các dòng khớp với một mẫu cho trước.
Điểm khác biệt cốt lõi: Khả năng xử lý biểu thức chính quy
Đây là điểm khác biệt lớn nhất và quan trọng nhất giữa chúng:
grep (mặc định): Sử dụng Biểu thức chính quy cơ bản (Basic Regular Expressions – BRE). Trong BRE, các metacharacters (ký tự có ý nghĩa đặc biệt) như ?, +, |, {}, () mất đi ý nghĩa đặc biệt của chúng và được coi là các ký tự thông thường. Nếu bạn muốn chúng hoạt động như toán tử, bạn phải “thoát” chúng bằng dấu gạch chéo ngược (\).
- Ví dụ: Để tìm các dòng chứa “apple” hoặc “orange”, bạn phải viết:
grep 'apple\|orange' file.txt
egrep (hoặc grep -E): Sử dụng Biểu thức chính quy mở rộng (Extended Regular Expressions – ERE). Trong ERE, các metacharacters nói trên được diễn giải trực tiếp với ý nghĩa đặc biệt của chúng mà không cần dấu thoát. Điều này làm cho cú pháp trở nên sạch sẽ, dễ đọc và gần gũi hơn với các ngôn ngữ lập trình hiện đại.
- Ví dụ: Cùng tác vụ trên, với
egrep bạn chỉ cần viết: egrep 'apple|orange' file.txt
Về hiệu suất: Trong quá khứ, có những quan niệm cho rằng grep nhanh hơn egrep đối với các mẫu đơn giản. Tuy nhiên, với các thuật toán hiện đại được triển khai trong GNU grep ngày nay, sự khác biệt về hiệu suất giữa grep và grep -E (tức egrep) gần như không đáng kể trong hầu hết các trường hợp sử dụng thông thường.

Sự khác biệt giữa egrep và fgrep
Nếu egrep là phiên bản mở rộng của grep về regex, thì fgrep lại đi theo hướng ngược lại: đơn giản hóa tối đa. Lệnh fgrep cũng là một lối tắt cho grep -F.
Điểm khác biệt cốt lõi: fgrep không xử lý biểu thức chính quy
egrep (grep -E): Diễn giải chuỗi mẫu tìm kiếm như một biểu thức chính quy mở rộng. Mọi ký tự đặc biệt như . * [ ] | $ ^ đều có ý nghĩa đặc biệt.fgrep (grep -F): Viết tắt của “Fixed string grep” hoặc “Fast grep”. Nó coi chuỗi mẫu tìm kiếm là một chuỗi cố định (fixed string), hoàn toàn theo nghĩa đen. Mọi ký tự, kể cả . * hay $, đều được tìm kiếm như những ký tự thông thường.
Khi nào nên dùng fgrep?
Bạn nên sử dụng fgrep khi bạn chỉ cần tìm một chuỗi văn bản chính xác và không cần bất kỳ sự linh hoạt nào của regex. Ví dụ, nếu bạn muốn tìm chuỗi user.name* trong một tệp, egrep sẽ hiểu sai ý bạn vì . và * là ký tự đặc biệt. Bạn sẽ phải thoát chúng: egrep 'user\.name\*' file.txt. Nhưng với fgrep, bạn chỉ cần viết:
fgrep 'user.name*' file.txt
Lệnh này sẽ tìm chính xác chuỗi user.name*.
Về hiệu suất: Vì fgrep không cần phải đi qua bộ máy xử lý regex phức tạp, nó thường nhanh hơn đáng kể so với grep và egrep khi tìm kiếm các chuỗi cố định, đặc biệt là khi tìm kiếm trong các tệp rất lớn hoặc tìm nhiều chuỗi cùng lúc (ví dụ: fgrep -f patterns.txt data.txt). Nó sử dụng các thuật toán tìm kiếm chuỗi hiệu quả như Aho-Corasick, giúp tối ưu hóa tốc độ.
Bảng tóm tắt:
| Đặc điểm |
grep (BRE) |
egrep (grep -E) |
fgrep (grep -F) |
| Loại mẫu |
Biểu thức chính quy cơ bản |
Biểu thức chính quy mở rộng |
Chuỗi cố định |
Xử lý ? + | () |
Cần dấu thoát (\? \+ \| \(\)) |
Dùng trực tiếp |
Coi là ký tự thường |
| Trường hợp sử dụng |
Tìm kiếm cơ bản, tương thích ngược |
Tìm kiếm phức tạp, cú pháp dễ đọc |
Tìm chuỗi chính xác, hiệu suất cao |
| Hiệu suất |
Tốt |
Tốt, tương đương grep |
Rất nhanh cho chuỗi cố định |
Các mẹo và lưu ý khi sử dụng lệnh egrep hiệu quả
Biết cú pháp và các ví dụ cơ bản là một chuyện, nhưng để thực sự làm chủ egrep và biến nó thành một công cụ sắc bén trong bộ kỹ năng của bạn, bạn cần biết thêm các mẹo và lưu ý để sử dụng nó một cách hiệu quả nhất. Việc này không chỉ giúp bạn tìm kiếm nhanh hơn mà còn đảm bảo kết quả chính xác và dễ đọc.
Mẹo tăng tốc tìm kiếm với các tham số bổ sung
Ngoài các tham số cơ bản, egrep còn cung cấp nhiều tùy chọn khác giúp bạn tối ưu hóa quá trình làm việc.
1. Sử dụng -r để tìm kiếm đệ quy:
Thay vì phải dùng lệnh find kết hợp với egrep để tìm kiếm trong toàn bộ cây thư mục, bạn có thể sử dụng tùy chọn -r (hoặc -R). Đây là cách nhanh nhất để tìm một chuỗi văn bản khi bạn không chắc nó nằm ở tệp nào.
Ví dụ: Tìm tất cả các tệp trong thư mục /var/log và các thư mục con của nó có chứa từ “Failed”.
egrep -r 'Failed' /var/log
Lệnh này sẽ tự động duyệt qua mọi tệp và thư mục con, hiển thị tên tệp cùng với dòng khớp, tiết kiệm rất nhiều thời gian và công sức. Đây là thao tác thường dùng khi phân tích Linux hoặc các hệ điều hành tương tự như Unix là gì.
2. Luôn dùng --color=auto để làm nổi bật kết quả:
Mắt người rất nhạy với màu sắc. Việc tô màu phần văn bản khớp với mẫu tìm kiếm giúp bạn nhanh chóng xác định thông tin quan trọng trong một biển kết quả trả về. Hầu hết các bản phân phối Linux hiện đại đều đã đặt bí danh cho grep thành grep --color=auto, nhưng việc ghi nhớ và sử dụng nó một cách có chủ đích vẫn rất hữu ích.
egrep --color=auto 'ERROR|CRITICAL' system.log
Kết quả sẽ hiển thị các từ “ERROR” hoặc “CRITICAL” với màu sắc nổi bật, giúp bạn không bỏ sót bất kỳ cảnh báo quan trọng nào.

3. Kết hợp với các lệnh khác qua pipe |:
egrep phát huy sức mạnh tối đa khi được kết hợp với các lệnh khác. Bạn có thể dùng một lệnh để tạo ra luồng dữ liệu, sau đó dùng egrep để lọc luồng dữ liệu đó.
Ví dụ: Liệt kê các tiến trình đang chạy và chỉ hiển thị các tiến trình liên quan đến apache hoặc nginx.
ps aux | egrep 'apache|nginx'
Lệnh này lấy đầu ra của ps aux và chuyển nó làm đầu vào cho egrep, giúp bạn lọc thông tin ngay lập tức mà không cần lưu vào tệp tạm.
Lưu ý khi sử dụng ký tự đặc biệt trong biểu thức chính quy
Biểu thức chính quy rất mạnh mẽ nhưng cũng dễ gây ra lỗi nếu bạn không cẩn thận với các ký tự đặc biệt. Đây là những “cái bẫy” phổ biến nhất.
1. Cách escape (thoát) ký tự đặc biệt:
Vấn đề lớn nhất là khi bạn muốn tìm một ký tự mà nó lại có ý nghĩa đặc biệt trong regex. Ví dụ, bạn muốn tìm một dấu chấm (.) theo nghĩa đen, nhưng . trong regex lại có nghĩa là “một ký tự bất kỳ”. Để giải quyết vấn đề này, bạn cần “escape” nó bằng dấu gạch chéo ngược (\).
- Tìm địa chỉ IP
127.0.0.1:
- Sai:
egrep '127.0.0.1' file.txt (sẽ khớp với 127.0.0.1, 127a0b0c1, v.v.)
- Đúng:
egrep '127\.0\.0\.1' file.txt
- Tìm chuỗi
file*.txt:
- Sai:
egrep 'file*.txt' file.txt (* có nghĩa là 0 hoặc nhiều chữ ‘e’)
- Đúng:
egrep 'file\*\.txt' file.txt
2. Tránh các lỗi phổ biến trong biểu thức chính quy:
- Tham lam (Greedy Matching): Các bộ định lượng như
* và + có tính “tham lam”, nghĩa là chúng sẽ cố gắng khớp với chuỗi dài nhất có thể. Ví dụ, với chuỗi <p>text</p><p>more</p>, regex <p>.*</p> sẽ khớp toàn bộ chuỗi từ <p> đầu tiên đến </p> cuối cùng. Để khớp với từng cặp thẻ, bạn có thể cần các kỹ thuật regex nâng cao hơn (như non-greedy .*?, thường có trong grep -P).
- Nhầm lẫn giữa
egrep và grep cơ bản: Một lỗi phổ biến là sử dụng cú pháp ERE (như |, +) trong lệnh grep cơ bản mà quên tùy chọn -E hoặc quên dấu thoát. Điều này sẽ không trả về kết quả như mong đợi. Hãy tạo thói quen dùng egrep hoặc grep -E khi bạn có ý định sử dụng regex mở rộng.
- Sự phức tạp không cần thiết: Đôi khi, một biểu thức chính quy quá phức tạp sẽ khó đọc, khó bảo trì và chạy chậm. Hãy tự hỏi liệu có cách nào đơn giản hơn để đạt được cùng một kết quả không, ví dụ như kết hợp nhiều lệnh
egrep đơn giản với nhau qua pipe.
Các vấn đề thường gặp và cách khắc phục
Mặc dù egrep là một công cụ mạnh mẽ, nhưng trong quá trình sử dụng, bạn có thể sẽ gặp phải một số vấn đề phổ biến. Nhận biết được nguyên nhân và biết cách khắc phục sẽ giúp bạn tiết kiệm thời gian và tránh được những cơn đau đầu không đáng có. Dưới đây là hai trong số những sự cố thường gặp nhất và cách giải quyết chúng.
Lỗi không tìm thấy kết quả do cú pháp regex sai
Đây là vấn đề phổ biến nhất, đặc biệt với những người mới làm quen với biểu thức chính quy. Bạn chắc chắn rằng dữ liệu tồn tại trong tệp, nhưng egrep lại không trả về kết quả nào. Nguyên nhân gần như luôn nằm ở cú pháp regex của bạn.
Nguyên nhân:
- Quên escape ký tự đặc biệt: Như đã đề cập ở phần trước, nếu bạn muốn tìm một chuỗi chứa
. * [ ( $ theo nghĩa đen, bạn phải thoát chúng bằng \. Nếu không, egrep sẽ hiểu chúng theo ý nghĩa đặc biệt, dẫn đến việc mẫu không khớp.
- Sử dụng sai bộ định lượng (quantifier): Nhầm lẫn giữa
* (0 hoặc nhiều lần), + (1 hoặc nhiều lần), và ? (0 hoặc 1 lần) có thể dẫn đến kết quả sai. Ví dụ, egrep 'ab*c' sẽ khớp với “ac”, trong khi egrep 'ab+c' thì không.
- Lỗi logic trong nhóm hoặc lựa chọn: Khi sử dụng
() và |, thứ tự và cách nhóm có thể ảnh hưởng lớn đến kết quả. Ví dụ: egrep 'cat|dogfood' sẽ tìm “cat” hoặc “dogfood”, nhưng nếu bạn muốn tìm “catfood” hoặc “dogfood”, cú pháp đúng phải là egrep '(cat|dog)food'.
Cách kiểm tra và sửa lỗi:
- Bắt đầu đơn giản: Thay vì viết một biểu thức phức tạp ngay từ đầu, hãy bắt đầu với một phần nhỏ và đơn giản nhất của nó. Kiểm tra xem nó có hoạt động không, sau đó từ từ thêm các thành phần khác vào.
- Sử dụng các công cụ gỡ lỗi regex trực tuyến: Các trang web như regex101.com hoặc regexr.com là những người bạn vô giá. Bạn có thể dán biểu thức chính quy và văn bản mẫu của mình vào đó. Chúng sẽ phân tích cú pháp, giải thích từng phần của regex và hiển thị các kết quả khớp một cách trực quan. Đây là cách nhanh nhất để tìm ra lỗi sai.

- Kiểm tra lại việc thoát ký tự: Rà soát lại biểu thức của bạn và tự hỏi: “Có ký tự nào ở đây tôi muốn tìm theo nghĩa đen nhưng nó lại là một metacharacter không?”. Nếu có, hãy thêm
\ vào trước nó.
- Sử dụng tùy chọn
--color=auto: Đôi khi, lệnh vẫn trả về kết quả nhưng không phải là cái bạn mong đợi. Tùy chọn tô màu sẽ giúp bạn thấy chính xác phần nào của dòng đã khớp với mẫu của bạn, từ đó giúp bạn nhận ra lỗi logic.
Quyền truy cập và lỗi đọc tập tin
Một vấn đề khác không liên quan đến regex nhưng cũng rất thường gặp là egrep báo lỗi về quyền truy cập. Bạn có thể thấy các thông báo như “Permission denied” (Quyền truy cập bị từ chối) hoặc “No such file or directory” (Không có tệp hoặc thư mục như vậy).
Nguyên nhân:
- Không đủ quyền đọc: Người dùng bạn đang sử dụng không có quyền đọc tệp hoặc thư mục mà bạn đang cố gắng tìm kiếm. Điều này đặc biệt phổ biến khi bạn cố gắng quét các thư mục hệ thống như
/var/log hay /etc mà không dùng sudo.
- Sai đường dẫn hoặc tên tệp: Một lỗi đơn giản nhưng dễ mắc phải là gõ sai tên tệp hoặc đường dẫn đến tệp.
- Tệp là một liên kết tượng trưng bị hỏng (broken symbolic link): Nếu bạn cố gắng chạy
egrep trên một symlink trỏ đến một tệp không còn tồn tại, bạn cũng sẽ gặp lỗi.
Cách khắc phục:
- Kiểm tra quyền bằng
ls -l: Trước khi chạy egrep, hãy sử dụng lệnh ls -l ten_tep để kiểm tra quyền của tệp. Bạn cần có quyền đọc (r) trên tệp đó. Nếu không có, bạn sẽ cần thay đổi quyền (nếu bạn là chủ sở hữu) hoặc sử dụng một người dùng có quyền cao hơn.
- Sử dụng
sudo: Nếu bạn cần tìm kiếm trong các tệp hệ thống mà chỉ người dùng root mới có quyền đọc, hãy chạy lệnh egrep với sudo ở đầu.
sudo egrep -r 'critical error' /var/log/
- Sử dụng tùy chọn
-s (no-messages): Khi bạn chạy tìm kiếm đệ quy (-r) trên một thư mục lớn có nhiều tệp mà bạn không có quyền truy cập, màn hình của bạn sẽ tràn ngập thông báo “Permission denied”. Để ẩn những thông báo lỗi này và chỉ tập trung vào kết quả tìm được, hãy sử dụng tùy chọn -s.
sudo egrep -rs 'config_error' /etc/
- Kiểm tra lại đường dẫn: Hãy chắc chắn rằng bạn đã gõ đúng đường dẫn và tên tệp. Sử dụng tính năng tự động hoàn thành bằng phím Tab trong terminal để giảm thiểu sai sót.
Những thực hành tốt nhất khi sử dụng lệnh egrep
Để trở thành một người dùng egrep thành thạo và chuyên nghiệp, không chỉ cần biết cách sử dụng lệnh mà còn phải biết cách sử dụng nó một cách thông minh, hiệu quả và có trách nhiệm. Áp dụng những thực hành tốt nhất sau đây sẽ giúp bạn tối ưu hóa hiệu suất, đảm bảo kết quả chính xác và tránh gây ảnh hưởng tiêu cực đến hệ thống.
1. Luôn test biểu thức regex trên tập dữ liệu nhỏ trước
Đây là quy tắc vàng. Trước khi bạn chạy một biểu thức chính quy phức tạp trên một tệp log dung lượng vài gigabyte hoặc trên toàn bộ cây thư mục hệ thống, hãy thử nó trên một mẫu dữ liệu nhỏ hơn. Bạn có thể tạo một tệp tin mẫu chỉ với vài dòng đại diện hoặc sử dụng lệnh head để lấy 100 dòng đầu tiên của tệp lớn và chuyển nó qua pipe cho egrep.
head -n 100 large_log_file.log | egrep 'your_complex_regex'
Việc này giúp bạn xác nhận rằng regex hoạt động đúng như mong đợi và bắt được các lỗi logic mà không phải chờ đợi hàng phút (hoặc hàng giờ) để lệnh chạy xong trên toàn bộ dữ liệu. Nó cũng giúp ngăn chặn các regex “thảm họa” có thể tiêu tốn quá nhiều CPU và bộ nhớ. Bạn có thể tham khảo thêm cách cài đặt và sử dụng Linux Lite để học hỏi về các môi trường nhẹ giúp chạy lệnh nhanh hơn.
2. Sử dụng các tùy chọn để tối ưu hiệu suất và hiển thị kết quả rõ ràng
Đừng chỉ chạy egrep một cách trần trụi. Hãy tận dụng các tùy chọn của nó để làm cho cuộc sống của bạn dễ dàng hơn.
--color=auto: Luôn sử dụng để làm nổi bật kết quả. Điều này giúp mắt bạn quét thông tin nhanh hơn rất nhiều.-n: Hiển thị số dòng để bạn dễ dàng định vị kết quả trong tệp gốc.-l: Khi bạn chỉ cần biết tệp nào chứa mẫu, không cần biết nội dung cụ thể, -l sẽ chỉ in ra tên tệp, giúp đầu ra gọn gàng hơn nhiều.-F (tương đương fgrep): Nếu bạn chỉ đang tìm một chuỗi cố định, hãy chuyển sang dùng grep -F. Việc này sẽ tăng tốc độ tìm kiếm một cách đáng kể vì nó bỏ qua bộ máy xử lý regex.
3. Tránh dùng egrep cho tập dữ liệu quá lớn mà không lọc bước đầu
Khi làm việc với các tệp siêu lớn (hàng chục GB trở lên), việc chạy egrep trực tiếp có thể gây áp lực lớn lên hệ thống, đặc biệt là I/O đĩa. Nếu có thể, hãy lọc bớt dữ liệu trước. Ví dụ, nếu bạn chỉ quan tâm đến các log trong một khoảng thời gian cụ thể, bạn có thể dùng một lệnh khác (như awk hoặc một grep đơn giản hơn) để trích xuất khoảng thời gian đó trước, sau đó mới dùng egrep với regex phức tạp trên tập dữ liệu đã được thu nhỏ.
grep '2023-10-27' huge_log.log | egrep 'complex_pattern_here'
Cách tiếp cận này hiệu quả hơn nhiều vì bước lọc đầu tiên (với grep chuỗi cố định) rất nhanh, và egrep chỉ phải làm việc trên một phần nhỏ dữ liệu.
4. Không lạm dụng regex quá phức tạp gây chậm hệ thống
Biểu thức chính quy rất mạnh mẽ, nhưng “quyền lực lớn đi kèm với trách nhiệm lớn”. Một regex được viết tồi, đặc biệt là những regex sử dụng nhiều backtracking (quay lui), có thể gây ra tình trạng “ReDoS” (Regular Expression Denial of Service), làm cho egrep tiêu tốn 100% CPU và chạy cực kỳ chậm.
- Giữ cho regex đơn giản: Hãy tự hỏi xem có cách nào để chia nhỏ một regex phức tạp thành nhiều bước đơn giản hơn không. Đôi khi, việc sử dụng hai hoặc ba lệnh
egrep nối tiếp nhau qua pipe lại nhanh hơn và dễ hiểu hơn một regex “quái vật” duy nhất.
- Tránh các nhóm lồng nhau với các bộ định lượng tham lam: Các mẫu như
(a+)+ hoặc (a*)* có thể cực kỳ chậm trên một số loại văn bản. Hãy cố gắng viết regex một cách cụ thể hơn.
- Cân nhắc các công cụ khác: Đối với các tác vụ phân tích và xử lý văn bản có cấu trúc phức tạp (như phân tích cú pháp JSON hoặc XML),
egrep có thể không phải là công cụ tốt nhất. Hãy cân nhắc sử dụng các công cụ chuyên dụng như Kernel Linux hoặc KVM là gì và các công cụ xử lý theo cột như awk, chúng thường hiệu quả và an toàn hơn.
Kết luận
Qua bài viết này, chúng ta đã cùng nhau thực hiện một hành trình chi tiết để khám phá và làm chủ lệnh egrep trong Linux. Bắt đầu từ những khái niệm cơ bản về cú pháp, chúng ta đã đi sâu vào sức mạnh thực sự của egrep thông qua việc ứng dụng các biểu thức chính quy mở rộng (ERE). Các ví dụ thực tiễn từ việc phân tích tệp log đến lọc danh sách người dùng đã cho thấy egrep không chỉ là một công cụ tìm kiếm, mà là một trợ thủ đắc lực giúp chúng ta trích xuất thông tin một cách chính xác và hiệu quả từ biển dữ liệu văn bản.
Vai trò của egrep trong hộp công cụ của bất kỳ ai làm việc với Linux là không thể phủ nhận. Nó là cầu nối giữa sự đơn giản của fgrep và sự phức tạp đôi khi không cần thiết của grep cơ bản khi phải thoát nhiều ký tự. Với cú pháp ERE gọn gàng và dễ đọc, egrep (hay grep -E) đã trở thành tiêu chuẩn cho các tác vụ tìm kiếm có độ phức tạp vừa phải, giúp tăng năng suất và giảm thiểu lỗi.
Lý thuyết chỉ là bước khởi đầu. Cách tốt nhất để thực sự thành thạo egrep là thông qua thực hành. Tôi khuyến khích bạn hãy mở terminal lên, lấy một tệp văn bản bất kỳ và bắt đầu thử nghiệm với các ví dụ trong bài viết. Hãy thử thay đổi các biểu thức chính quy, kết hợp các tùy chọn khác nhau và quan sát kết quả. Đừng ngại mắc lỗi, vì mỗi lỗi sẽ là một bài học quý giá giúp bạn hiểu sâu hơn về cách công cụ này hoạt động.
Hành trình học tập trong thế giới Linux là vô tận. Sau khi đã tự tin với egrep, bạn có thể tìm hiểu sâu hơn về các lệnh grep khác, khám phá các tính năng regex nâng cao hơn (như PCRE với grep -P), hoặc học thêm các công cụ xử lý văn bản mạnh mẽ khác như sed và awk. Chúc bạn thành công trên con đường trở thành một chuyên gia Linux!

